Веб-краулинг с Python: Полное руководство
Веб-краулинг — это полезный способ сбора данных с интернета, часто используемый для индексации веб-сайтов, отслеживания изменений или сбора больших объемов информации. В этой статье мы разберем основы веб-краулинга, познакомим вас с полезными инструментами и библиотеками на Python, а также покажем простые примеры, чтобы помочь вам начать!
Веб-краулинг — это процесс автоматического поиска в интернете для сбора информации с веб-сайтов. Он включает в себя исследование нескольких страниц на одном сайте (или даже на разных сайтах) для сбора огромных объемов данных. Крупномасштабные краулеры используются поисковыми системами и другими компаниями для индексации сайтов и сбора данных для различных целей.
Например, Googlebot посещает миллиарды страниц каждый день, следуя по ссылкам между страницами и сайтами, чтобы поддерживать актуальность результатов поиска Google. Googlebot начинает с посещения нескольких ключевых URL-адресов и затем следует по ссылкам на этих страницах, чтобы открыть новые. Он использует умные алгоритмы, чтобы решать, какие страницы индексировать и как часто, чтобы предоставить пользователям наиболее релевантные результаты поиска.
Python — отличный выбор для веб-краулинга, потому что он прост в изучении и имеет множество полезных библиотек. Инструменты, такие как Scrapy, BeautifulSoup и Selenium, упрощают процесс краулинга веб-сайтов и сбора данных, независимо от того, насколько простая или сложная задача.
Веб-краулинг и веб-скрапинг тесно связаны, но это не одно и то же.
Веб-краулинг похож на паука, который перемещается от страницы к странице на одном сайте (или даже на нескольких сайтах), чтобы собирать данные. Это больше про исследование и индексацию больших объемов информации, обычно путем следования по ссылкам между страницами.
Веб-скрапинг, с другой стороны, фокусируется на извлечении конкретных данных с веб-страницы. Это как увеличение деталей — например, сбор цен на продукты, контактной информации или текста с одной страницы или набора страниц.
Таким образом, краулинг — это процесс поиска и сбора данных на множестве страниц, в то время как скрапинг — это процесс извлечения конкретной информации с этих страниц.
Давайте рассмотрим пример того, как базовый веб-краулер собирает информацию с веб-сайта.
Начало с Seed URL
Представьте, что вы хотите собрать информацию о блог-постах на веб-сайте. Ваш начальный URL (Seed URL) может быть главной страницей блога, например https://example.com.
Запрос веб-страницы
Краулер отправляет HTTP-запрос на https://example.com, прося сервер вернуть HTML-контент главной страницы. Сервер отвечает, отправляя HTML этой страницы.
Парсинг HTML-контента
Затем краулер парсит HTML главной страницы. Он ищет определенные элементы, такие как ссылки на блог-посты (которые обычно содержатся в тегах <a>) и другую полезную информацию, например, заголовки страниц или метаданные.
Извлечение ссылок
С главной страницы краулер находит ссылки на другие страницы — например, он находит следующие ссылки:
https://example.com/blog/post1
https://example.com/blog/post2
https://example.com/about
Краулер добавляет эти ссылки в свой список страниц для посещения.
Следование по ссылкам
Теперь краулер запрашивает первый блог-пост, https://example.com/blog/post1. Он отправляет еще один HTTP-запрос и получает HTML-контент этой страницы.
Парсинг блог-поста
На странице блог-поста краулер ищет дополнительные ссылки (например, ссылки на другие блог-посты, категории или теги) и данные (например, заголовок поста, автора и дату публикации). Эти данные извлекаются и сохраняются.
Извлечение дополнительных ссылок
Со страницы https://example.com/blog/post1 краулер находит ссылки на другие посты:
https://example.com/blog/post3
https://example.com/blog/post4
Эти новые ссылки добавляются в список URL-адресов для краулинга.
Хранение данных
Краулер собирает заголовок поста, автора, дату и контент со страницы https://example.com/blog/post1 и сохраняет их в структурированном формате, например, в базе данных или CSV-файле.
Избежание дублирования
Краулер отслеживает URL-адреса, которые он уже посетил. Если он снова встречает https://example.com/blog/post1, он пропускает его, чтобы избежать многократного краулинга одной и той же страницы.
Перед началом краулинга краулер проверяет файл robots.txt на https://example.com/robots.txt, чтобы убедиться, что ему разрешено сканировать сайт. Если файл запрещает краулинг определенных разделов сайта (например, панели администратора), краулер избегает этих областей.
Краулер продолжает этот процесс, посещая страницы, извлекая ссылки и собирая данные, пока не соберет всю информацию с сайта или не достигнет заданного лимита.
Этот базовый процесс позволяет краулеру собирать большие объемы данных с сайта, следуя по ссылкам и собирая нужный контент в автоматическом режиме.
Python предлагает широкий выбор мощных библиотек для веб-краулинга, как стандартных, так и сторонних, которые упрощают сбор данных с веб-сайтов. Вот обзор стандартных библиотек и некоторых популярных сторонних вариантов, которые можно использовать для веб-краулинга:
- Стандартные библиотеки
urllib
urllib — это встроенная библиотека Python, которая предоставляет функции для работы с URL-адресами. Ее можно использовать для отправки HTTP-запросов, парсинга URL и обработки ответов. Хотя она не предназначена специально для веб-краулинга, она позволяет загружать страницы, что делает ее базовым инструментом для простых краулеров.
http.client
http.client — еще одна стандартная библиотека, которая может использоваться для обработки HTTP-запросов. Она предоставляет больше контроля над циклом запроса/ответа и позволяет более гибко подходить к получению данных.
- Сторонние библиотеки
Requests
Библиотека requests — одна из самых популярных сторонних библиотек для отправки HTTP-запросов в Python. Она упрощает процесс взаимодействия с веб-страницами и часто используется для задач веб-скрапинга и краулинга. Requests позволяет легко обрабатывать запросы GET, POST и другие HTTP-запросы.
BeautifulSoup
Хотя BeautifulSoup сама по себе не является краулером, она часто используется в сочетании с краулерами для парсинга и извлечения данных с HTML-страниц. Она упрощает навигацию и поиск в дереве документа, извлечение ссылок и парсинг контента.
Scrapy
Scrapy — это мощный и гибкий фреймворк для веб-краулинга, разработанный специально для масштабных задач веб-скрапинга и краулинга. Он позволяет определять пауков (краулеров), которые могут автоматически обходить сайты и извлекать данные. Scrapy охватывает все, от отправки запросов до хранения извлеченных данных, что делает его идеальным для более сложных проектов по краулингу.
Selenium
Selenium в первую очередь известен как инструмент для автоматизации браузеров для веб-тестирования, но его также часто используют в веб-краулинге при работе с динамическими веб-страницами (сайтами с интенсивным использованием JavaScript). Он может взаимодействовать с JavaScript и загружать контент, который не отображается сразу в исходном HTML.
