Если вы оказались на этой странице, вероятно, вы уже знакомы с концепцией веб-скрапинга на Java и хотите углубиться в детали. Отлично, вы на правильном пути! В этом руководстве мы объясним основы веб-скрапинга на Java простым и доступным языком, а также продемонстрируем, как извлекать данные с реального сайта, включая как статичные, так и динамичные элементы. Всё, что нужно для быстрого и удобного старта в сборе необходимой информации, собрано здесь. Так что давайте начнём!
Веб-скрапинг можно представить как отправку цифрового помощника, который собирает информацию с веб-сайтов. Представьте, что вы просматриваете интернет, копируете текст или собираете изображения, но вместо того, чтобы делать это вручную, программу, которая делает это за вас, гораздо быстрее и эффективнее. С помощью веб-скрапинга вы можете извлекать полезные данные, такие как цены, отзывы или контактные данные, и сохранять их в удобном для вас формате, например, в электронной таблице или базе данных.
Это мощный инструмент, используемый в таких областях, как исследование рынка, конкурентный анализ и агрегация данных. Независимо от того, являетесь ли вы новичком или опытным разработчиком, веб-скрапинг может упростить процесс сбора и организации информации с интернета.
Java — отличный выбор для веб-скрапинга, и вот почему:
Надёжность и производительность: Java известна своей высокой производительностью и способностью справляться с комплексными задачами. Независимо от того, скрапите ли вы небольшие сайты или крупномасштабные приложения, Java обеспечит стабильность, необходимую для получения постоянных результатов.
Обширные библиотеки: с такими библиотеками, как Jsoup для парсинга HTML и Selenium для взаимодействия с динамичными веб-страницами, Java предоставляет все необходимые инструменты для веб-скрапинга.
Кроссплатформенность: напишите код один раз и запускайте его где угодно. Платформенная независимость Java означает, что вы можете разрабатывать скрипты для скрапинга на одной операционной системе и без проблем запускать их на другой.
Многозадачность и масштабируемость: возможности многозадачности Java позволяют скрапить несколько страниц одновременно, экономя время и повышая эффективность.
Сообщество и поддержка: широкое распространение Java означает, что существует огромное сообщество разработчиков, готовых предоставить поддержку, поделиться решениями и дать советы.
Выбирая Java, вы выбираете язык, который является универсальным, мощным и хорошо поддерживаемым — идеально подходящим для выполнения проектов по веб-скрапингу любого масштаба!
Для успешного веб-скрапинга на Java существует несколько мощных инструментов и библиотек, которые помогут вам эффективно собирать данные с веб-страниц. Давайте рассмотрим некоторые популярные варианты:
Jsoup
Jsoup — одна из самых популярных библиотек для парсинга HTML в Java. Она предоставляет простой и интуитивно понятный API для извлечения данных из HTML-документов. Если вам нужно быстро получить информацию с веб-страницы и работать с DOM (моделью объекта документа), Jsoup — идеальный выбор.
Преимущества:
- Лёгкость в использовании.
- Поддержка парсинга HTML и работы с CSS-селекторами.
- Позволяет очищать HTML от мусора и ненужных тегов.
- Простой API для получения элементов и их атрибутов.
Apache HttpClient
Apache HttpClient — это библиотека, которая помогает работать с HTTP-запросами, предлагая такие возможности, как обработка cookies, заголовков и аутентификация. Если вам нужно просто отправлять запросы и извлекать данные с сайта (без обработки JavaScript), это отличный вариант.
Преимущества:
- Гибкость в настройке HTTP-запросов.
- Возможность работы с различными HTTP-методами (GET, POST, PUT и т.д.).
- Хорошо интегрируется с другими библиотеками для обработки данных.
HtmlUnit
HtmlUnit — это «безголовый» браузер, который позволяет взаимодействовать с веб-страницами без необходимости запускать реальный браузер. Он идеально подходит для тестирования и скрапинга сайтов, где визуальная отрисовка не требуется.
Преимущества:
- Лёгкость (не требуется графический интерфейс).
- Подходит для скрапинга динамичных страниц (поддерживает JavaScript).
- Высокая производительность.
Selenium WebDriver
Selenium — это популярный инструмент для автоматизации браузеров. Он идеально подходит для скрапинга динамичных страниц, где данные загружаются с использованием JavaScript. С помощью Selenium вы можете управлять браузером, симулировать действия пользователя (клики, ввод текста) и извлекать нужную информацию.
