Веб-скрапинг на Python: эффективная автоматизация сбора данных
Веб-скрапинг — это метод сбора данных с веб-сайтов. Он позволяет извлекать нужную информацию для анализа, мониторинга цен, отслеживания новостей и других различных целей. Веб-скраперы или парсеры – инструменты для осуществления веб-скрапинга. Наиболее удобным и популярным языком для написания веб-скраперов является Python, хотя для этой цели можно использовать практически любой язык. Пользователи выбирают Python по нескольким причинам: лёгкий синтаксис, множество удобных библиотек для парсинга, постоянная поддержка и обновления.
В этом руководстве мы рассмотрим основные инструменты для веб-скрапинга, предоставим пример реализации на Python. С помощью пошаговых инструкций вы сможете понять основы веб-скрапинга и парсинга, написать простой скрипт для сбора данных, а также узнаете о методах обхода различных препятствий в процессе работы.
Инструменты для работы, их характеристика
Выбор IDE
Для работы необходима среда разработки. Выбор подходящей среды для веб-скрапинга зависит от нескольких факторов, таких, как удобство использования, поддержка нужных инструментов, личные предпочтения и требования проекта. Среди наиболее популярных инструментов для работы, которые хорошо подходят для веб-скрапинга на Python, можно отметить PyCharm и Visual Studio Code.
PyCharm
Плюсы:
- Полноценная IDE с множеством функций.
- Поддержка отладки, автодополнения кода и управления проектами.
- Поддержка виртуальных окружений и интеграция с Git.
Минусы:
- Может быть перегруженной для небольших проектов.
- Требует больше ресурсов по сравнению с текстовыми редакторами.
Visual Studio Code (VS Code)
Плюсы:
- Легковесная и настраиваемая среда.
- Широкий выбор расширений для Python и веб-скрапинга.
- Поддержка отладки, Git и терминала.
Минусы:
- Может требовать настройки для полноценной работы с Python.
- Возможны проблемы с производительностью при большом количестве расширений
Установка Python
Также на вашем компьютере должен быть установлен Python. Инструкция по установке для вашей ОС:
macOS
Для установки свежей версии Python перейдите по ссылке, скачайте установщик и следуйте его указаниям:
Linux
В некоторых дистрибутивах Linux (например, в Ubuntu) Python уже предустановлен. Для проверки версии Python выполните в терминале следующую команду:
Версия Python может быть устаревшей, тогда установить последнюю доступную версию поможет эта команда (пример для дистрибутива Debian):
Windows
Перейдите на страницу Python и загрузите подходящую версию. Отметьте галочку "Add python.exe to PATH". Это добавит Python в системный PATH, что облегчит его использование из командной строки.
Библиотеки и инструменты для веб-скрапинга на Python
Теперь можно обратить внимание на библиотеки и инструменты, которые сделают написание скриптов для вашего парсера более удобным. Давайте выделим лучшие из них и рассмотрим их характеристики, чтобы сделать правильный выбор для своих задач.
requests
Requests — это простая и удобная библиотека для отправки HTTP-запросов. Она позволяет легко получать HTML-код веб-страниц. Плюсы данной библиотеки: подходит для большинства стандартных задач веб-скрапинга, особенно если вы не планируете выполнять большое количество одновременных запросов, идеально для скрапинга небольших сайтов или случаев, когда вам не нужно асинхронное выполнение.
aiohttp
Подходит для более сложных сценариев, когда нужно выполнять множество одновременных запросов и управлять асинхронными задачами. Полезен для работы с большим количеством данных и серверов, где высокая скорость и эффективность имеют значение. Идеален для асинхронного веб-скрапинга.
lxml
Гибкая и высокоэффективная библиотека для обработки XML и HTML документов. Она предоставляет удобные возможности для работы, а также поддерживает XPath и XSLT.
BeautifulSoup
BeautifulSoup — это библиотека для парсинга HTML и XML документов. Она позволяет извлекать данные из HTML-кода, структурировать их, может обрабатывать даже некорректно структурированный HTML и корректировать его. Beautiful Soup использует различные парсеры для анализа HTML и XML, например, встроенный парсер Python – html.parser, а также сторонние парсеры lxml и html5lib. Это позволяет выбирать наиболее подходящий парсер для конкретной задачи, обеспечивая лучшую производительность и совместимость.