Библиотека re в Python полезна для извлечения, обработки и манипулирования текстом при веб-краулинге. Вот как она может помочь:
- Извлечение ссылок: используйте регулярные выражения для поиска всех атрибутов href (ссылок) в HTML-странице.
- Извлечение данных: легко извлекайте конкретные данные, такие как цены или названия товаров, с использованием шаблонов.
- Очистка данных: удаляйте нежелательные пробелы или теги из извлечённого контента.
- Обработка динамического контента: извлекайте данные, встроенные в JavaScript или сложные HTML-структуры.
- Фильтрация элементов: ищите элементы с конкретными атрибутами (например, классом или ID), используя шаблоны.
Хотя регулярные выражения мощные и быстрые, их следует использовать осторожно, так как их может быть трудно отлаживать, и они могут не подойти для всех задач парсинга HTML.
В этом руководстве мы пройдем через процесс создания простого веб-краулера на Python. Этот краулер будет посещать веб-сайт, извлекать ссылки и переходить по ним для сбора дополнительных данных. Мы будем использовать библиотеку requests для загрузки страниц и BeautifulSoup для парсинга HTML. В этом примере краулер будет начинать с https://www.wikipedia.org/ и собирать все ссылки, найденные на каждой странице, переходя по сайту.
Перед тем как начать, убедитесь, что у вас есть:
- Python 3+: Скачайте установщик с официального сайта, запустите его и следуйте инструкциям по установке.
- IDE для Python: Вы можете использовать Visual Studio Code с расширением Python или PyCharm Community Edition.
- Документация для requests и BeautifulSoup: Ознакомьтесь с официальной документацией, чтобы лучше понять, как они работают.
1. Установка необходимых библиотек
Перед началом работы нужно установить необходимые библиотеки: requests и BeautifulSoup. Вы можете установить их с помощью pip:
pip install requests beautifulsoup42. Настройка логирования
Логирование поможет отслеживать действия краулера. Мы настроим базовое логирование, чтобы отображать полезные сообщения во время работы краулера. Это установит формат логов и уровень логирования на INFO, что будет отображать важные сообщения.
import logging
logging.basicConfig(
format='%(asctime)s %(levelname)s: %(message)s', level=logging.INFO
)3. Создание класса краулера
Краулер будет содержаться в классе, который мы назовем SimpleCrawler. В этом классе мы определим методы для загрузки страниц, извлечения ссылок и управления процессом краулинга.
class SimpleCrawler:
def __init__(self, start_urls=[]):
self.visited = set()
self.to_visit = start_urlsself.visited: Множество для отслеживания URL-адресов, которые мы уже посетили.
self.to_visit: Список, в котором хранятся URL-адреса, которые нужно еще посетить.
4. Загрузка веб-страницы
Следующий шаг — создание метода для загрузки содержимого страницы с помощью библиотеки requests.
def fetch_page(self, url):
"""Загрузить содержимое страницы."""
try:
response = requests.get(url)
response.raise_for_status()
return response.text
except requests.exceptions.RequestException as e:
logging.error(f"Не удалось загрузить {url}: {e}")
return NoneМетод fetch_page отправляет GET-запрос на указанный URL. Если запрос успешен, он возвращает HTML-содержимое страницы. В противном случае записывает ошибку и возвращает None.
5. Извлечение ссылок со страницы
Теперь нам нужно извлечь ссылки (URL-адреса) из HTML страницы. Для этого используем BeautifulSoup для парсинга HTML и поиска всех тегов <a> с атрибутом href.
from urllib.parse import urljoin
def extract_links(self, url, html):
"""Извлечь и вернуть все ссылки с страницы."""
soup = BeautifulSoup(html, 'html.parser')
for anchor in soup.find_all('a', href=True):
link = anchor['href']
full_url = urljoin(url, link)
yield full_urlBeautifulSoup(html, 'html.parser') парсит HTML-содержимое.
soup.find_all('a', href=True) находит все теги <a> с атрибутом href.
urljoin(url, link) гарантирует, что относительные URL-адреса правильно конвертируются в абсолютные.
6. Добавление URL-адресов в очередь
Нам нужно добавить новые URL-адреса в список тех, которые нужно посетить, но только если они еще не были посещены.
def add_to_queue(self, url):
"""Добавить URL в список для посещения, если он еще не был посещен или добавлен в очередь."""
if url not in self.visited and url not in self.to_visit:
self.to_visit.append(url)Этот метод гарантирует, что мы не будем повторно посещать URL-адреса, которые уже были обработаны или добавлены в очередь.
7. Обработка каждой страницы
Теперь напишем метод для обработки каждой страницы. Он будет загружать страницу, извлекать ссылки и добавлять их в очередь.
def process_page(self, url):
"""Обработать страницу и собрать ссылки."""
logging.info(f'Обрабатываем: {url}')
html = self.fetch_page(url)
if html:
for link in self.extract_links(url, html):
self.add_to_queue(link)Этот метод вызывает fetch_page, чтобы загрузить содержимое страницы, а затем извлекает и добавляет найденные ссылки в очередь.
8. Цикл краулинга
Основной цикл будет продолжаться до тех пор, пока не будут посещены все URL-адреса. Он будет извлекать URL из списка to_visit, обрабатывать его и помечать как посещенный.
def crawl(self):
"""Краулим веб с начальных URL-адресов."""
while self.to_visit:
url = self.to_visit.pop(0)
if url not in self.visited:
self.process_page(url)
self.visited.add(url)Цикл будет продолжаться до тех пор, пока есть URL-адреса для посещения. Каждый URL обрабатывается, ссылки извлекаются и добавляются в очередь. После обработки URL помечается как посещенный.
9. Запуск краулера
Наконец, создадим экземпляр класса SimpleCrawler и начнем краулинг с заданного списка URL.
if __name__ == '__main__':
start_urls = ['https://www.wikipedia.org/']
crawler = SimpleCrawler(start_urls)
crawler.crawl()Этот код инициализирует краулер с списком начальных URL-адресов и начинает краулинг.
