如果你来到这个页面,说明你已经对Java中的网页爬虫有一定了解,并且希望深入了解更多细节。太好了,你走对了方向!在本指南中,我们将以简单易懂的方式解释Java中网页爬虫的基础知识,并展示如何从真实网站中提取数据,包括静态和动态元素。这里汇集了你快速便捷开始收集所需信息的一切内容。那么,开始吧!
网页爬虫就像是派遣一个数字助手从网站上为你收集信息。想象一下,你正在浏览互联网,复制文本或收集图片——但不是手动操作,而是通过程序来完成,速度更快,效率更高。通过网页爬虫,你可以提取有用的数据,如价格、评论或联系信息,并将其保存为适合你需求的格式,例如电子表格或数据库。
它是一个强大的工具,广泛应用于市场研究、竞争分析和数据聚合等领域。无论你是初学者还是有经验的开发者,网页爬虫都能简化你从网络收集和组织信息的方式。
Java是进行网页爬虫的绝佳选择,原因如下:
可靠性与性能:Java以其强大的性能和处理复杂任务的能力而闻名。无论是抓取小型网站还是大型应用程序,Java都能提供所需的稳定性,确保一致的结果。
全面的库支持:借助像Jsoup这样的HTML解析库和Selenium这样的动态网页交互库,Java为网页爬虫提供了所需的所有工具。
跨平台兼容性:一次编写代码,随处运行。Java的跨平台特性意味着你可以在一个操作系统上开发爬虫脚本,然后轻松地将其部署到另一个操作系统上。
多线程与可扩展性:Java的多线程能力使得同时抓取多个页面成为可能,从而节省时间并提高效率。
社区与支持:Java的广泛使用意味着有一个庞大的开发者社区可以提供支持、分享解决方案并提供建议。
选择Java,你将选用一种多功能、强大且有良好支持的编程语言——非常适合处理任何规模的网页爬虫项目!
在Java中成功进行网页爬虫时,有几个强大的工具和库可以帮助你高效地从网页收集数据。让我们来看看一些流行的选项:
Jsoup
Jsoup是Java中最受欢迎的HTML解析库之一。它提供了一个简单直观的API,用于从HTML文档中提取数据。如果你需要快速从网页中获取信息并处理DOM(文档对象模型),Jsoup是一个理想的选择。
优点:
- 易于使用。
- 支持解析HTML并使用CSS选择器。
- 允许清理HTML中的杂乱内容和不必要的标签。
- 提供简单的API来获取元素及其属性。
Apache HttpClient
Apache HttpClient是一个帮助你处理HTTP请求的库,提供了像处理cookie、头信息和认证等功能。如果你只是需要发送请求并从网站获取数据(不涉及JavaScript处理),这是一个很好的选择。
优点:
- 配置HTTP请求的灵活性。
- 能够处理各种HTTP方法(GET、POST、PUT等)。
- 可以与其他数据处理库良好集成。
HtmlUnit
HtmlUnit是一个“无头”浏览器,允许在不启动真实浏览器的情况下与网页进行交互。它非常适合测试和抓取那些不需要视觉渲染的站点。
优点:
- 轻量级(无需图形界面)。
- 适用于抓取动态页面(支持JavaScript)。
- 性能优越。
Selenium WebDriver
Selenium是一个流行的浏览器自动化工具。它非常适合抓取那些通过JavaScript加载数据的动态网页。使用Selenium,你可以控制浏览器,模拟用户操作(点击、输入),并提取所需的信息。
优点:
- 适用于动态网站(数据通过JavaScript加载的页面)。
- 支持多种浏览器(Chrome、Firefox、Safari等)。
- 能够模拟真实用户行为。
这些库和工具提供了强大的功能,用于处理网页和收集数据。根据你的任务,你可以选择其中一个或多个。例如,对于简单的HTML解析,Jsoup是一个很好的选择,而对于动态页面,Selenium或HtmlUnit则更为合适。你的选择取决于项目的复杂性以及目标网站上数据加载的方式。
以下是适用于Java网页爬虫开发的最佳编辑器和IDE概览,以及每个工具的优缺点:
- IntelliJ IDEA
IntelliJ IDEA是最受欢迎且功能强大的Java开发IDE之一。它提供了许多对于网页爬虫开发非常有用的功能。
优点:
- IntelliJ理解代码上下文,提供准确的建议和修复。
- 支持所有流行的构建系统(Maven、Gradle)和框架。
- 强大且易于使用的调试工具。
- 提供与数据库、Docker、测试等相关的插件。
- 界面直观、易用。
缺点:
- 对系统资源要求较高,尤其是在老旧或性能较差的计算机上。
- 虽然有免费的社区版,但一些功能仅在付费的Ultimate版中提供。