Scrapy
Это мощный фреймворк для веб-скрапинга и парсинга данных, который позволяет создавать проекты по сбору данных, обрабатывать их и сохранять в различных форматах. Scrapy поддерживает асинхронные запросы, что делает его очень быстрым.
Selenium
Selenium — это инструмент для автоматизации браузеров. Он позволяет взаимодействовать с веб-страницами так, как это делает пользователь, что делает его идеальным для работы с динамическими сайтами. Преимущества Selenium: поддержка работы с Python и JavaScript, возможность имитации пользовательских действий.
Pyppeteer
Это Python-версия Puppeteer (библиотеки Node.js), которая позволяет автоматизировать браузер Chromium для скрапинга веб-сайтов. Это даёт возможность выполнять навигацию по страницам, заполнять и отправлять формы, нажимать кнопки и другие рутинные пользовательские действия. Pyppeteer также полезен для работы с динамическим контентом.
Playwright
Расширенный инструмент для автоматизации браузеров, который поддерживает несколько языков (JavaScript/TypeScript, Python, .NET/C# и Java), многопоточный, работает с несколькими браузерами (Chromium, Firefox, WebKit), установить его можно на Windows, macOS и Linux. Playwright предлагает высокую производительность и удобство использования для скрапинга и тестирования веб-приложений.
Примеры веб-скраперов для статических и динамических сайтов
Что такое HTML
Прежде чем приступить к написанию любого скрапера, нужно понимать основы HTML и уметь анализировать разметку сайтов и не теряться при поиске элементов. Итак, HTML (HyperText Markup Language) – это стандартный язык разметки, используемый для создания и структурирования веб-страниц. Он описывает структуру документа, включая текст, изображения, ссылки и другие элементы, которые отображаются в браузере.
Основные элементы HTML
Теги: HTML-документ состоит из различных тегов, которые определяют структуру и содержание. Например:
- <html>: корневой элемент HTML-документа.
- <head>: содержит метаданные, такие как заголовок страницы (<title>) и ссылки на стили.
- <body>: основная часть документа, содержащая видимое содержимое страницы.
Элементы: внутри тегов могут находиться элементы:
- <h1>, <h2>, ..., <h6>: заголовки различных уровней.