Пример полного кода:
import logging
from urllib.parse import urljoin
import requests
from bs4 import BeautifulSoup
logging.basicConfig(
format='%(asctime)s %(levelname)s: %(message)s',
level=logging.INFO
)
class SimpleCrawler:
def __init__(self, start_urls=[]):
self.visited = set()
self.to_visit = start_urls
def fetch_page(self, url):
"""Загрузить содержимое страницы."""
try:
response = requests.get(url)
response.raise_for_status()
return response.text
except requests.exceptions.RequestException as e:
logging.error(f"Не удалось загрузить {url}: {e}")
return None
def extract_links(self, url, html):
"""Извлечь и вернуть все ссылки с страницы."""
soup = BeautifulSoup(html, 'html.parser')
for anchor in soup.find_all('a', href=True):
link = anchor['href']
full_url = urljoin(url, link)
yield full_url
def add_to_queue(self, url):
"""Добавить URL в список для посещения, если он еще не был посещен или добавлен в очередь."""
if url not in self.visited and url not in self.to_visit:
self.to_visit.append(url)
def process_page(self, url):
"""Обработать страницу и собрать ссылки."""
logging.info(f'Обрабатываем: {url}')
html = self.fetch_page(url)
if html:
for link in self.extract_links(url, html):
self.add_to_queue(link)
def crawl(self):
"""Краулим веб с начальных URL-адресов."""
while self.to_visit:
url = self.to_visit.pop(0)
if url not in self.visited:
self.process_page(url)
self.visited.add(url)
if __name__ == '__main__':
start_urls = ['https://www.wikipedia.org/']
crawler = SimpleCrawler(start_urls)
crawler.crawl()
Пример вывода:
Этот краулер выполняет базовые задачи по извлечению ссылок с веб-страниц, но у него есть несколько ограничений, которые могут повлиять на его производительность, устойчивость и масштабируемость.
- Нет ограничения по глубине или страницам
Краулер будет продолжать парсить страницы бесконечно, что может перегрузить сервер или привести к зацикливанию.
- Неэффективная обработка ссылок
Все найденные ссылки добавляются в очередь для посещения, но краулер не проверяет, были ли они уже обработаны.
- Однопоточный (сериализованный) скрейпинг
Краулер работает в одном потоке, что делает его медленным при масштабном скрейпинге.
- Отсутствие обработки ошибок или управления тайм-аутами
Краулер просто записывает ошибку и продолжает выполнение, что может быть улучшено добавлением логики повторных попыток.
- Отсутствие обработки robots.txt
Краулер не проверяет, разрешен ли скрейпинг для сайта.
- Отсутствие задержек между запросами
Краулер может перегрузить сервер без задержек между запросами, что может привести к блокировке.
- Нет поддержки динамического контента
Краулер работает только с статическим контентом и не может обрабатывать страницы, генерирующие контент с помощью JavaScript.
Используйте многозадачность или многопоточность:
Использование параллелизма (через модули, такие как concurrent.futures или asyncio для асинхронного сканирования) может значительно ускорить процесс. Многопоточные программы обрабатывают несколько страниц одновременно, что повышает производительность.
Пример: aiohttp и asyncio для асинхронных запросов.
Используйте более продвинутые библиотеки:
Scrapy: самая популярная библиотека для веб-сканирования и сбора данных, включающая встроенную поддержку параллелизма, управления сессиями, обработки ошибок и других функций.
Playwright или Selenium: подходят для обработки динамических страниц, которые используют JavaScript для генерации контента.
Добавление логики проверки глубины рекурсии или ограничения числа посещаемых страниц поможет избежать зацикливания.
Введение задержек между запросами:
Добавление случайных задержек или фиксированных таймаутов между запросами помогает избежать перегрузки сервера и блокировки IP.
Улучшение обработки ошибок и логики повторных запросов:
Реализуйте механизмы повторных попыток для сетевых ошибок или ошибок на стороне сервера (например, 500 или 503). Библиотека requests поддерживает повтор через urllib3.
Использование базы данных или файловой системы для управления очередью:
Вместо хранения ссылок в оперативной памяти используйте базу данных (например, SQLite или Redis) для управления очередью, что улучшит масштабируемость.
Параллельная обработка:
Используйте библиотеки, такие как Celery или Dask, для распределённой обработки, чтобы справляться с задачами крупномасштабного сканирования.
Теперь, когда мы знаем о недостатках нашего кода и познакомились с более эффективными методами, давайте перепишем наш код, чтобы сделать его более успешным:
import logging
from urllib.parse import urljoin
import requests
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor
logging.basicConfig(
format='%(asctime)s %(levelname)s: %(message)s',
level=logging.INFO
)
class SimpleCrawler:
def __init__(self, start_urls=[]):
self.visited = set()
self.to_visit = start_urls
self.found_links = []
def fetch_page(self, url):
"""Скачать содержимое страницы."""
try:
response = requests.get(url)
response.raise_for_status()
return response.text
except requests.exceptions.RequestException as e:
logging.error(f"Не удалось загрузить {url}: {e}")
return None
def extract_links(self, url, html):
"""Извлечь и обработать все ссылки с указанной страницы."""
soup = BeautifulSoup(html, 'html.parser')
for anchor in soup.find_all('a', href=True):
link = anchor['href']
full_url = urljoin(url, link)
if full_url not in self.visited and full_url not in self.to_visit:
self.found_links.append(full_url)
def process_page(self, url):
"""Обработать одну страницу и собрать ссылки."""
html = self.fetch_page(url)
if html:
self.extract_links(url, html)
self.visited.add(url)
def crawl(self):
"""Веб-сканирование, начиная с исходных URL-адресов."""
with ThreadPoolExecutor(max_workers=10) as executor:
# Добавление начальных URL в очередь
while self.to_visit:
url = self.to_visit.pop(0)
if url not in self.visited:
executor.submit(self.process_page, url)
# Ожидание завершения обработки всех страниц
executor.shutdown(wait=True)
return self.found_links
if __name__ == '__main__':
start_urls = ['https://www.wikipedia.org/']
crawler = SimpleCrawler(start_urls)
links = crawler.crawl()
print("Найденные ссылки:")
for link in links:
print(link)Мы внесли некоторые улучшения в сканер, чтобы повысить его скорость и эффективность. Эти изменения помогут вам собирать ссылки быстрее и без ненужных задержек.
Что было изменено:
- Многозадачность: Использован ThreadPoolExecutor для параллельной загрузки страниц, что ускоряет выполнение.
- Сбор всех ссылок сразу: Все найденные ссылки сохраняются в список found_links, а результаты выводятся после обработки всех страниц.
- Удаление промежуточных выводов: Логирование для каждой страницы было удалено, чтобы ускорить выполнение.
Объяснение:
- ThreadPoolExecutor позволяет обрабатывать несколько страниц одновременно (параллельно), что значительно ускоряет процесс, особенно если страниц много.
- Список found_links хранит все ссылки, найденные на страницах. После обработки всех страниц эти ссылки выводятся.
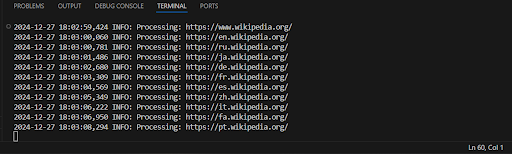
Пример вывода:
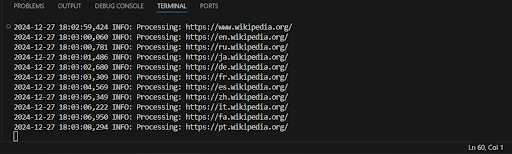
Ура, теперь наш код работает намного быстрее и выводит все найденные ссылки сразу!