Преимущества:
- Подходит для динамичных сайтов (где данные загружаются через JavaScript).
- Поддерживает несколько браузеров (Chrome, Firefox, Safari и другие).
- Возможность симулировать поведение реального пользователя.
Эти библиотеки и инструменты предоставляют мощные возможности для работы с веб-страницами и сбора данных. В зависимости от ваших задач, вы можете выбрать один или несколько из них. Например, для простого парсинга HTML отличным выбором будет Jsoup, в то время как для динамичных страниц лучше подойдут Selenium или HtmlUnit. Ваш выбор зависит от сложности проекта и того, как данные загружаются на целевых сайтах.
Вот обзор лучших редакторов и IDE для веб-скрапинга на Java, а также плюсы и минусы каждого из них:
IntelliJ IDEA
IntelliJ IDEA — одна из самых популярных и мощных IDE для разработки на Java. Она предлагает множество функций, которые могут быть полезны для веб-скрапинга.
Преимущества:
- IntelliJ понимает контекст кода, предоставляя точные предложения и исправления.
- Поддерживает все популярные системы сборки (Maven, Gradle) и фреймворки.
- Мощный и удобный инструмент для отладки.
- Предлагает плагины для работы с базами данных, Docker, тестированием и многим другим.
- Простой в использовании и интуитивно понятный интерфейс.
Недостатки:
- Может требовать значительных системных ресурсов, особенно на старых или менее мощных компьютерах.
- Хотя существует бесплатная версия Community, некоторые функции доступны только в платной версии Ultimate.
Особенности:
Подходит для разработчиков, работающих над сложными проектами или в командах, так как предоставляет мощные инструменты для рефакторинга и совместной работы.
- Eclipse
Eclipse — одна из старейших и самых известных IDE для Java. Она предлагает широкий набор функций для разработки на Java и других языках.
Преимущества:
- Eclipse — бесплатная IDE с возможностью её модификации.
- Огромное количество плагинов и расширений.
- Подходит для разработки крупных приложений.
Недостатки:
- Интерфейс Eclipse не так удобен для пользователя, как у IntelliJ IDEA.
- Некоторые операции могут быть медленными, особенно при использовании множества плагинов или больших проектов.
Особенности:
Eclipse больше подходит для опытных разработчиков, которым нужно больше настроек и расширений. Новичкам интерфейс может показаться запутанным.
- JDeveloper
JDeveloper — это IDE от Oracle, предназначенная для разработки на Java EE (Enterprise Edition).
Преимущества:
- Полная интеграция с продуктами Oracle, что делает её идеальным выбором для разработки на Java EE.
- Включает инструменты для работы с базами данных, веб-сервисами и многими другими технологиями.
Недостатки:
- По сравнению с Eclipse или IntelliJ IDEA, у JDeveloper меньшее сообщество пользователей.
- Она может быть менее удобной для разработчиков, работающих вне экосистемы Java EE.
Особенности:
Лучше всего подходит для крупных проектов на Java EE, особенно если вы работаете с продуктами Oracle.
- Apache NetBeans
Apache NetBeans — это улучшенная версия NetBeans, поддерживаемая Apache Software Foundation.
Преимущества:
- В отличие от старой версии, эта версия активно поддерживается и развивается.
- Полностью бесплатная и с открытым исходным кодом.
Недостатки:
- Не так популярна, как IntelliJ IDEA или Eclipse: у неё меньше ресурсов и документации по сравнению с другими IDE.
- Может быть медленной: иногда работает медленнее, чем другие инструменты.
Особенности:
Отличный выбор для тех, кто ищет бесплатную, с открытым исходным кодом IDE для разработки на Java, но не нуждается в максимальной производительности или большом количестве плагинов.
- Visual Studio Code (VS Code)
VS Code — это лёгкий редактор с множеством плагинов, что делает его подходящим для работы с различными языками программирования, включая Java.
Преимущества:
- Работает быстро и не потребляет много ресурсов.
- Для Java доступны плагины для таких функций, как автодополнение, отладка и многое другое.
- Удобный интерфейс: очень настраиваемый и простой в использовании.