细节: 适合处理复杂项目或团队开发的开发者,因为它提供了强大的重构和协作工具。
- Eclipse
Eclipse是最古老且最知名的Java IDE之一。它为Java开发和其他语言提供了丰富的功能。
优点:
- Eclipse是免费的IDE,并且可以进行修改。
- 拥有大量的插件和扩展。
- 适合开发大型应用程序。
缺点:
- 相比于IntelliJ IDEA,Eclipse的界面不那么用户友好。
- 某些操作可能会较慢,尤其是在使用大量插件或处理大型项目时。
细节: Eclipse更适合需要更多定制和扩展的经验丰富的开发者。新手可能会觉得界面比较复杂。
- JDeveloper
JDeveloper是Oracle推出的IDE,专为Java EE(企业版)开发设计。
优点:
- 与Oracle产品完全集成,是Java EE开发的理想选择。
- 包括与数据库、Web服务以及许多其他技术相关的工具。
缺点:
- 与Eclipse或IntelliJ IDEA相比,JDeveloper的用户社区较小。
- 对于在Java EE生态系统外工作的开发者,可能不太方便。
细节: 最适合用于大型Java EE项目,尤其是当你在使用Oracle产品时。
- Apache NetBeans
Apache NetBeans是NetBeans的改进版,由Apache软件基金会支持。
优点:
- 与旧版本不同,这个版本得到了积极支持和开发。
- 完全免费且开源。
缺点:
- 不如IntelliJ IDEA或Eclipse流行:与其他IDE相比,它的资源和文档较少。
- 可能较慢:有时速度不如其他工具。
细节: 对于那些寻找免费的开源Java开发IDE,但不需要最大性能或大量插件的开发者来说,它是一个很好的选择。
- Visual Studio Code (VS Code)
VS Code是一个轻量级的编辑器,拥有众多插件,适用于多种编程语言,包括Java。
优点:
- 运行速度快,资源消耗较少。
- 提供Java插件,支持自动补全、调试等功能。
- 用户友好的界面:非常可定制,易于使用。
缺点:
- 不是一个完整的IDE:与IntelliJ IDEA或Eclipse相比,VS Code不提供IDE的所有功能,如强大的重构功能或大型项目管理。
- 可能没有处理大规模Java项目所需的所有功能。
细节: 非常适合小型或中型项目和快速原型开发。对于那些重视简洁性和速度的开发者来说,它是一个极好的选择。
现在我们已经熟悉了Java中进行网页爬虫的主要和最流行的工具,接下来让我们选择最适合我们需求的工具,并开始准备网页爬虫的工作。对于本示例,我们将选择IntelliJ IDEA和Jsoup。
1. 安装 IntelliJ IDEA
- 访问IntelliJ IDEA官网。
- 下载并安装Community Edition(免费版)或Ultimate Edition(付费版)。
2. 创建新项目
- 打开 IntelliJ IDEA,选择New Project。
- 选择Java作为项目类型。
- 确保Project SDK设置为合适的Java版本(Java 8或更高版本)。
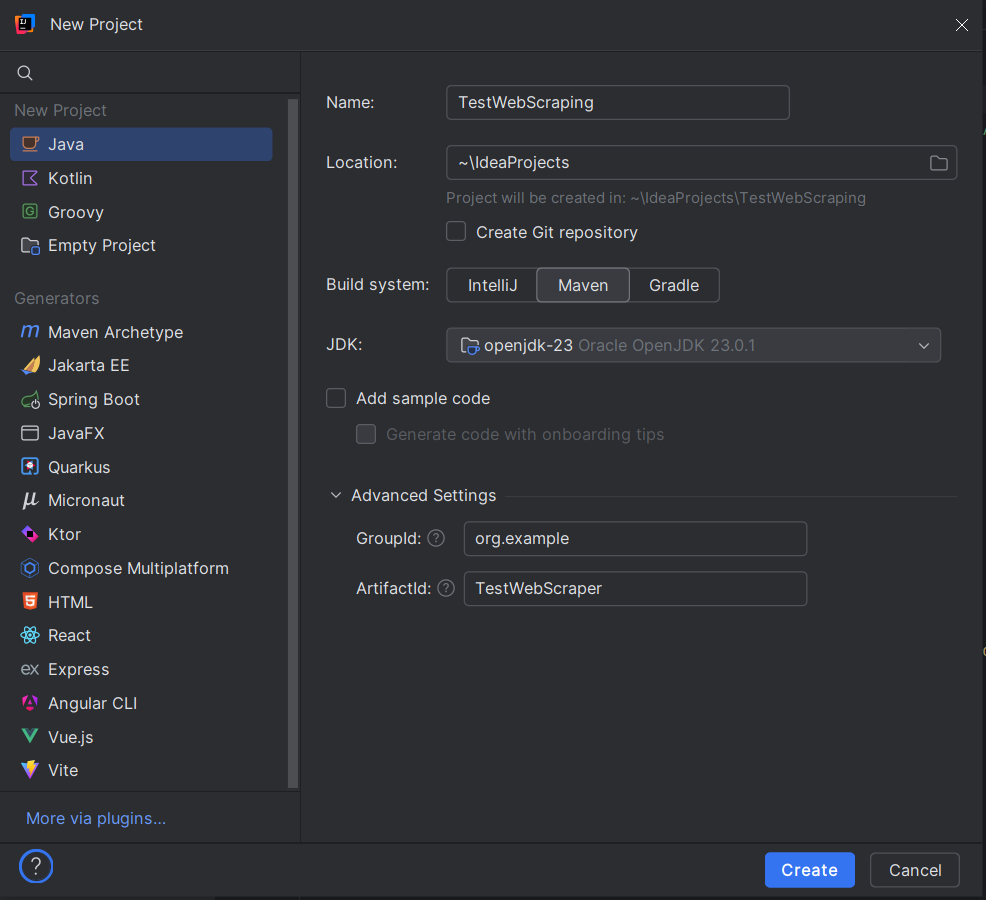
3. 配置项目名称和位置
- 为你的项目输入名称(例如,TestWebScraping)。
- 选择项目文件的存放位置。
- 在创建项目时,选择Maven。在弹出的对话框中:
- GroupId:为你的项目设置一个唯一标识符,例如 org.example。
- ArtifactId:这是你项目的名称,例如 TestWebScraper。
- 点击Create。
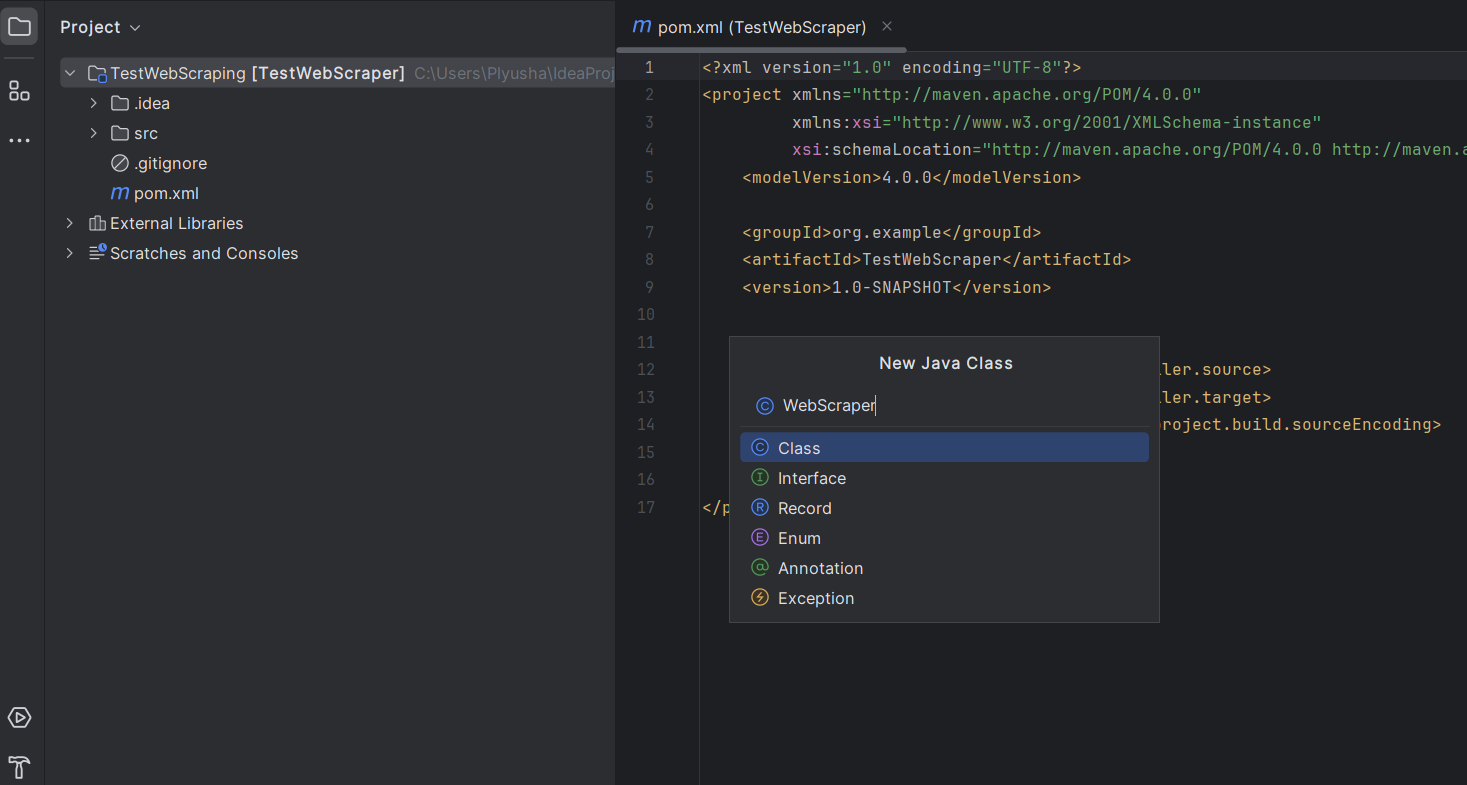
4. 设置项目结构
创建完项目后,IntelliJ IDEA会自动打开项目结构。
- 在这个包内创建一个Java类:右键点击你新创建的包,选择New -> Java Class。
- 为类命名为WebScraper(或你喜欢的其他名字)。
5. 添加依赖
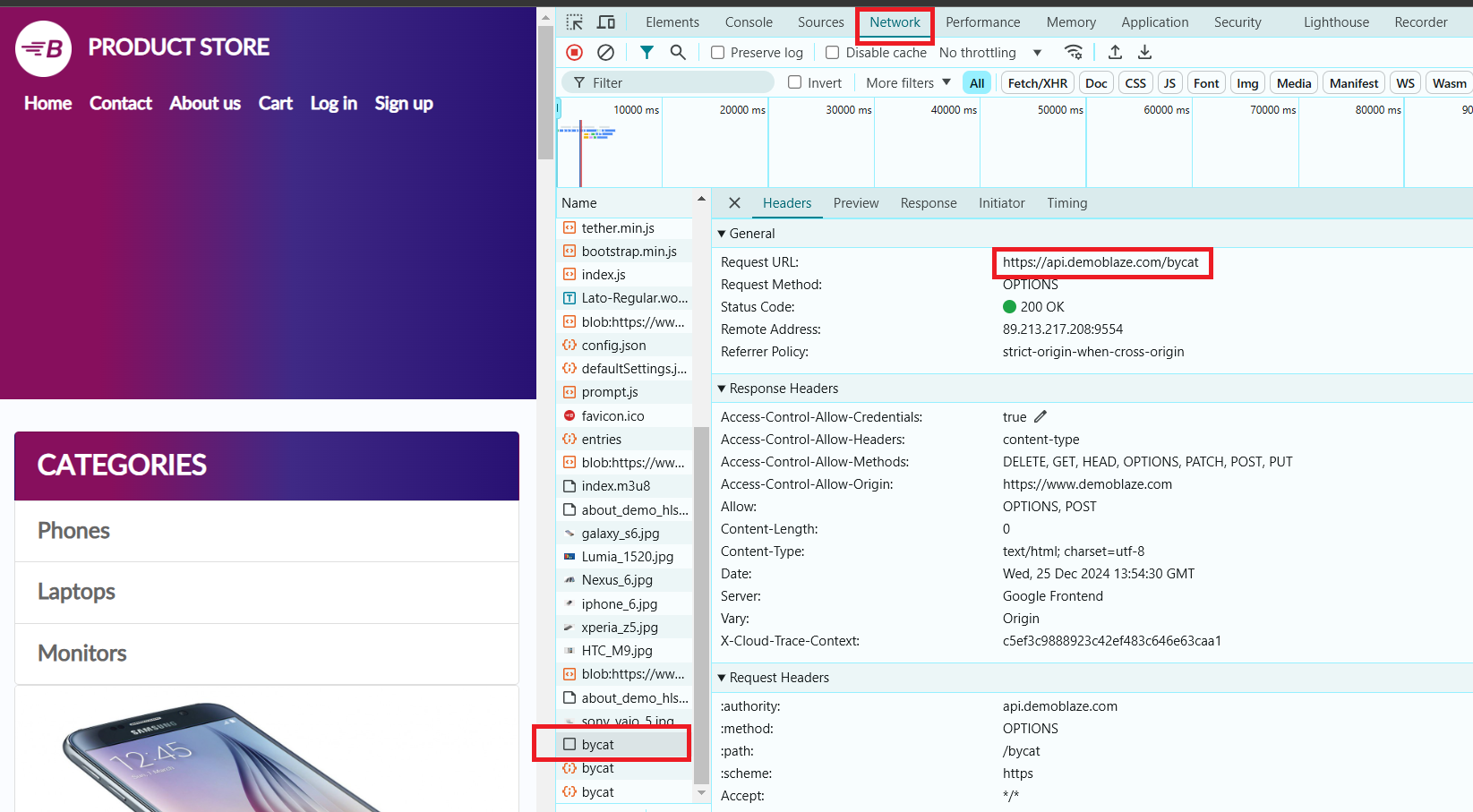
在本示例中,我们将使用网站 https://www.demoblaze.com/#。由于该站点使用JavaScript渲染内容,Jsoup无法直接获取数据。但是,网站提供了一个可以直接调用的API来获取产品信息。