После запуска веб-краулера важно сохранить собранные данные. Один из самых популярных и простых способов сохранить найденные ссылки — использование файла JSON. Формат JSON легковесный, удобный для чтения и широко используется для обмена данными. Давайте рассмотрим, как можно сохранить найденные ссылки в файл, а также обсудим несколько способов сделать это.
Вот как это можно сделать, используя пример SimpleCrawler из предыдущего кода:
import json
import logging
from urllib.parse import urljoin
import requests
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor
logging.basicConfig(
format='%(asctime)s %(levelname)s: %(message)s',
level=logging.INFO
)
class SimpleCrawler:
def __init__(self, start_urls=[]):
self.visited = set()
self.to_visit = start_urls
self.found_links = []
def fetch_page(self, url):
try:
response = requests.get(url)
response.raise_for_status()
return response.text
except requests.exceptions.RequestException as e:
logging.error(f"Failed to fetch {url}: {e}")
return None
def extract_links(self, url, html):
soup = BeautifulSoup(html, 'html.parser')
for anchor in soup.find_all('a', href=True):
link = anchor['href']
full_url = urljoin(url, link)
if full_url not in self.visited and full_url not in self.to_visit:
self.found_links.append(full_url)
def process_page(self, url):
html = self.fetch_page(url)
if html:
self.extract_links(url, html)
self.visited.add(url)
def crawl(self):
with ThreadPoolExecutor(max_workers=10) as executor:
while self.to_visit:
url = self.to_visit.pop(0)
if url not in self.visited:
executor.submit(self.process_page, url)
executor.shutdown(wait=True)
return self.found_links
def save_to_json(self, filename):
"""Сохранение найденных ссылок в файл JSON."""
with open(filename, 'w', encoding='utf-8') as file:
json.dump(self.found_links, file, ensure_ascii=False, indent=4)
logging.info(f"Found links saved to {filename}")
if __name__ == '__main__':
start_urls = ['https://www.wikipedia.org/']
crawler = SimpleCrawler(start_urls)
links = crawler.crawl()
# Сохранение ссылок в файл JSON
crawler.save_to_json('found_links.json')
print("Found links have been saved to 'found_links.json'")После выполнения код сохранит ссылки в файл found_links.json, который будет выглядеть примерно так:
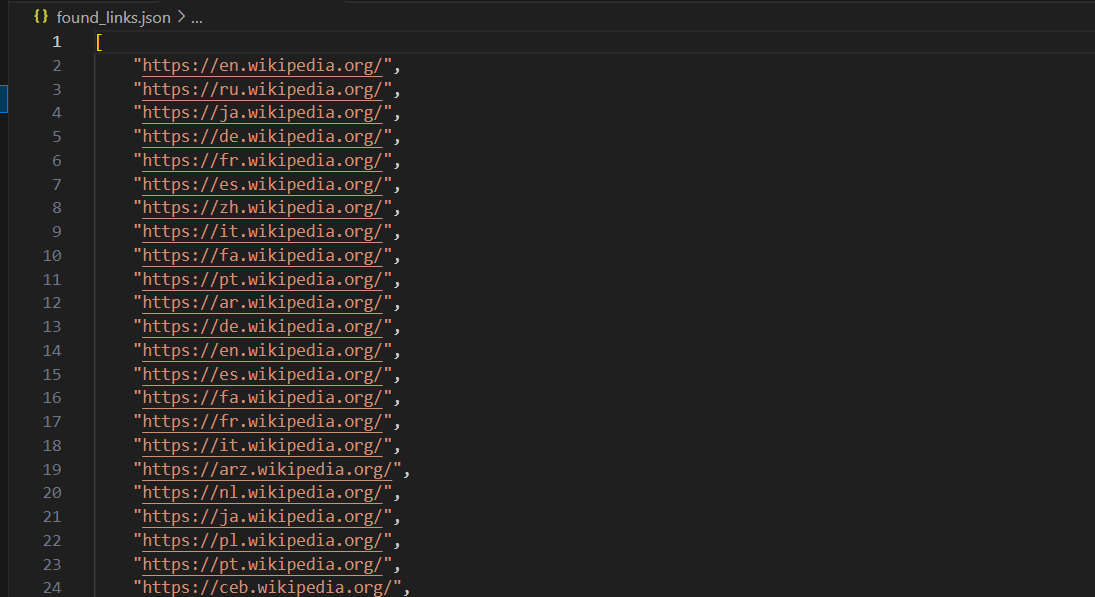
Другие способы сохранения собранных данных
Помимо сохранения ссылок в файл JSON, существуют и другие способы хранения данных, собранных при веб-сканировании. Вот несколько популярных методов:
Сохранение в файл CSV
CSV (Comma-Separated Values) — простой и широко используемый формат для хранения табличных данных. Его легко открыть в Excel или Google Таблицах.
import csv
class SimpleCrawler:
# Предыдущий код...
def save_to_csv(self, filename):
"""Сохранение найденных ссылок в файл CSV."""
with open(filename, 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(['URL']) # Заголовок столбца
for link in self.found_links:
writer.writerow([link])
logging.info(f"Found links saved to {filename}")
if __name__ == '__main__':
start_urls = ['https://www.wikipedia.org/']
crawler = SimpleCrawler(start_urls)
links = crawler.crawl()
# Сохранение ссылок в файл CSV
crawler.save_to_csv('found_links.csv')
print("Found links have been saved to 'found_links.csv'")Сохранение в базу данных (SQLite)
Если вы хотите сохранять свои ссылки в базе данных для удобного выполнения запросов, SQLite — хороший выбор. Это легковесная база данных, которая не требует отдельного сервера и хорошо подходит для хранения данных малого и среднего объема.
import sqlite3
class SimpleCrawler:
# Предыдущий код...
def save_to_database(self, db_name):
"""Сохранение найденных ссылок в базу данных SQLite."""
conn = sqlite3.connect(db_name)
cursor = conn.cursor()
# Создание таблицы, если она еще не существует
cursor.execute('''
CREATE TABLE IF NOT EXISTS links (
id INTEGER PRIMARY KEY AUTOINCREMENT,
url TEXT UNIQUE
)
''')
# Вставка каждой ссылки в базу данных
for link in self.found_links:
cursor.execute('INSERT OR IGNORE INTO links (url) VALUES (?)', (link,))
conn.commit()
conn.close()
logging.info(f"Found links saved to {db_name}")
if __name__ == '__main__':
start_urls = ['https://www.wikipedia.org/']
crawler = SimpleCrawler(start_urls)
links = crawler.crawl()
# Сохранение ссылок в базу данных
crawler.save_to_database('found_links.db')
print("Found links have been saved to 'found_links.db'")
Сохранение в файл Excel (XLSX)
Если вы предпочитаете работать с Excel, вы можете сохранить свои данные напрямую в файл Excel, используя библиотеку openpyxl.
from openpyxl import Workbook
class SimpleCrawler:
# Предыдущий код...
def save_to_excel(self, filename):
"""Сохранение найденных ссылок в файл Excel."""
workbook = Workbook()
sheet = workbook.active
sheet.append(['URL']) # Заголовок столбца
for link in self.found_links:
sheet.append([link])
workbook.save(filename)
logging.info(f"Found links saved to {filename}")
if __name__ == '__main__':
start_urls = ['https://www.wikipedia.org/']
crawler = SimpleCrawler(start_urls)
links = crawler.crawl()
# Сохранение ссылок в файл Excel
crawler.save_to_excel('found_links.xlsx')
print("Found links have been saved to 'found_links.xlsx'")Теперь давайте создадим краулер для сайта Amazon.com с использованием Scrapy (перед началом ознакомьтесь с документацией).