- <p>: параграф текста.
- <a>: ссылка.
- <img>: изображение.
- <div>, <span>: контейнеры для группировки других элементов.
Атрибуты: теги могут иметь атрибуты, которые предоставляют дополнительную информацию об элементе. Например:
- <a href="https://example.com">: атрибут href указывает URL для ссылки.
- <img src="image.jpg" alt="описание изображения">: атрибут src указывает путь к изображению, а alt — альтернативный текст.
Выбор сайта
Прежде чем выбрать подходящие инструменты для написания скрапера, нужно изучить целевой сайт и понять, содержит ли он динамический контент. Чтобы это понять, нужно загрузить страницу, открыть вкладку Сеть в Инструментах разработчика и посмотреть, выполняются ли Fetch/XHR-запросы (технологии, позволяющие веб-страницам динамически обновлять содержимое на основе данных, полученных с сервера):
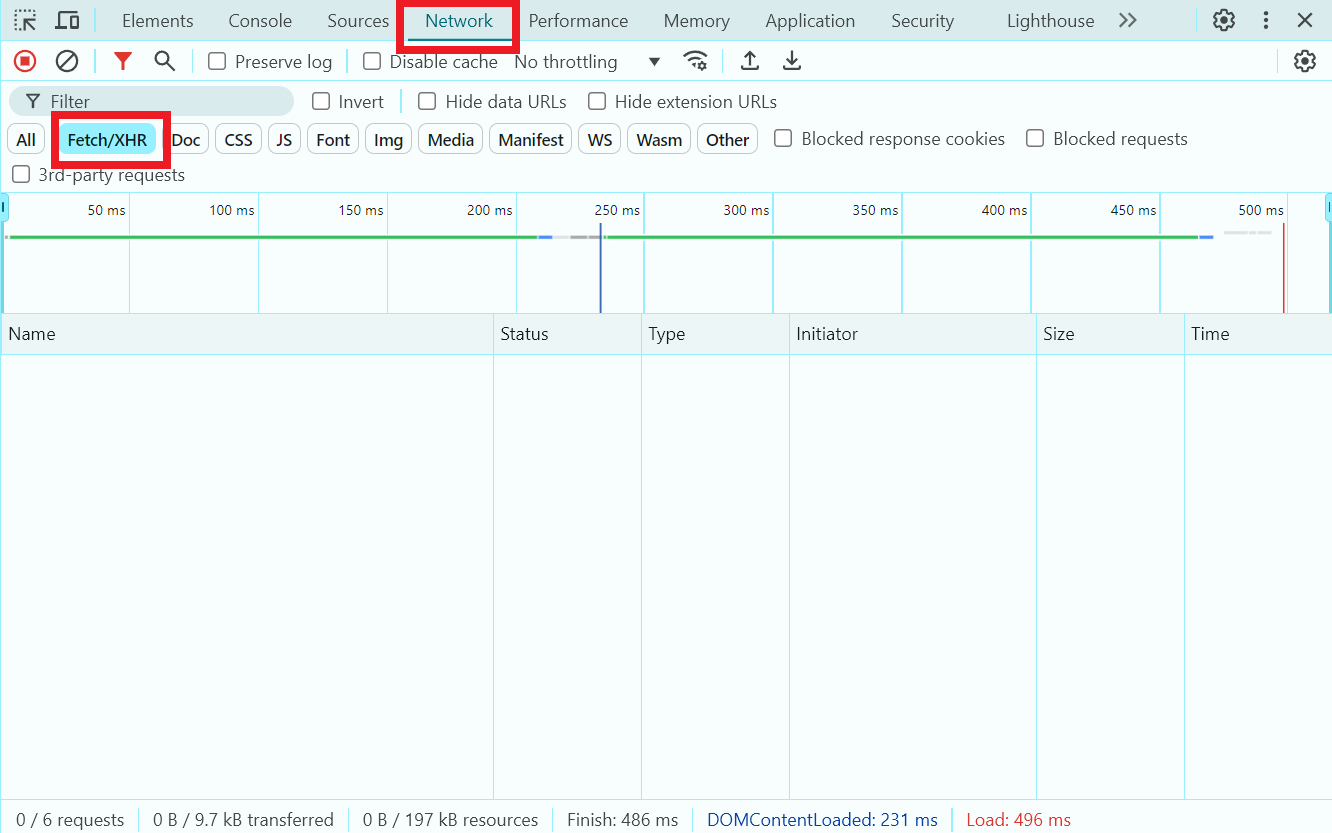
Fetch/XHR-запросы не выполняются
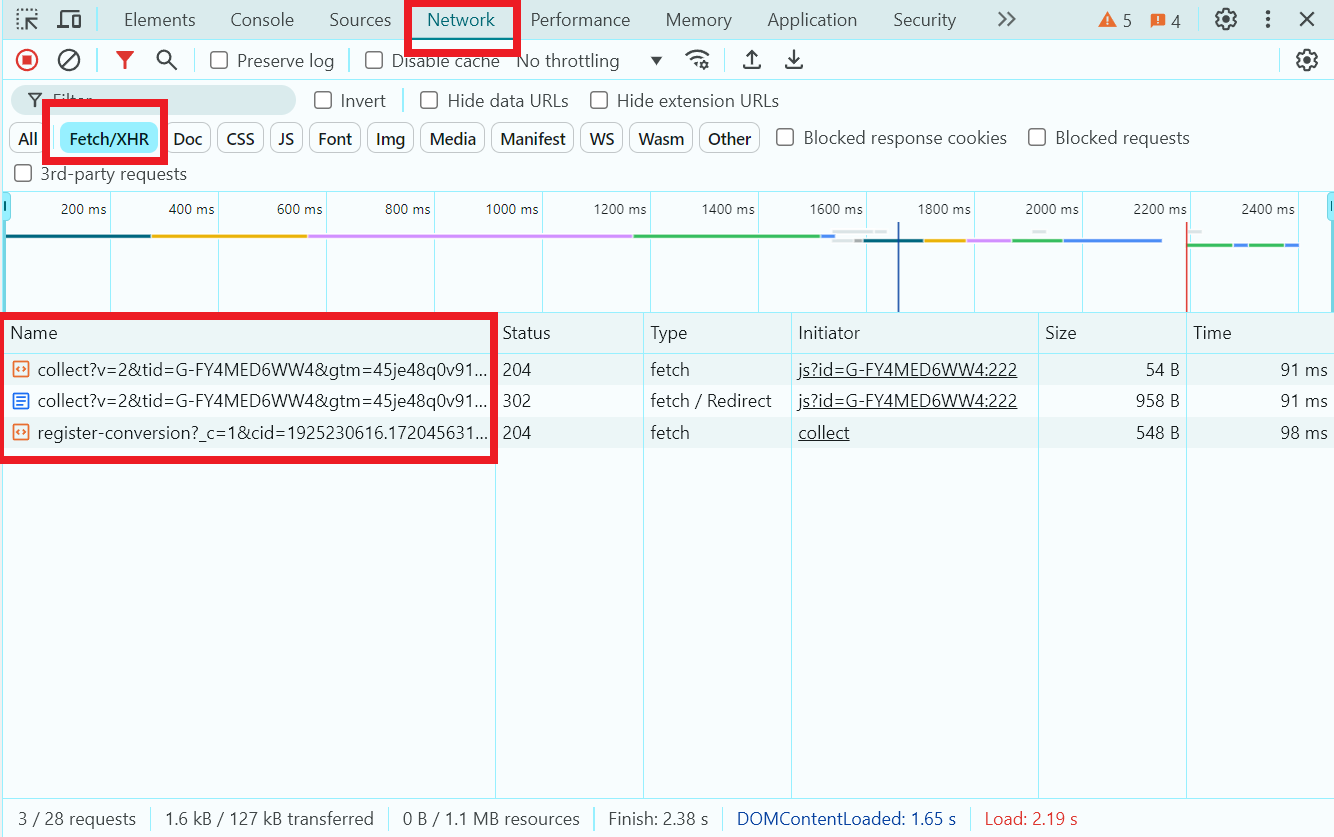
Загрузка JavaScript для динамического извлечения данных