在分析Demoblaze网站时,我们发现产品数据是通过动态请求加载的,而不是通过静态HTML呈现的。https://api.demoblaze.com/bycat 是一个内部API,用于获取网站上的产品数据。
为了在我们的项目中使用这个API,我们需要添加相关依赖。这里,我们将使用HttpClient来进行API请求。
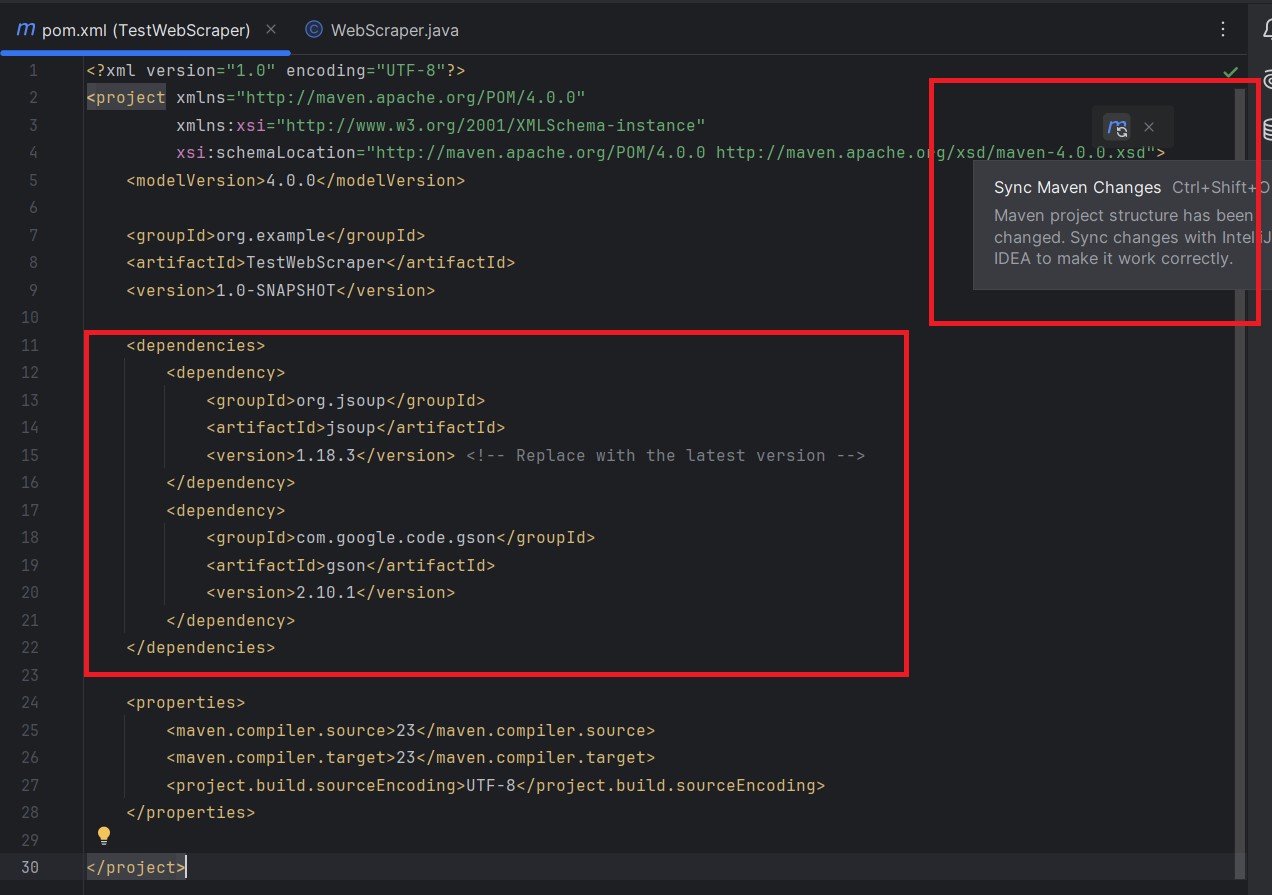
然后,你需要将Jsoup和Gson库添加到你的项目中。
在pom.xml文件中,将以下Jsoup和Gson依赖项添加到<dependencies>部分:
<dependencies>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.18.3</version> <!-- Replace with the latest version -->
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.10.1</version>
</dependency>
</dependencies>不要忘记同步Maven的更改:
让我们尝试从选定页面中提取每个产品的名称和价格。但首先,让我们检查页面上的元素。
- 打开开发者工具(在大多数浏览器中按F12键)。
- 选择“手机”类别。在“网络”选项卡中,会出现一个API请求,我们将使用它来提取所需的数据。
这个API接受一个POST请求,JSON主体中指定产品类别等信息,并返回一个包含“Items”键的JSON对象。每个项目都有像“title”和“price”这样的属性。
现在,让我们开始编写我们的网页爬虫代码吧!
import com.google.gson.Gson;
import com.google.gson.JsonArray;
import com.google.gson.JsonObject;
import java.io.OutputStream;
import java.net.HttpURLConnection;
import java.net.URI;
import java.net.URL;
import java.nio.charset.StandardCharsets;
import java.util.Scanner;- 主方法:
public class WebScraper {
public static void main(String[] args) {
try {
// API URL
String apiUrl = "https://api.demoblaze.com/bycat";
// 产品类别的请求参数:
String category = "phone"; // 可以更改为“laptop”(笔记本电脑)、“monitor”(显示器)等。
// 从API获取响应:
String jsonResponse = fetchApiResponse(apiUrl, category);
// 解析JSON响应:
Gson gson = new Gson();
JsonObject responseObject = gson.fromJson(jsonResponse, JsonObject.class);
JsonArray items = responseObject.getAsJsonArray("Items");
// 输出产品信息:
for (int i = 0; i < items.size(); i++) {
JsonObject item = items.get(i).getAsJsonObject();
String title = item.get("title").getAsString();
String price = item.get("price").getAsString();
System.out.println("Product: " + title);
System.out.println("Price: $" + price);
System.out.println("-----------------------");
}
} catch (Exception e) {
System.err.println("An error occurred: " + e.getMessage());
}
}
}API URL:变量apiUrl保存API的端点,它根据指定的类别返回产品详细信息。
类别:变量category用于指定产品类别,以过滤API查询(默认是“phones”,但可以更改为“laptops”、“monitors”等)。