- Откройте страницу результатов поиска Amazon (например, https://www.amazon.com/s?k=phones) в вашем браузере.
- Нажмите правой кнопкой мыши на любой части страницы и выберите «Inspect» (или нажмите Ctrl+Shift+I на Windows/Linux или Cmd+Option+I на Mac). Это откроет окно DevTools, где можно изучить структуру страницы.
- Теперь найдите элементы, которые вам нужно извлечь, изучая HTML-код. Наведите курсор на название продукта на странице Amazon. В DevTools соответствующий HTML будет подсвечен. Нажмите правой кнопкой мыши на названии продукта и выберите «Inspect».
- Обратите внимание на теги и атрибуты классов. Например, название продукта может находиться в <span> внутри тега ссылки (<a>) и иметь определённый класс (например, a-text-normal). В данном случае CSS-селектор для извлечения названия продукта будет следующим: a.a-link-normal.s-line-clamp-2.a-text-normal span::text.
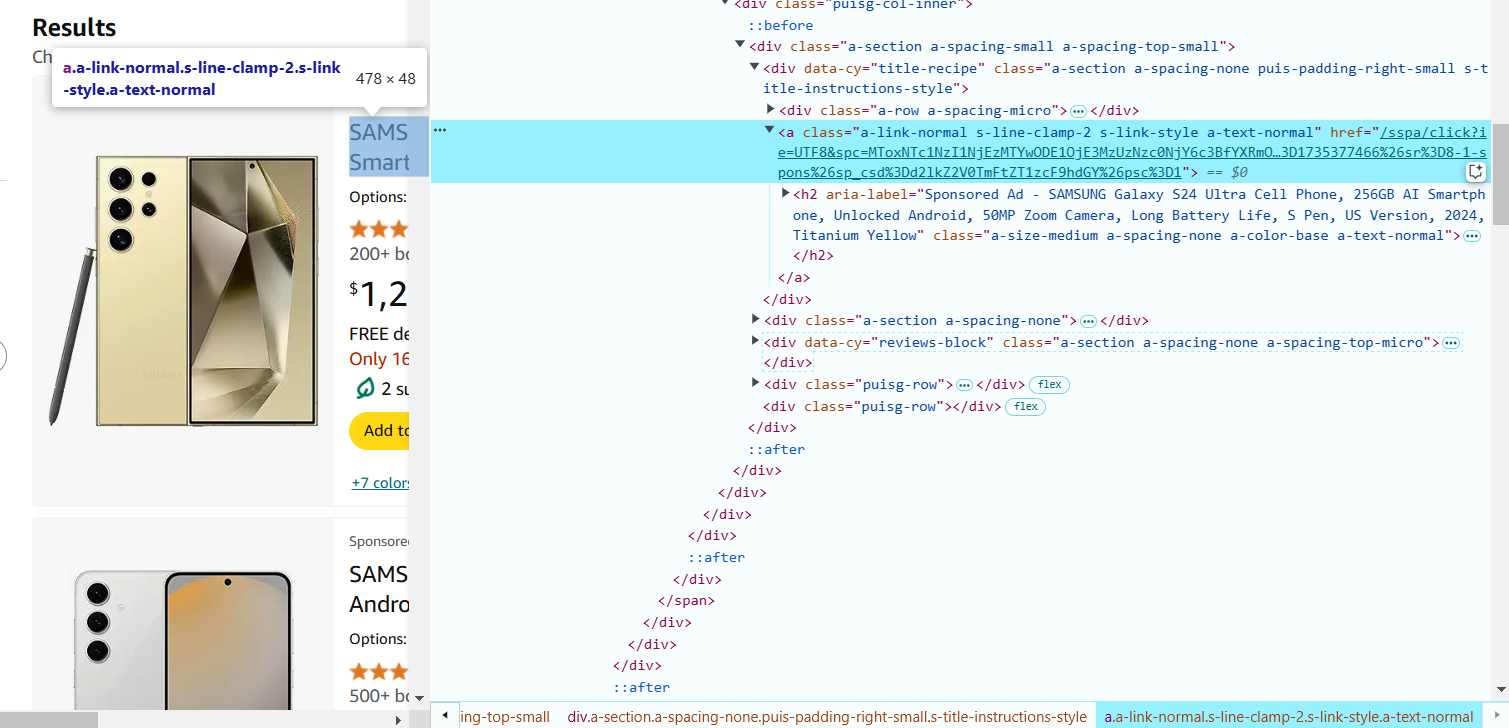
- Наведите курсор на цену продукта на странице и нажмите правой кнопкой мыши, чтобы выбрать «Inspect». Цена может находиться в теге <span> с классом, например, a-price-whole.
CSS-селектор для извлечения цены: span.a-price-whole::text.