Недостатки:
- Не является полноценной IDE: по сравнению с IntelliJ IDEA или Eclipse, VS Code не предлагает все функции IDE, такие как мощный рефакторинг или управление крупными проектами.
- Может не иметь всех необходимых функций для крупных Java-проектов.
Особенности:
Идеален для небольших и средних проектов, а также для быстрого прототипирования. Отлично подходит для разработчиков, которые ценят простоту и скорость.
Теперь, когда мы познакомились с основными и наиболее популярными инструментами для веб-скрапинга на Java, давайте выберем тот, который лучше всего подходит для наших нужд, и перейдём к подготовке для веб-скрапинга. Для нашего примера мы выберем IntelliJ IDEA и Jsoup.
1. Установка IntelliJ IDEA
- Перейдите на официальный сайт IntelliJ IDEA.
- Download and install the Community Edition (free) or the Ultimate Edition (paid).
2. Создание нового проекта
- Откройте IntelliJ IDEA и выберите «New Project».
- Выберите Java как тип проекта.
- Убедитесь, что для Project SDK выбрана соответствующая версия Java (Java 8 или выше).
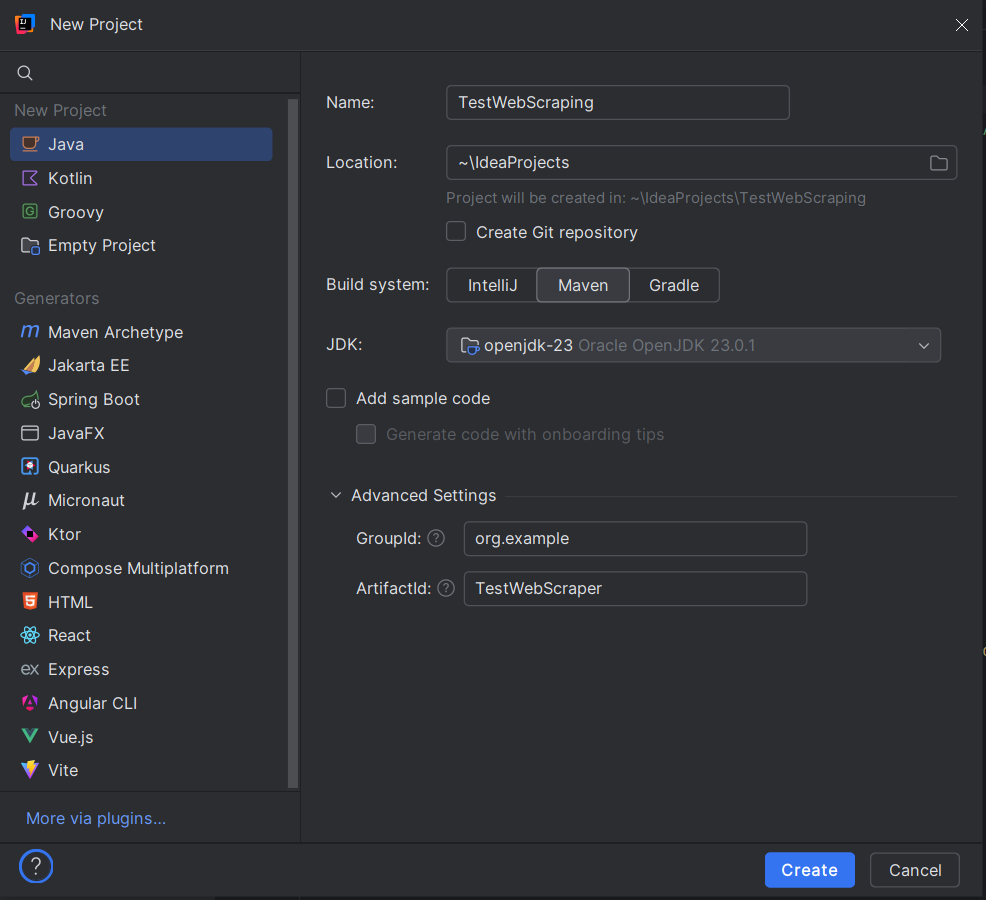
3. Настройка имени и расположения проекта
- Введите название для вашего проекта (например, TestWebScraping).
- Выберите расположение для файлов проекта.
- При создании проекта в IntelliJ IDEA выберите Maven. В появившемся диалоге:
- GroupId: укажите уникальный идентификатор для вашего проекта, например, org.example.