Если сайт не содержит динамический контент, можно воспользоваться библиотеками BeautifulSoup и requests. В ином случае следует использовать загрузку веб-страниц с помощью Selenium или Playwright.
В качестве тестовой статической страницы для извлечения некоторых данных выберем https://quotes.toscrape.com/. Давайте напишем простой скрапер для извлечения первых трёх фраз и их авторов.
Выбор инструментов для написания скрапера, установка
Для нашей цели вполне подойдут библиотеки BeautifulSoup и requests. Создадим новый файл в редакторе/среде разработки, добавим библиотеки в проект командой:
BeautifulSoup осуществляет поиск и извлечение данных:
По тегам:
По тексту. Чтобы извлечь текст из тега, используйте метод .get_text():
По классам, идентификаторам и атрибутам:
Для более сложных запросов можно использовать CSS-селекторы с методом .select():
Поиск элементов на странице, написание скрапера
Вернёмся к целевой странице, найдём необходимые элементы и начнём писать код.
- Откроем новый созданный файл, импортируем ранее установленные библиотеки:
- Прописываем url нужной страницы, устанавливаем заголовок User-Agent для имитации работы браузера, отправляем get-запрос на страницу:
- Проверяем, что запрос выполнен успешно:
- В отдельном открытом с нужной страницей браузере ищем все блоки с цитатами, проходим по первым трём блокам цитат и извлекаем текст цитаты в нашем коде:
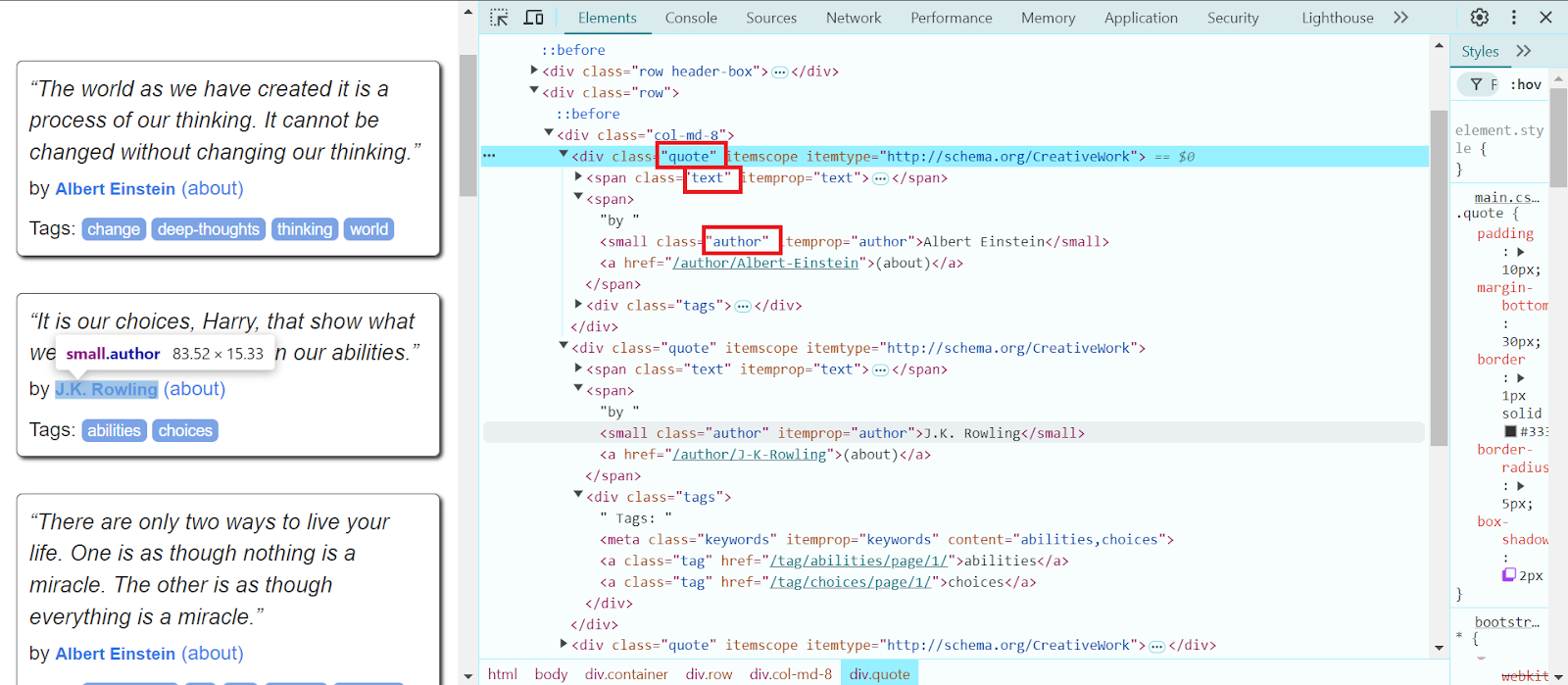
5. Извлекаем имя автора и прописываем его в консоль:
Готовый код с пояснениями:
6. Запустим код, и наш скрапер выведет необходимую нам информацию – первые три фразы и имена их авторов:
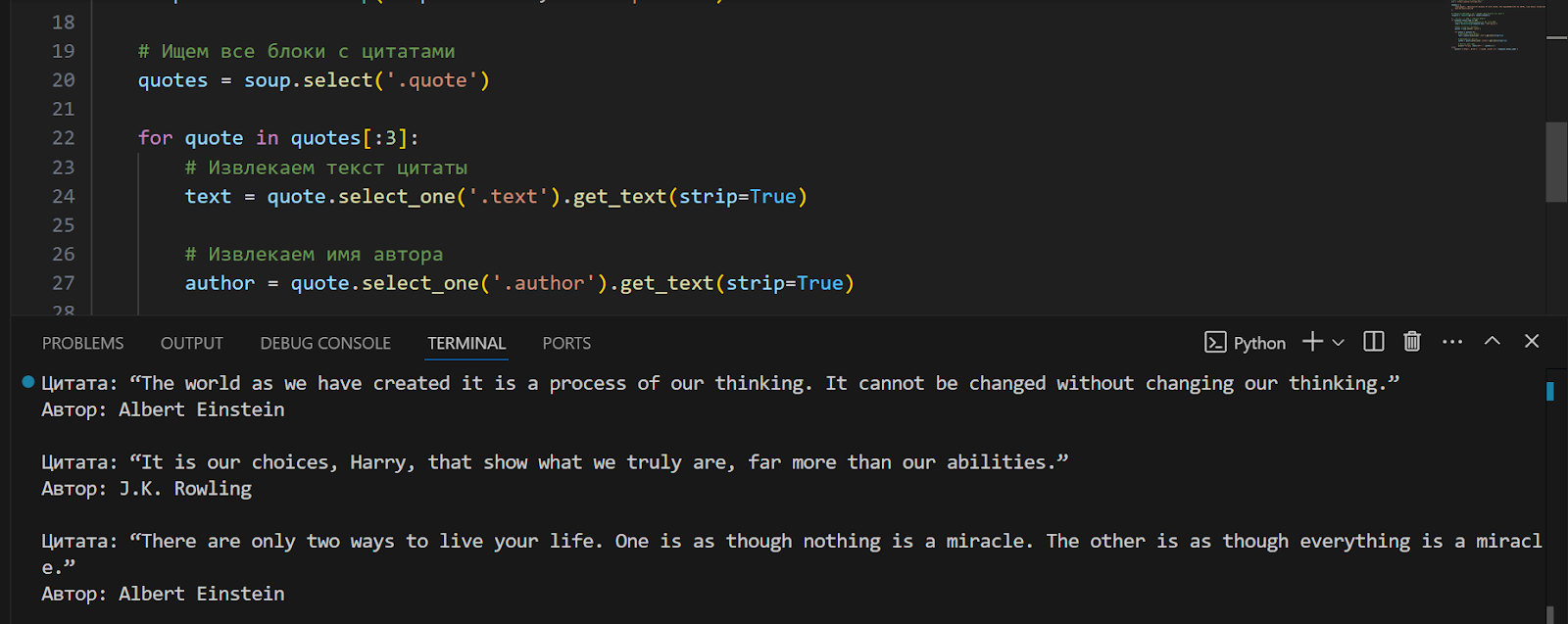
Пример скрапера для динамического сайта
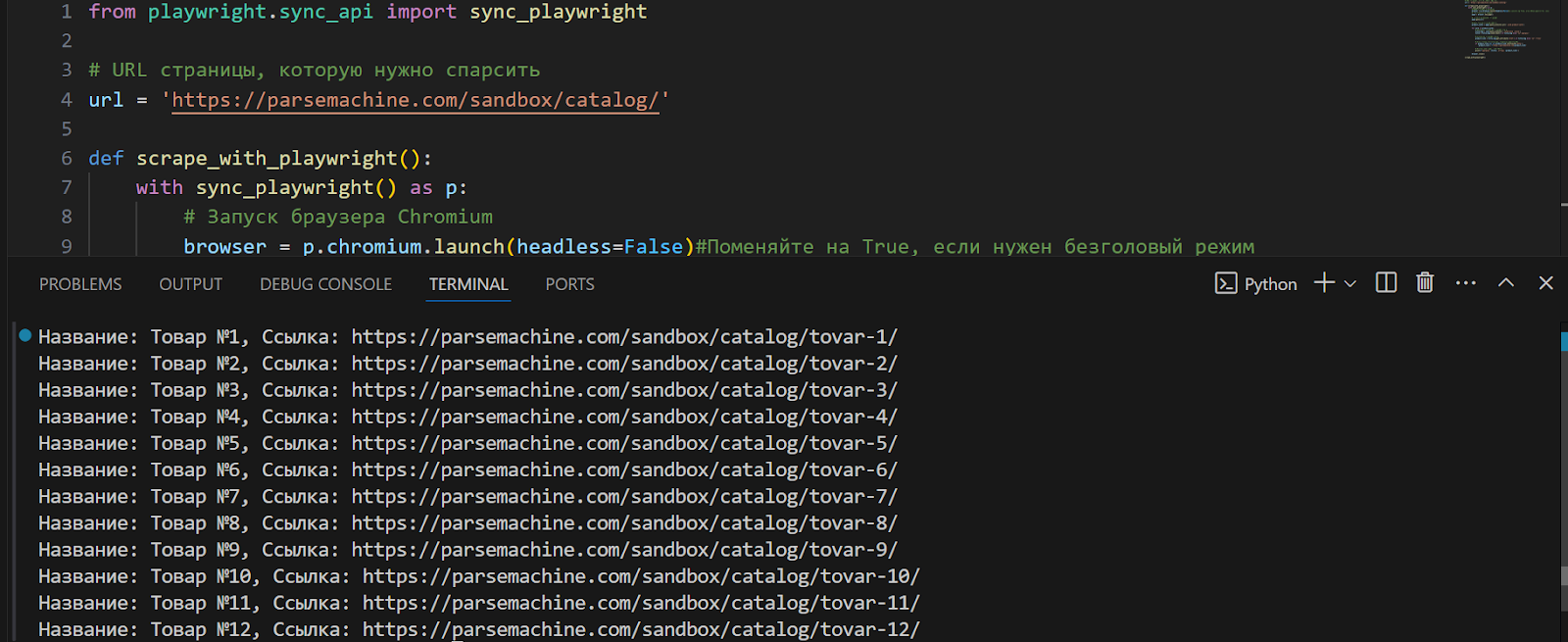
В качестве примера динамического сайта возьмём https://parsemachine.com. В частности выберем тестовую страничку https://parsemachine.com/sandbox/catalog/, на ней представлены карточки с 12 товарами. Попробуем извлечь название каждого товара и ссылку на него. Так как сайт динамический, будем использовать Playwright. Этот инструмент автоматизации браузера находит и извлекает элементы на веб-страницах с помощью CSS и XPath селекторов, текстовых и ARIA селекторов, а также поддерживает комбинирование селекторов для точного выбора.