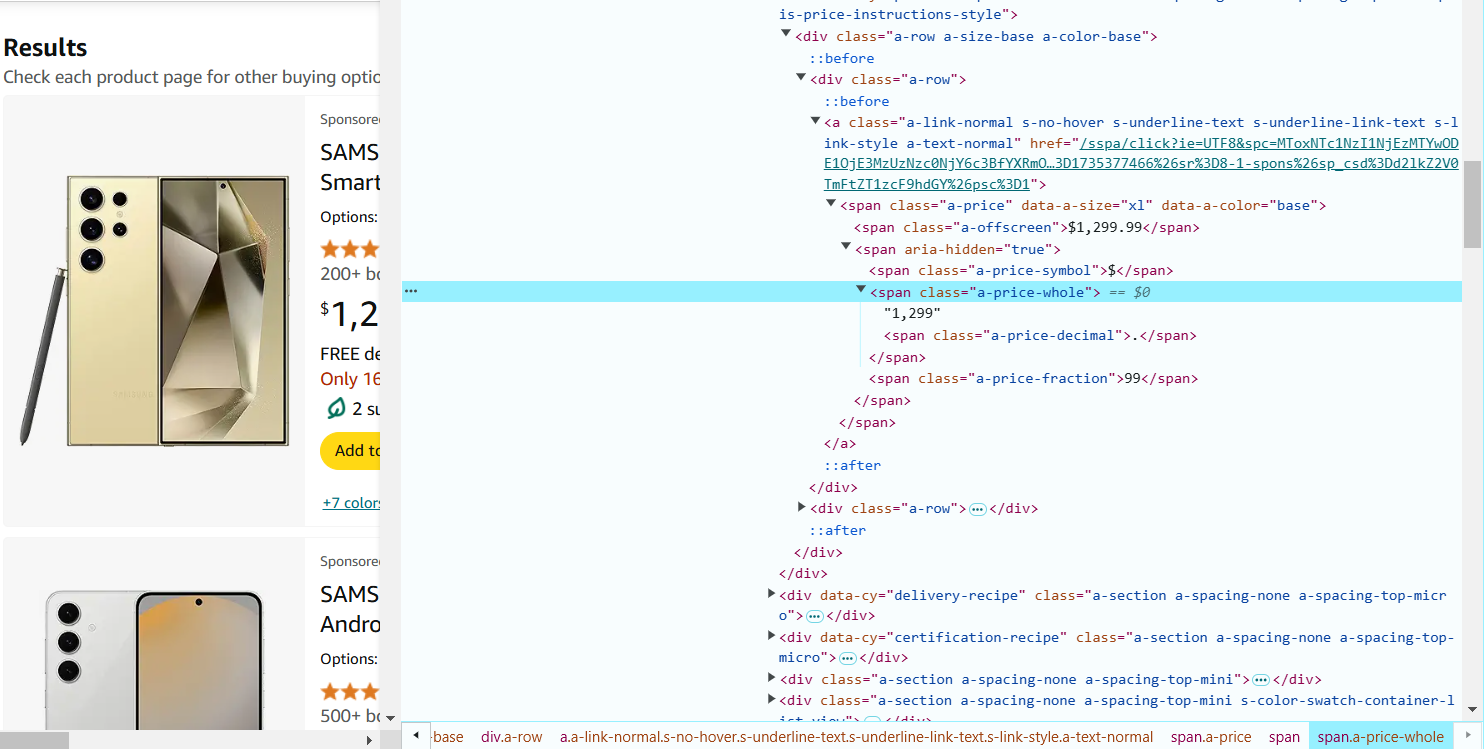
- Наведите курсор на рейтинг продукта (звезды) и нажмите правой кнопкой мыши, чтобы выбрать «Inspect».
Рейтинг обычно находится в теге <i> с классом, например, a-icon-star-small.
CSS-селектор для извлечения рейтинга: i.a-icon-star-small span.a-icon-alt::text.
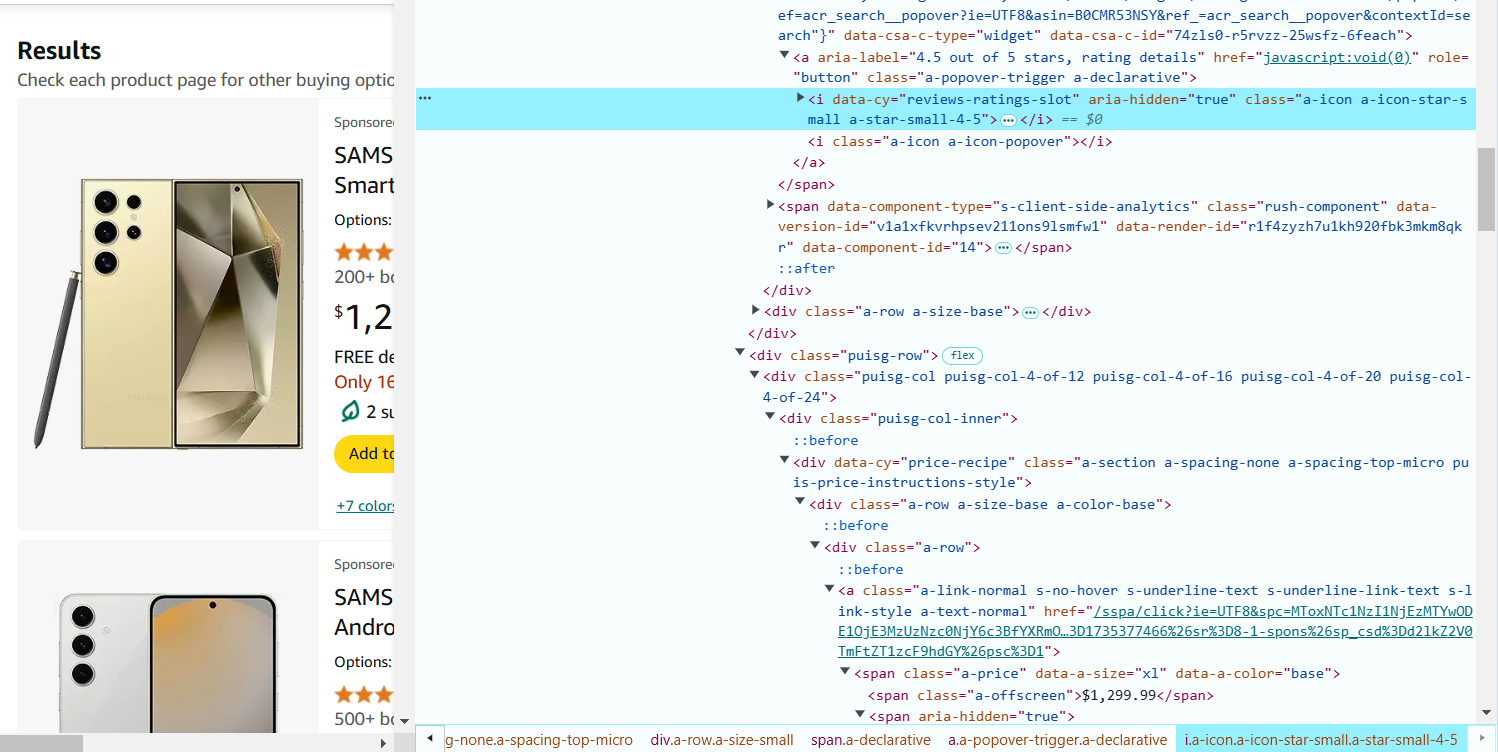
- Наведите курсор на количество отзывов и нажмите правой кнопкой мыши, чтобы выбрать «Inspect».
Количество отзывов находится в теге <span> с классом a-size-base.s-underline-text.
CSS-селектор для извлечения количества отзывов: span.a-size-base.s-underline-text::text.