获取API响应:调用方法fetchApiResponse()来发送POST请求到API,并将响应作为JSON字符串返回。
解析JSON响应:
- 使用Gson解析JSON响应,将其转换为JsonObject。
- 预计JSON响应在“Items”键下包含一个产品数组。
遍历项:for循环遍历产品(项)的JSON数组,提取每个项的标题和价格,并将其打印到控制台。
4. 方法:fetchApiResponse
private static String fetchApiResponse(String apiUrl, String category) throws Exception {
URI uri = new URI(apiUrl);
URL url = uri.toURL();
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("POST");
connection.setRequestProperty("Content-Type", "application/json");
connection.setDoOutput(true);
// 请求体
String jsonInputString = "{\"cat\":\"" + category + "\"}";
try (OutputStream os = connection.getOutputStream()) {
byte[] input = jsonInputString.getBytes(StandardCharsets.UTF_8);
os.write(input, 0, input.length);
}
// 读取响应
StringBuilder response = new StringBuilder();
try (Scanner scanner = new Scanner(connection.getInputStream(), StandardCharsets.UTF_8)) {
while (scanner.hasNextLine()) {
response.append(scanner.nextLine());
}
}
return response.toString();
}每部分的解释:
URI和URL创建:
URI和URL对象是从提供的API URL(apiUrl)创建的。这允许程序与服务器建立连接。
打开HTTP连接:
使用HttpURLConnection打开与API的连接。setRequestMethod("POST")方法指定这是一个POST请求。
setRequestProperty("Content-Type", "application/json")确保请求的内容类型是JSON。
setDoOutput(true)启用写入请求体(即JSON数据)。
请求体:
请求体作为一个JSON字符串构建:{"cat":"<category>"},其中<category>是产品类别(例如“phone”)。
getOutputStream()用于将JSON字符串发送到服务器。
读取响应:
通过Scanner从连接的输入流中读取API响应。
响应被附加到StringBuilder对象,并作为字符串返回。
这是完整的代码:
import com.google.gson.Gson;
import com.google.gson.JsonArray;
import com.google.gson.JsonObject;
import java.io.OutputStream;
import java.net.HttpURLConnection;
import java.net.URI;
import java.net.URL;
import java.nio.charset.StandardCharsets;
import java.util.Scanner;
public class WebScraper {
public static void main(String[] args) {
try {
// API URL
String apiUrl = "https://api.demoblaze.com/bycat";
// 产品类别的请求参数
String category = "phone"; // Can be changed to "laptop", "monitor", etc.