- Создадим новый проект, установим Playwright и браузер Chromium командами:
- Найдём интересующие нас элементы с помощью Инструмента разработчика
- Импортируем Playwright, запускаем браузер и переходим на нужную страницу:
В нашем примере нам хватит использования синхронного метода выполнения. Однако асинхронный подход имеет свои преимущества, особенно в задачах, связанных с I/O операциями, такими, как сетевые запросы и взаимодействие с веб-страницами, позволяет выполнять несколько операций параллельно, не блокируя основной поток выполнения. Это особенно полезно, если нужно парсить много страниц одновременно. Также он позволяет программе продолжать выполнять другие задачи, пока ждёт ответа от сервера, что улучшает общую отзывчивость приложения. Для асинхронного метода используйте async_playwright() вместо sync_playwright() и добавьте await в свой код. Также могут понадобиться дополнительные библиотеки наподобие asyncio – она помогает организовывать и координировать выполнение асинхронных операций.
- Ищем все карточки продуктов, проходимся по каждой карточке, извлекаем ссылку на страницу товара:
- Ссылка на страницу товара:
- Если ссылка относительная, добавляем базовый URL:
- Закрываем браузер, прописываем функцию для запуска:
Готовый код полностью:
- Запустим наш скрипт, при его выполнении выведется вся нужная нам информация с названиями каждого товара, представленного на странице, и ссылками на них:
Как сохранить извлечённую информацию?
Для того, чтобы сохранять извлечённую информацию, нужно немного знать о форматах хранения результатов:
CSV – один из самых популярных форматов для хранения табличных данных. Он представляет собой текстовый файл, где каждая строка соответствует одной записи, а значения разделены запятыми. Преимущества данного формата: поддерживается большинством программ для обработки данных, включая Excel, легко читается и редактируется с помощью текстовых редакторов. Недостатки: ограниченные возможности для хранения сложных структур данных (например, вложенных данных). Проблемы с экранированием запятых и специальных символов.
JSON – это текстовый формат обмена данными, который удобно использовать для представления структурированных данных. Он широко используется в веб-разработке. Плюсы: поддерживает вложенные и иерархические структуры данных; хорошо поддерживается большинством языков программирования; легко читается и людьми, и машинами. JSON подходит для хранения данных, которые могут потребовать передачи через API. Минусы: JSON-файлы могут быть больше по размеру по сравнению с CSV; медленнее обрабатывается по сравнению с CSV из-за более сложной структуры.
XLS – предназначен для таблиц Excel, где хранятся данные о ячейках, форматировании и формулах. Он часто используется для хранения баз данных. Чтобы работать с XLS в Python, нужны сторонние библиотеки, например, pandas. Этот формат позволяет хранить данные в удобочитаемом и презентабельном виде. Основной недостаток — необходимость в дополнительных библиотеках, что увеличивает нагрузку на сервер и время обработки данных.
XML – это язык разметки, который используется для хранения и передачи данных. Он поддерживает вложенные структуры и атрибуты. Плюсы: структурированность, позволяет хранить сложные структуры данных, хорошо поддерживается различными стандартами и системами. Минусы: XML-файлы могут быть громоздкими и сложными для обработки; обработка XML может быть медленной из-за его структуры.
Базы данных используются для хранения больших объёмов структурированных данных. Примеры включают MySQL, PostgreSQL, MongoDB, SQLite. Плюсы: поддержка больших объемов данных и быстрый доступ; легко организовывать и связывать данные; поддержка транзакций и восстановления данных. Минус: требует дополнительных усилий для настройки и обслуживания.
Для наших скраперов выберем формат CSV, потому что извлечённые данные носят табличный характер (текст цитаты и автор, названия товаров и ссылки к ним) и объём данных относительно небольшой, без вложенных структур. Дополнительную информацию о том, как читать и записывать информацию в данном формате, можно узнать здесь. Добавим в наш код с цитатами импорт CSV, создадим объект writer, запишем данные цитат (сами цитаты и их авторов):
Также добавим дополнительные выводы в консоль и обработку возможных ошибок:
Вот обновлённый код полностью:
Аналогичные действия проделаем и со вторым скрапером:
Препятствия при веб-скрапинге
- Меняющаяся, усложнённая структура сайта: одним из самых распространённых препятствий при веб-скрапинге является изменение структуры веб-сайта и обфускация кода. Даже небольшие изменения в HTML-разметке или структуре страниц могут привести к тому, что скрипты для скрапинга перестанут работать. Это может потребовать частого обновления кода для адаптации к новым изменениям.