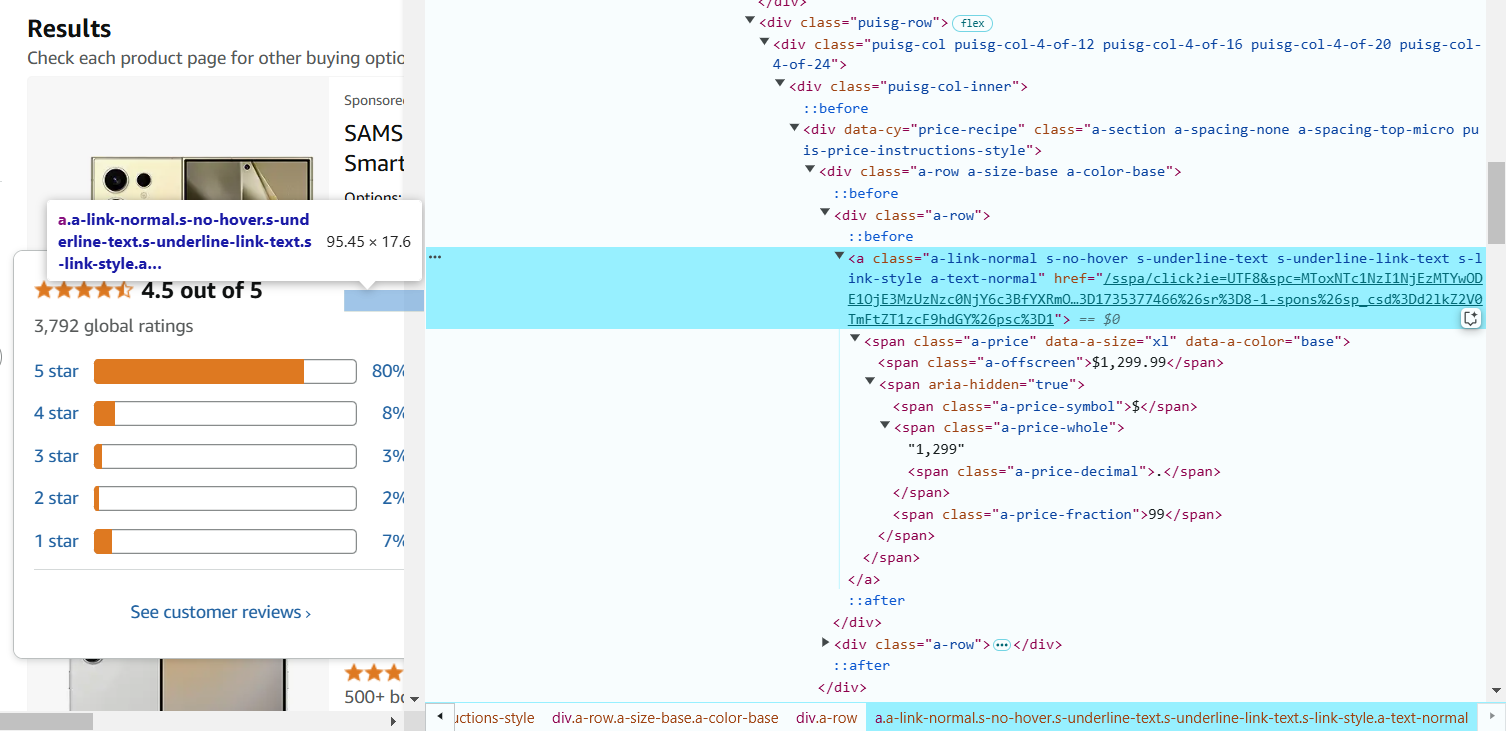
- Наведите курсор на название продукта и нажмите правой кнопкой мыши, чтобы выбрать «Inspect».
Ссылка находится в теге <a>, а URL — в атрибуте href.
CSS-селектор для извлечения URL продукта: a.a-link-normal.s-line-clamp-2.s-link-style::attr(href). - Создание паука Scrapy
Теперь, когда у вас есть необходимые CSS-селекторы, вы можете использовать их в пауке Scrapy для извлечения данных.
import scrapy
class AmazonSpider(scrapy.Spider):
name = "ecommerce"
# Начальный URL
start_urls = [
'https://www.amazon.com/s?k=phones'
]
def parse(self, response):
# Добавление лога для отладки
self.log(f"Parsing page: {response.url}")
# Извлечение деталей продукта
for product in response.css('div.s-main-slot div.s-result-item'):
# Извлечение названия продукта
name = product.css('a.a-link-normal.s-line-clamp-2.a-text-normal span::text').get()
if name: # Проверка наличия названия продукта
self.log(f"Found product: {name}")
# Извлечение цены (может отсутствовать у некоторых продуктов)
price = product.css('span.a-price-whole::text').get()
# Извлечение рейтинга (может отсутствовать у некоторых продуктов)
rating = product.css('i.a-icon-star-small span.a-icon-alt::text').get()
# Извлечение количества отзывов
reviews = product.css('span.a-size-base.s-underline-text::text').get()
# Извлечение URL продукта
product_url = product.css('a.a-link-normal.s-line-clamp-2.s-link-style::attr(href)').get()
yield {
'name': name,
'price': price,
'rating': rating,
'reviews': reviews,
'url': response.urljoin(product_url),
}
# Переход на следующую страницу
next_page = response.css('li.a-last a::attr(href)').get()
if next_page:
self.log(f"Following next page: {next_page}")
yield response.follow(next_page, self.parse)Объяснение кода:
start_urls: это URL, с которого начинается парсинг. В данном случае это результаты поиска на Amazon для телефонов.
Метод parse: этот метод используется для извлечения данных из HTML-ответа. Он использует CSS-селекторы для нахождения нужных элементов.
product.css('selector::text'): это извлекает текстовое содержимое из элементов, соответствующих селектору.
product.css('selector::attr(href)'): это извлекает атрибут href (URL) из тега <a>.
Пагинация: паук переходит по ссылке на следующую страницу, используя ссылку next_page. Это гарантирует, что паук соберет все страницы с продуктами.