// 从API获取响应
String jsonResponse = fetchApiResponse(apiUrl, category);
// 解析JSON响应
Gson gson = new Gson();
JsonObject responseObject = gson.fromJson(jsonResponse, JsonObject.class);
JsonArray items = responseObject.getAsJsonArray("Items");
// 输出产品信息
for (int i = 0; i < items.size(); i++) {
JsonObject item = items.get(i).getAsJsonObject();
String title = item.get("title").getAsString();
String price = item.get("price").getAsString();
System.out.println("Product: " + title);
System.out.println("Price: $" + price);
System.out.println("-----------------------");
}
} catch (Exception e) {
System.err.println("An error occurred: " + e.getMessage());
}
}
}
private static String fetchApiResponse(String apiUrl, String category) throws Exception {
URI uri = new URI(apiUrl);
URL url = uri.toURL();
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("POST");
connection.setRequestProperty("Content-Type", "application/json");
connection.setDoOutput(true);
// 请求体
String jsonInputString = "{\"cat\":\"" + category + "\"}";
try (OutputStream os = connection.getOutputStream()) {
byte[] input = jsonInputString.getBytes(StandardCharsets.UTF_8);
os.write(input, 0, input.length);
}
// 读取响应
StringBuilder response = new StringBuilder();
try (Scanner scanner = new Scanner(connection.getInputStream(), StandardCharsets.UTF_8)) {
while (scanner.hasNextLine()) {
response.append(scanner.nextLine());
}
}
return response.toString();
}
}输出:
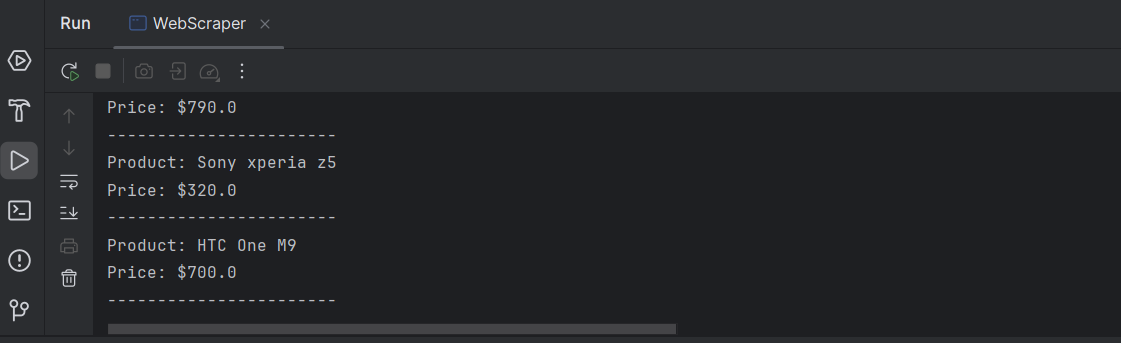
恭喜!您已经成功提取了页面上每个产品的必要信息。
这是如何使用Java从网站Books to Scrape抓取数据的示例。我们将使用HttpURLConnection发送请求,并使用Jsoup解析HTML。
GET请求:
Jsoup.connect(url).get()方法向指定的URL(https://books.toscrape.com/)发送HTTP GET请求,并将页面内容作为Document返回。
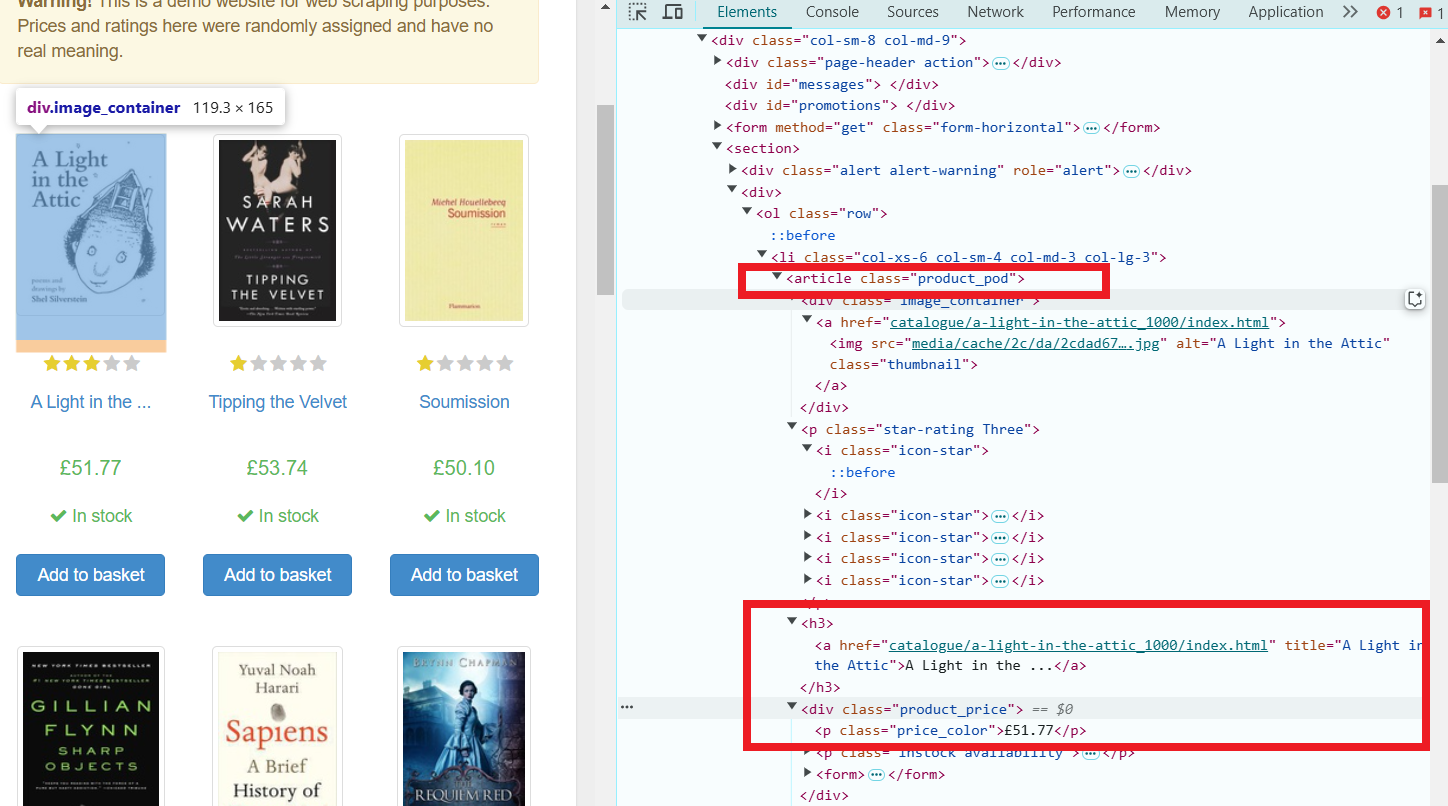
选择元素:
- doc.select(".product_pod")选择所有具有product_pod类的元素,这些元素表示单独的书籍。
- book.select("h3 a").attr("title")提取每本书的标题,该标题存储在h3元素内的a标签的title属性中。
- book.select(".price_color").text()从具有price_color类的元素中获取文本内容(价格)。
显示数据:
程序然后循环遍历每本书,提取并打印其标题和价格。
代码示例:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
public class BookScraper {
public static void main(String[] args) {
try {
// 网站的URL
String url = "https://books.toscrape.com/";
// 发送GET请求以获取页面
Document doc = Jsoup.connect(url).get();
// 选择页面上的所有书籍项目
Elements books = doc.select(".product_pod");
// 遍历每个书籍元素并提取标题和价格
for (Element book : books) {
String title = book.select("h3 a").attr("title");
String price = book.select(".price_color").text();
System.out.println("Title: " + title);
System.out.println("Price: " + price);