- Ограничение запросов: многие веб-сайты имеют ограничения на количество запросов, которые можно отправить за определённый период времени. Если ваши запросы превышают установленные лимиты, ваш IP-адрес может быть временно заблокирован.
- Блокировка IP: сайты могут блокировать IP-адреса, которые они определяют как подозрительные или слишком активные, и это может быть серьёзным препятствием для скрапинга. В этом случае потребуется использование качественных прокси-серверов для обхода таких блокировок.
- CAPTCHA: многие веб-ресурсы внедряют защитные меры в виде капчи для предотвращения автоматизированных действий. Капча требует ручного ввода или использования специализированных сервисов для его обхода.
Одним из лучших сервисов на сегодняшний день является CapMonster Cloud – наличие API позволяет легко интегрировать его в код для обхода капчи и продолжения работы скрапера. К нему легко подключиться, он обеспечивает быстрое решение разных типов капч с минимальными ошибками – поддерживает reCAPTCHA, DataDome, Amazon CAPTCHA и другие. CapMonster Cloud может считаться оптимальным выбором в качестве вспомогательного инструмента и важной составляющей процесса веб-скрапинга.
Готова библиотека для быстрой интеграции в Python-код
Рекомендации для успешного скрапинга
- Используйте ротацию прокси и User-Agent, чтобы избежать блокировок IP-адресов и обойти ограничения на запросы, это поможет имитировать запросы от различных устройств и браузеров.
- Добавляйте обработку ошибок и повторные попытки: веб-страница может быть временно недоступна, или запрос может завершиться ошибкой. Механизм повторных попыток и обработка ошибок поможет обеспечить устойчивость вашего скрипта к таким ситуациям и предотвратить прерывание процесса скрапинга.
- Перед началом скрапинга обязательно ознакомьтесь с файлом robots.txt сайта. Этот файл содержит рекомендации для ботов о том, какие части сайта можно и нельзя сканировать. Соблюдение этих рекомендаций помогает избежать юридических проблем и конфликтов с владельцами сайтов.
- Добавляйте случайные задержки между запросами, чтобы избежать подозрительной активности и снизить вероятность блокировки.
Эти рекомендации помогут вашему скрипту имитировать поведение реального пользователя, а значит, и снизить вероятность обнаружения.
Итак, веб-скрапинг на Python – один из самых популярных способов эффективного сбора данных с различных веб-сайтов. Мы обсудили, как выбрать подходящие инструменты для веб-скрапинга, рассмотрели процесс установки Python и необходимых библиотек, а также написания кода для извлечения данных и сохранения результатов в удобных форматах. С помощью пошагового подхода, описанного в этой статье, даже начинающий разработчик сможет освоить основные техники веб-скрапинга и создать свои первые скрапер-скрипты. Веб-скрапинг открывает большие возможности для анализа данных, сбора информации, мониторинга рынка и многих других задач. Важно продолжать изучать новые инструменты и методики, чтобы оставаться актуальным в этой постоянно развивающейся области.
Используя такие библиотеки и инструменты, как BeautifulSoup, requests, Selenium, Playwright и другие, упомянутые в данном руководстве, можно извлекать информацию как со статических, так и с динамических сайтов. В процессе работы с веб-скрапингом важно учитывать юридические и этические аспекты, а также быть готовыми к обходу различных препятствий в виде капчи или динамической подгрузки контента.
Каждый из рассмотренных инструментов и подходов имеет свои преимущества и ограничения. Выбор подходящего инструмента зависит от специфики задачи, сложности веб-страниц и объёма данных. Для эффективного веб-скрапинга понимать особенности веб-страниц, с которыми вы работаете.
Надеемся, что инструкции помогут вам лучше понять процесс веб-скрапинга и предоставит необходимые базовые знания для создания собственных скраперов. Успехов в ваших проектах по автоматизации сбора данных и анализа информации!
NB: Напоминаем, что продукт используется для автоматизации тестирования на ваших собственных сайтах и на сайтах, к которым у вас есть доступ на законных основаниях.