Запуск паука
После создания паука сохраните файл в каталоге spiders вашего проекта Scrapy (например, amazon_spider.py).
scrapy crawl ecommerce -o products.jsonВ сохраненном файле извлеченная информация должна выглядеть примерно так:
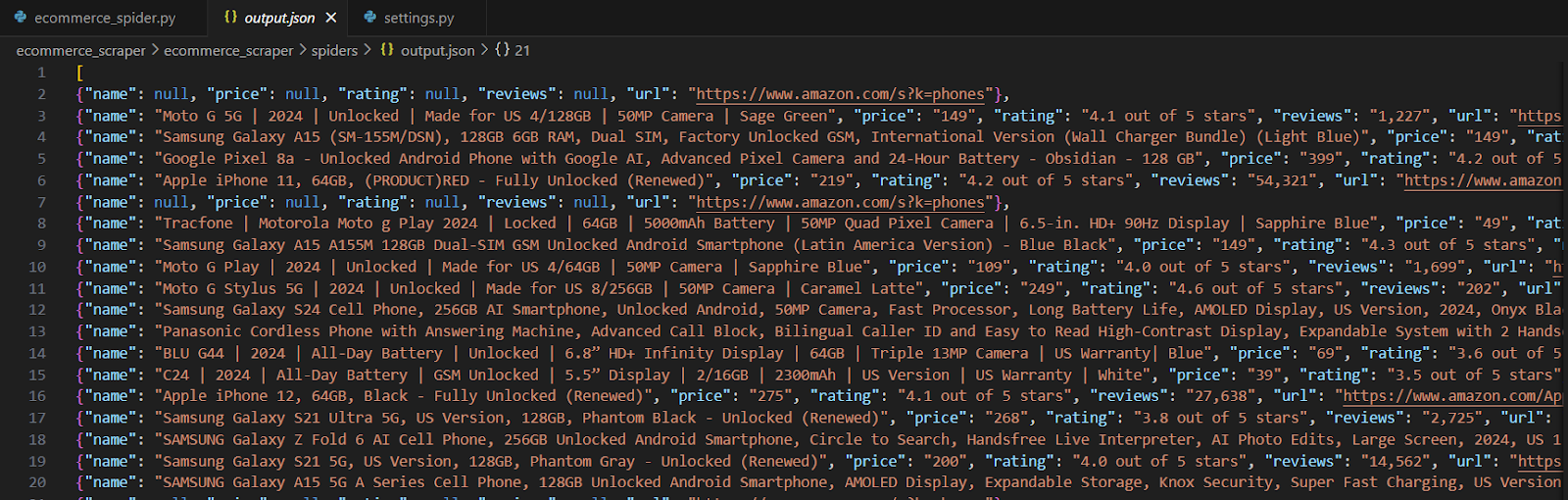
Важные замечания:
Настоящие сайты электронной коммерции, такие как Amazon, eBay и другие, имеют более сложные механизмы защиты от парсинга, включая CAPTCHA, ограничение частоты запросов и динамический контент. Чтобы парсить реальные сайты, необходимо учитывать эти факторы.
- Всегда проверяйте файл robots.txt сайта и убедитесь, что вы соблюдаете его политику парсинга. Парсинг должен проводиться этично, с уважением к условиям использования сайта, чтобы не перегружать его серверы излишними запросами. Также важно удостовериться, что любые данные, которые вы собираете, используются в соответствии с законами и регламентами о конфиденциальности, такими как GDPR.
- Реальные сайты часто используют сервисы, такие как reCAPTCHA, DataDome или Cloudflare, чтобы предотвратить автоматический парсинг. В таких случаях вы можете интегрировать инструменты, такие как CapMonster Cloud, чтобы автоматически обходить CAPTCHA. CapMonster Cloud предоставляет простой API для решения различных CAPTCHA, включая Google reCAPTCHA, Geetest и другие.
- Сайты могут отслеживать активность парсинга, анализируя отпечатки браузера, такие как User-Agent, Accept-Language и другие заголовки. Чтобы избежать обнаружения, вы должны менять эти отпечатки (например, с помощью сервиса, такого как BrowserStack или ProxyCrawl) или использовать настраиваемые заголовки и динамические прокси.
- Кроме того, использование ротации IP-адресов и сервисов прокси (например, ScraperAPI или ProxyMesh) может помочь избежать блокировки за слишком большое количество запросов с одного IP-адреса.
Вот пример динамического веб-краулинга с использованием Playwright. Этот скрипт извлекает последние новости с Hacker News (https://news.ycombinator.com/), популярного сайта новостей технологий, который загружает контент динамически с помощью JavaScript.
Зачем это использовать?
Этот подход идеально подходит для сайтов, которые не показывают весь свой контент сразу (они загружают его с помощью JavaScript). Playwright помогает вам действовать как реальный пользователь, давая возможность подождать, пока контент загрузится, прежде чем забрать данные. Это отличный инструмент для современных динамических сайтов!
- Установка Playwright
Если вы еще не установили, выполните следующие команды в вашем терминале:
pip install playwright
playwright installДля загрузки только Chromium:
pip install playwright
playwright install chromium- Пример кода:
from playwright.sync_api import sync_playwright
def dynamic_crawler():
with sync_playwright() as p:
# Запуск браузера
browser = p.chromium.launch(headless=True)
page = browser.new_page()
# Переход на сайт
url = "https://news.ycombinator.com/"
page.goto(url)
# Ожидание загрузки новостей
page.wait_for_selector(".athing")
# Извлечение данных
articles = []
for item in page.query_selector_all(".athing"):
title = item.query_selector(".titleline a").inner_text()
link = item.query_selector(".titleline a").get_attribute("href")
rank = item.query_selector(".rank").inner_text() if item.query_selector(".rank") else None
articles.append({"rank": rank, "title": title, "link": link})
browser.close()
# Печать результатов
for article in articles:
print(article)
# Запуск краулера
dynamic_crawler()Что делает код
- Запуск браузера:
- chromium.launch() запускает легковесный браузер в фоновом режиме (параметр headless=True означает, что окно браузера не появится).
- Переход на сайт:
- page.goto(url) переходит на Hacker News.
- Ожидание контента:
- page.wait_for_selector(".athing") ждет, пока статьи загрузятся.
- Извлечение данных:
- Код ищет все новости, используя CSS-класс .athing.
- Для каждого элемента он извлекает:
- Рейтинг (например, "1.")
- Название новости
- Ссылку на полный текст статьи.
- Закрытие браузера:
- Браузер закрывается после сбора данных.
- Показ результатов:
- Каждая статья выводится как небольшой словарь с такими ключами, как рейтинг, название и ссылка.
Пример вывода
После выполнения скрипта в вашем терминале будет что-то вроде этого:
{'rank': '1.', 'title': 'A great open-source project', 'link': 'https://example.com'}
{'rank': '2.', 'title': 'How to learn Python', 'link': 'https://news.ycombinator.com/item?id=123456'}
{'rank': '3.', 'title': 'Show HN: My new tool', 'link': 'https://example.com/tool'}Веб-краулинг с помощью Python — это отличный способ собирать данные с веб-сайтов и выявлять ценные инсайты. Используя такие инструменты, как BeautifulSoup, Scrapy и Playwright, вы можете работать с простыми статичными сайтами и более сложными динамическими. Примеры, которые мы рассмотрели, показывают, как извлекать данные и справляться с такими проблемами, как контент на JavaScript и ограничения сайтов.
Если необходимо обойти блокировки, методы, такие как использование прокси-серверов или решение CAPTCHA, могут помочь, но важно применять их этично.
С Python и правильными инструментами веб-краулинг становится увлекательным и мощным навыком. Независимо от того, начинаете ли вы или уже имеете некоторый опыт, можно достичь отличных результатов и сделать свои проекты яркими. Удачи и наслаждайтесь процессом краулинга!