System.out.println("---------------------------");
}
} catch (IOException e) {
e.printStackTrace();
}
}
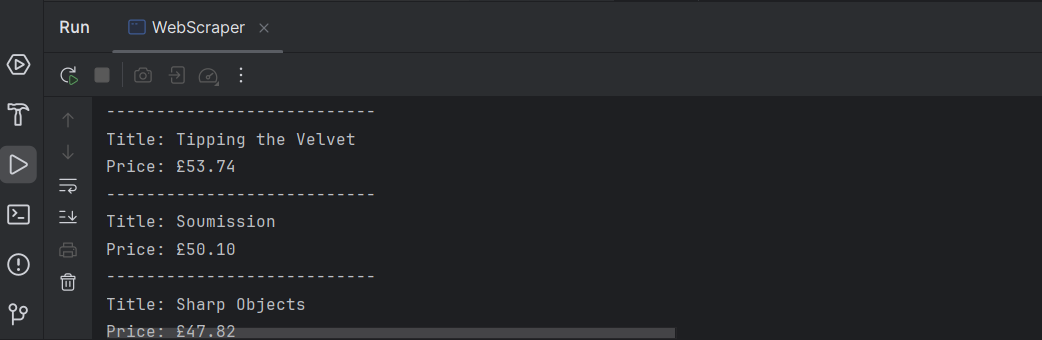
}完成!现在我们已经获得了页面上所有书籍的标题和价格列表。
网页抓取动态网站涉及与通过JavaScript加载内容的页面进行交互,通常使用AJAX(异步JavaScript和XML)。与静态网站不同,静态网站在页面加载时提供所有内容,而动态网站在页面加载后动态获取和显示内容,这意味着在抓取时需要处理这一额外的复杂性。对于Java中的动态网页抓取,通常使用像Selenium或Playwright这样的库,因为它们可以自动化浏览器并与JavaScript驱动的页面进行交互。
要识别一个动态网站,可以使用浏览器中的 DevTools,它允许你检查网络请求和响应,实时查看动态内容的加载,并分析数据是如何被获取的。
- 打开DevTools:
右键点击页面上的任意位置,选择 检查,或按 Ctrl+Shift+I(Windows/Linux)或 Cmd+Option+I(Mac)。
- 进入网络标签:
点击开发者工具窗口中的 Network(网络)标签。这将显示页面加载时以及加载后发生的所有网络活动。
- 重新加载页面:
刷新网页。在页面重新加载时观察 Network(网络)标签。
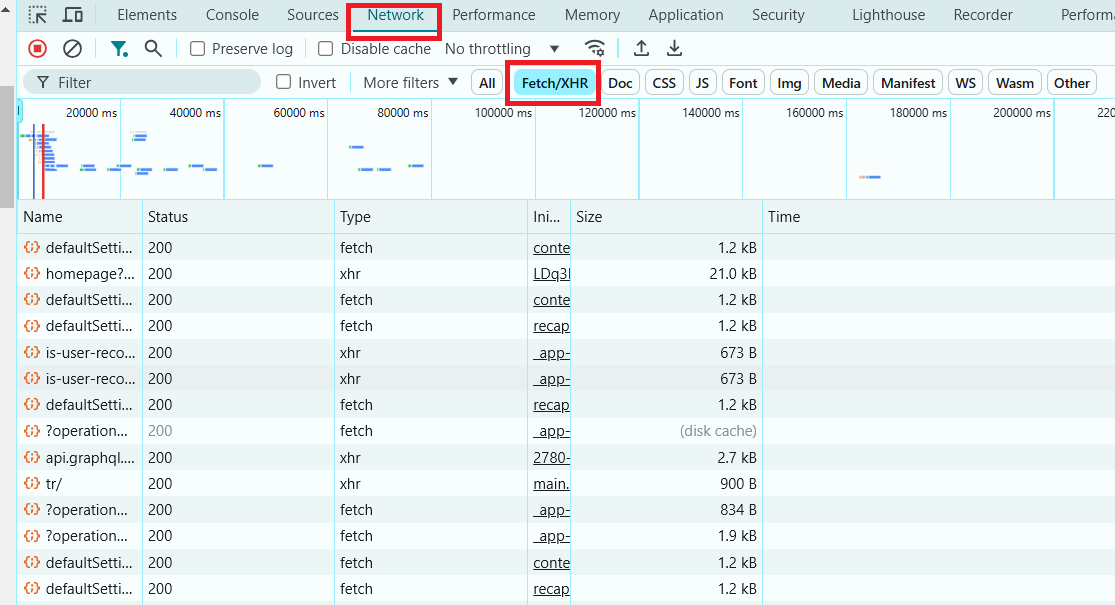
- 过滤XHR(AJAX)请求:
在网络标签的过滤器中查找 XHR 或 Fetch。这些请求是动态获取数据的请求。如果你看到这些请求获取了 JSON、HTML 或其他数据,说明该页面是动态的。
- 检查页面加载后是否有内容加载:
页面加载完成后,检查是否有其他内容出现或变化。如果你看到在初次加载后没有刷新页面就出现了更多内容,那么该网站很可能在使用 AJAX。
现在你知道如何识别动态网站,接下来我们来看看如何抓取一个动态网站。
让我们通过一个例子来演示如何使用 Selenium 抓取 IMDb 的主页。IMDb 是一个很好的动态网站示例,页面加载后内容会异步加载。
要使用 Selenium 从网页抓取数据(文档链接),关键是要正确识别你想提取信息的元素。让我们以 IMDb 页面为例,找到必要的元素进行数据提取:
- 打开浏览器并访问:https://www.imdb.com/?ref_=nv_home。
- 打开 DevTools:右键点击页面上的任意位置,选择 检查,或者按 Ctrl+Shift+I(Windows/Linux)或 Cmd+Option+I(Mac)来打开开发者工具。
- 定位“今天推荐”部分:右键点击“今天推荐”区域中的标题或图片,选择 检查。这将高亮显示与该部分相关的 HTML 代码。
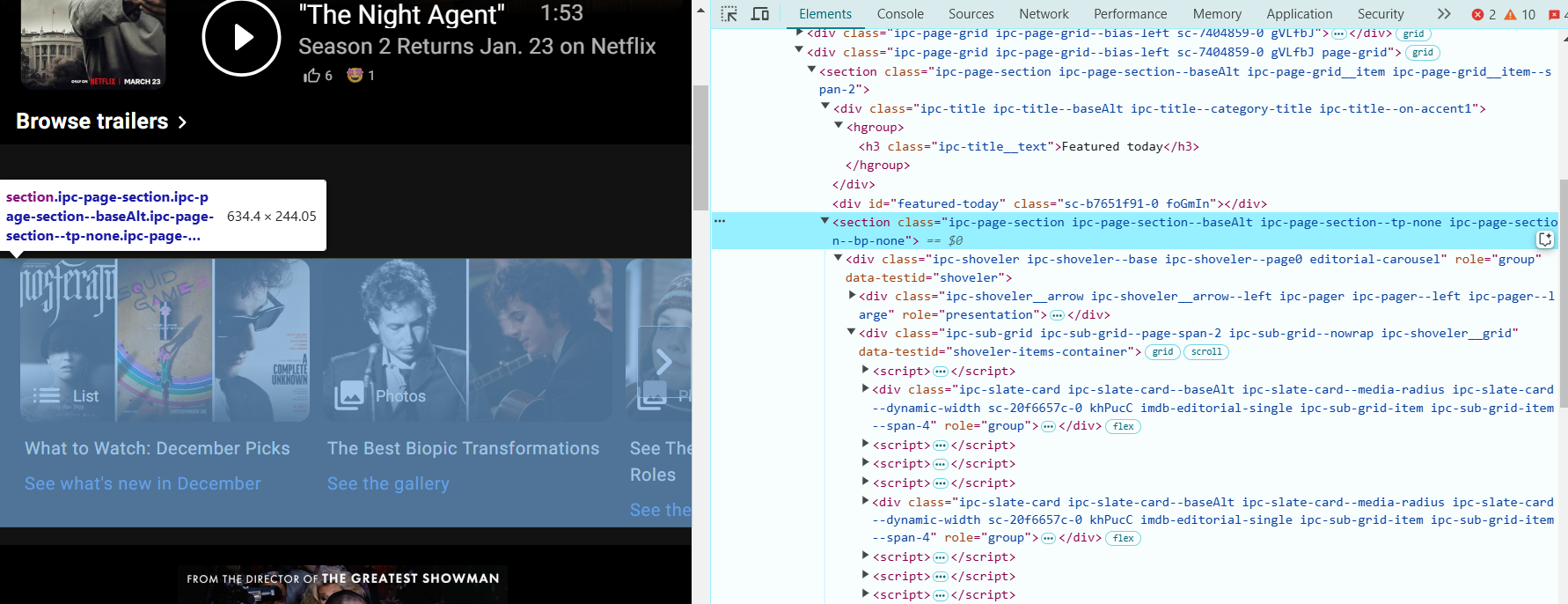
- 在 DevTools 中,查看页面的 HTML 结构。“今天推荐”部分的 HTML 结构大致如下:
<section class="ipc-page-section ipc-page-section--baseAlt ipc-page-section--tp-none ipc-page-section--bp-none">
这个部分包含了我们想要抓取的电影或节目的标题。
- 电影或节目的标题位于具有类名 ipc-slate-card__title-text 的 <div> 元素内。你会看到类似这样的内容:
<div class="ipc-slate-card__title-text">Movie Title</div>- 每个标题都是一个链接,包裹在 <a> 标签中。链接看起来像这样:
<a class="ipc-link" href="https://www.imdb.com/title/tt1234567/">Link</a>- 将 Selenium Java 和 Selenium ChromeDriver 的依赖项添加到 <dependencies> 部分。将这些依赖项复制到你的 pom.xml 文件中的 <dependencies> 部分。它应该是这样的:
<dependencies>
<!-- Selenium WebDriver -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>4.27.0</version>
</dependency>
<!-- Selenium ChromeDriver -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-chrome-driver</artifactId>
<version>4.27.0</version>
</dependency>
</dependencies>- 现在我们可以继续编写代码:
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.util.List;
public class WebScraper {
public static void main(String[] args) {
// 创建一个驱动实例:
WebDriver driver = new ChromeDriver();
try {
// 打开 IMDb 主页:
driver.get("https://www.imdb.com/?ref_=nv_home");
System.out.println("Featured Today on IMDb:");
// 通过类名提取“今天推荐”部分的容器:
WebElement pageSectionContainer = driver.findElement(By.cssSelector("section.ipc-page-section.ipc-page-section--baseAlt.ipc-page-section--tp-none.ipc-page-section--bp-none"));
// 在该部分中找到标题:
List<WebElement> titles = pageSectionContainer.findElements(By.cssSelector("div.ipc-slate-card__title-text"));
// 提取动作(例如,链接):
List<WebElement> actions = pageSectionContainer.findElements(By.cssSelector("a.ipc-link"));
// 遍历并打印标题和动作(链接):
int count = 0;
for (int i = 0; i < titles.size() && count < 10; i++) {
String title = titles.get(i).getText();
String action = actions.get(i).getAttribute("href");
System.out.printf("%d. %s - Link: %s%n", ++count, title, action);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
driver.quit();
}
}
}爬虫解释:
- 我们初始化 ChromeDriver 并打开 IMDb 主页。
- 我们使用 CSS 选择器查找“今天推荐”部分。该部分通过页面上使用的一组特定类进行标识。
- 找到该部分后,我们使用适当的 CSS 选择器(ipc-slate-card__title-text 用于标题,ipc-link 用于链接)来查找单个电影标题和对应的链接。
- 我们遍历标题和链接的列表,并打印前 10 个推荐项。
有几种方法可以保存网页抓取的数据,包括:
- 文本文件 (TXT) — 用于将数据存储为纯文本格式,适用于简单的存储。
- CSV 文件 — 用于以表格格式存储数据,便于在 Excel 或其他分析工具中进行处理。
- 数据库 — 适用于需要存储大量数据的复杂项目(例如,MySQL、SQLite)。
- JSON 或 XML — 用于结构化数据,适合在应用程序之间交换数据。
在我们的例子中,文本文件或CSV将是最好的选择。这是因为数据由简单的文本字符串和链接组成,可以轻松地组织成表格以供后续分析,尤其是在数据量不大的情况下。CSV 格式特别适用于存储带有多个列的数据(例如标题和链接)。
保存到文本文件:
为了将数据保存到简单的文本文件中,可以使用 FileWriter 和 BufferedWriter 类,如下所示:
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
import java.util.List;
public class WebScraper {
public static void main(String[] args) {
// 创建驱动程序实例
WebDriver driver = new ChromeDriver();
try {
// 打开IMDb主页
driver.get("https://www.imdb.com/?ref_=nv_home");
System.out.println("Featured Today on IMDb:");
// 通过类名提取“今日推荐”部分的容器
WebElement pageSectionContainer = driver.findElement(By.cssSelector("section.ipc-page-section.ipc-page-section--baseAlt.ipc-page-section--tp-none.ipc-page-section--bp-none"));
// 在该部分中找到标题
List<WebElement> titles = pageSectionContainer.findElements(By.cssSelector("div.ipc-slate-card__title-text"));
// 提取动作(例如链接)
List<WebElement> actions = pageSectionContainer.findElements(By.cssSelector("a.ipc-link"));
// 创建一个FileWriter来将数据保存到文件
BufferedWriter writer = new BufferedWriter(new FileWriter("featured_today_imdb.txt"));
writer.write("Featured Today on IMDb:\n");
writer.write("--------------------------------\n");
// 遍历并将标题和动作保存到文本文件
int count = 0;
for (int i = 0; i < titles.size() && count < 10; i++) {
String title = titles.get(i).getText();
String action = actions.get(i).getAttribute("href");
writer.write(String.format("%d. %s - Link: %s%n", ++count, title, action));
}
writer.close(); // Don't forget to close the writer!
} catch (Exception e) {
e.printStackTrace();
} finally {
driver.quit();
}
}
}保存为CSV文件:
如果您更喜欢将数据保存为CSV格式,可以使用以下代码,将数据写入逗号分隔值:
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.io.FileWriter;
import java.io.IOException;
import java.util.List;
public class WebScraper {
public static void main(String[] args) {
// 创建驱动程序实例
WebDriver driver = new ChromeDriver();
try {
// 打开IMDb主页
driver.get("https://www.imdb.com/?ref_=nv_home");
System.out.println("Featured Today on IMDb:");
// 通过类名提取“今日推荐”部分的容器
WebElement pageSectionContainer = driver.findElement(By.cssSelector("section.ipc-page-section.ipc-page-section--baseAlt.ipc-page-section--tp-none.ipc-page-section--bp-none"));
// 在该部分中找到标题
List<WebElement> titles = pageSectionContainer.findElements(By.cssSelector("div.ipc-slate-card__title-text"));
// 提取动作(例如链接)
List<WebElement> actions = pageSectionContainer.findElements(By.cssSelector("a.ipc-link"));
// 创建一个FileWriter来将数据保存到CSV文件
FileWriter writer = new FileWriter("featured_today_imdb.csv");
writer.append("Title, Link\n");
// 遍历并将标题和动作保存到CSV文件
int count = 0;
for (int i = 0; i < titles.size() && count < 10; i++) {
String title = titles.get(i).getText();
String action = actions.get(i).getAttribute("href");
writer.append(String.format("\"%s\", \"%s\"\n", title, action));
count++;
}
writer.flush(); // Ensure everything is written to the file
writer.close(); // Close the writer
} catch (Exception e) {
e.printStackTrace();
} finally {
driver.quit();
}
}
}现在,您可以将从IMDb提取的数据保存到文本文件或CSV文件中,这样可以更轻松地进行分析或共享!
在进行网页抓取时,确保过程对抓取者和目标网站都是安全的至关重要。以下是一些安全最佳实践:
- 避免通过单一IP地址过度请求网站。使用代理轮换IP地址并分配负载。
- 一些网站具有像CAPTCHA或其他反抓取技术的措施。必须有效处理这些问题,可能需要像CapMonster Cloud这样的工具来解决CAPTCHA。
- 为了避免被标记为机器人,通过在请求之间添加延迟来限制请求频率。这模拟了人类浏览行为并防止了对服务器的过度负担。
- 更改抓取器中的User-Agent字符串,以模拟不同的浏览器。这有助于防止检测。
- 小心不要从抓取过程中存储敏感的用户数据(如密码)。在适用时,遵循数据保护法,例如GDPR。
- 最后,始终检查网站的服务条款(TOS)并确保允许抓取。忽视这一点可能会导致法律后果。
为了加快您的网页抓取过程并提高效率,可以考虑以下建议:
- 使用无头浏览器,如Chrome或Firefox的非GUI模式来加速抓取。这样可以去除渲染用户界面的开销。
例如:使用Selenium中的ChromeOptions在无头模式下运行
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless");
WebDriver driver = new ChromeDriver(options);- 尽可能缓存数据,以避免多次请求相同的信息。如果您处理的是大型数据集,将结果存储在本地数据库中可能会更加高效。
- 使用更高效的XPath和CSS选择器,以最小化DOM遍历。避免使用过于通用的选择器,这可能会导致不必要的检查。例如,避免使用 findElement(By.xpath("//div[@class='example']/a"),如果可能的话,使用更具体的路径。
- 如果页面不需要JavaScript来渲染内容,避免使用像Selenium这样的工具,选择更快速的库,如Jsoup,它直接解析HTML。
- 并行处理。使用多个线程或进程同时抓取多个页面。这可以大大减少抓取大量页面所需的时间。
工具:可以考虑使用像Java中的ExecutorService这样的库来进行多线程处理。
以下是使用java.util.concurrent库进行网页抓取并行化的示例,该库提供了多线程编程的工具。
import java.io.IOException;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class ParallelWebScraping {
// 抓取页面内容的方法
public static String scrapePage(String url) throws IOException {
System.out.println("Scraping URL: " + url + " in thread: " + Thread.currentThread().getName());
Document doc = Jsoup.connect(url).get();
return doc.title(); // Returning the page title as an example
}
public static void main(String[] args) {
// 待抓取的URL列表
List<String> urls = Arrays.asList(
"https://example.com",
"https://example.org",
"https://example.net"
);
// 创建一个固定线程池
ExecutorService executorService = Executors.newFixedThreadPool(3);
try {
// 创建并行执行的任务
List<Callable<String>> tasks = urls.stream()
.map(url -> (Callable<String>) () -> scrapePage(url))
.toList();
// 执行任务并收集结果
List<Future<String>> results = executorService.invokeAll(tasks);
// 打印结果
for (Future<String> result : results) {
System.out.println("Page title: " + result.get());
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// 关闭线程池
executorService.shutdown();
}
}
}
- 我们定义了一个待抓取的URL列表。
- 创建一个固定线程池以限制同时运行的线程数。
- 每个Callable表示一个任务,执行后返回一个结果(在此情况下为页面标题)。
- invokeAll方法并行执行所有任务,并返回一个包含结果的Future对象列表。
- 使用Jsoup库来获取和解析网页。
- 从Future对象中提取页面标题(或其他数据)。
Java是进行网页抓取的绝佳选择,提供了强大的工具和库来进行数据提取。在本文中,我们讨论了关键方法,包括静态和动态抓取、使用API以及分享了更高效数据检索的实用技巧。
通过像CapMonster Cloud这样的工具来绕过CAPTCHA,Java使您能够处理甚至是最具挑战性的任务。进行实验,扩展您的技能,并探索新的自动化方式。数据的世界正等待着您去发掘!
- 什么是网页抓取,它是如何工作的?
网页抓取是自动从网页中提取数据的过程。它涉及使用软件检索页面的HTML代码,提取所需信息,然后进行处理或保存。
- 在Java中,进行网页抓取的最佳工具有哪些?
在Java中,常用的网页抓取工具包括:
- Jsoup — 用于解析HTML。
- Selenium — 用于浏览器自动化,特别是针对动态网站。
- HtmlUnit — 一个轻量级的自动化浏览器。
- 如何绕过抓取保护(如CAPTCHA)?
要绕过CAPTCHA,您可以使用像CapMonster Cloud这样的服务,它会自动为您的脚本解决CAPTCHA,使您能够继续抓取而不受延迟影响。
- 我可以在所有网站上使用网页抓取吗?
并非所有网站都允许进行网页抓取。在开始之前,您应检查网站的服务条款,确保抓取是被允许的。许多网站使用如CAPTCHA或IP封锁等保护措施来防止抓取。
- 我可以通过网页抓取提取哪些类型的数据?
您可以提取各种类型的数据,例如:
- 文本(例如,标题、描述)。
- 产品价格。
- 用户数据。
- 新闻内容。
- 结构化数据,如表格和列表。
- 如何处理网站上的动态内容?
对于通过JavaScript加载的动态内容,您可以使用像Selenium这样的工具,它模拟浏览器中的用户操作,允许您从动态生成的页面中提取数据。
- 如何加快抓取过程?
使用多线程和并行请求来加速数据收集。限制请求频率以避免被封锁。使用代理服务器来分配负载。
- 如果网站封锁了我的请求,我该怎么办?
如果网站封锁了您的请求,您可以:
- 使用代理来更改您的IP地址。
- 在请求之间添加延迟。
- 更改您的用户代理,模拟真实浏览器。
- 使用指纹识别模拟真实浏览器会话。指纹识别包括修改请求头和其他会话数据(如Cookies、Referers和Accept-Languages),使您的请求看起来更像来自实际用户。
- 使用CAPTCHA解决服务。