- ArtifactId: это название вашего проекта, например, TestWebScraper.
- Нажмите «Create».
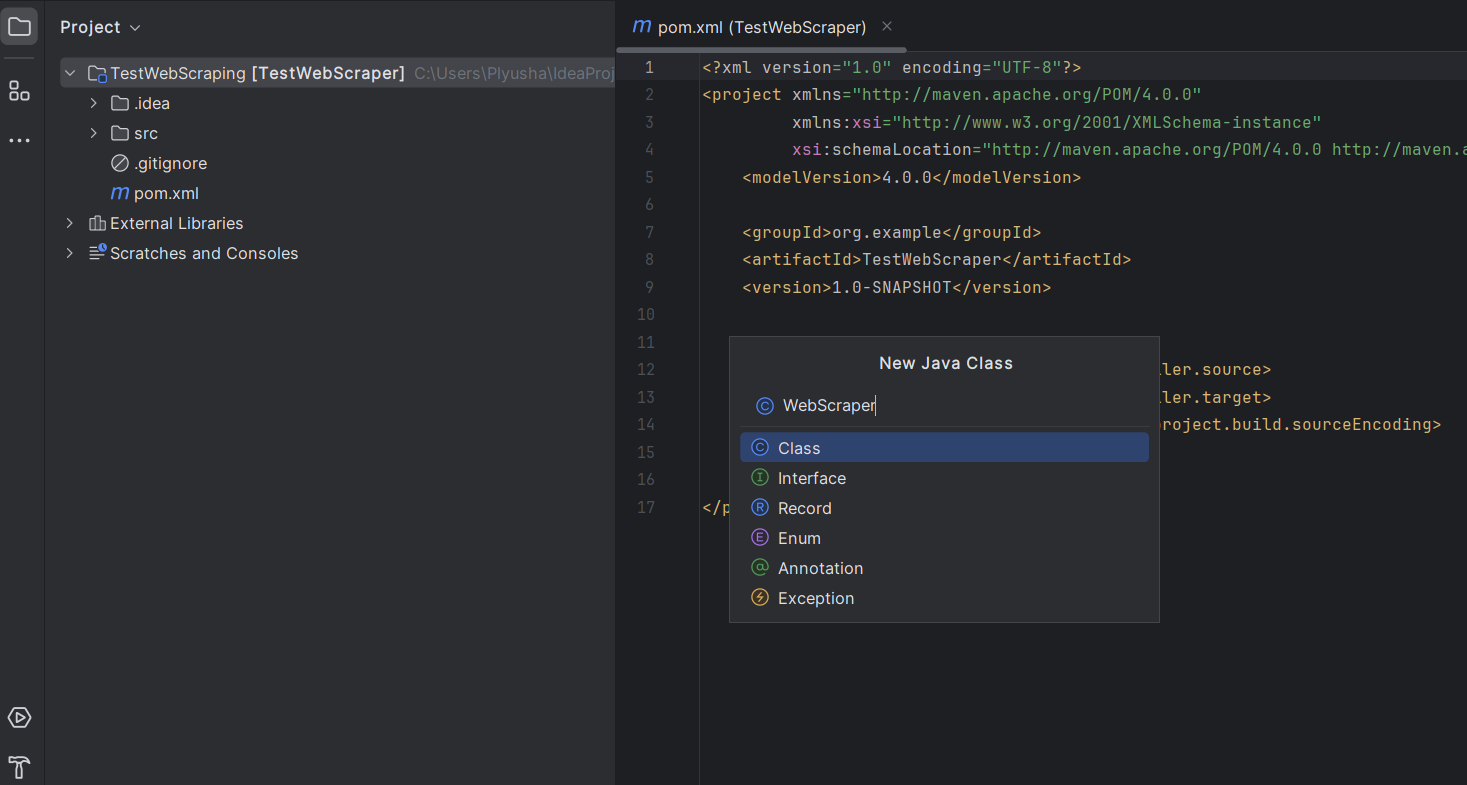
4. Настройка структуры проекта
После создания проекта IntelliJ IDEA автоматически откроет структуру проекта.
- Создайте класс Java в этом пакете: щелкните правой кнопкой мыши на вашем новом пакете и выберите New -> Java Class.
- Назовите его WebScraper или любым другим названием по вашему выбору.
5. Добавление зависимостей
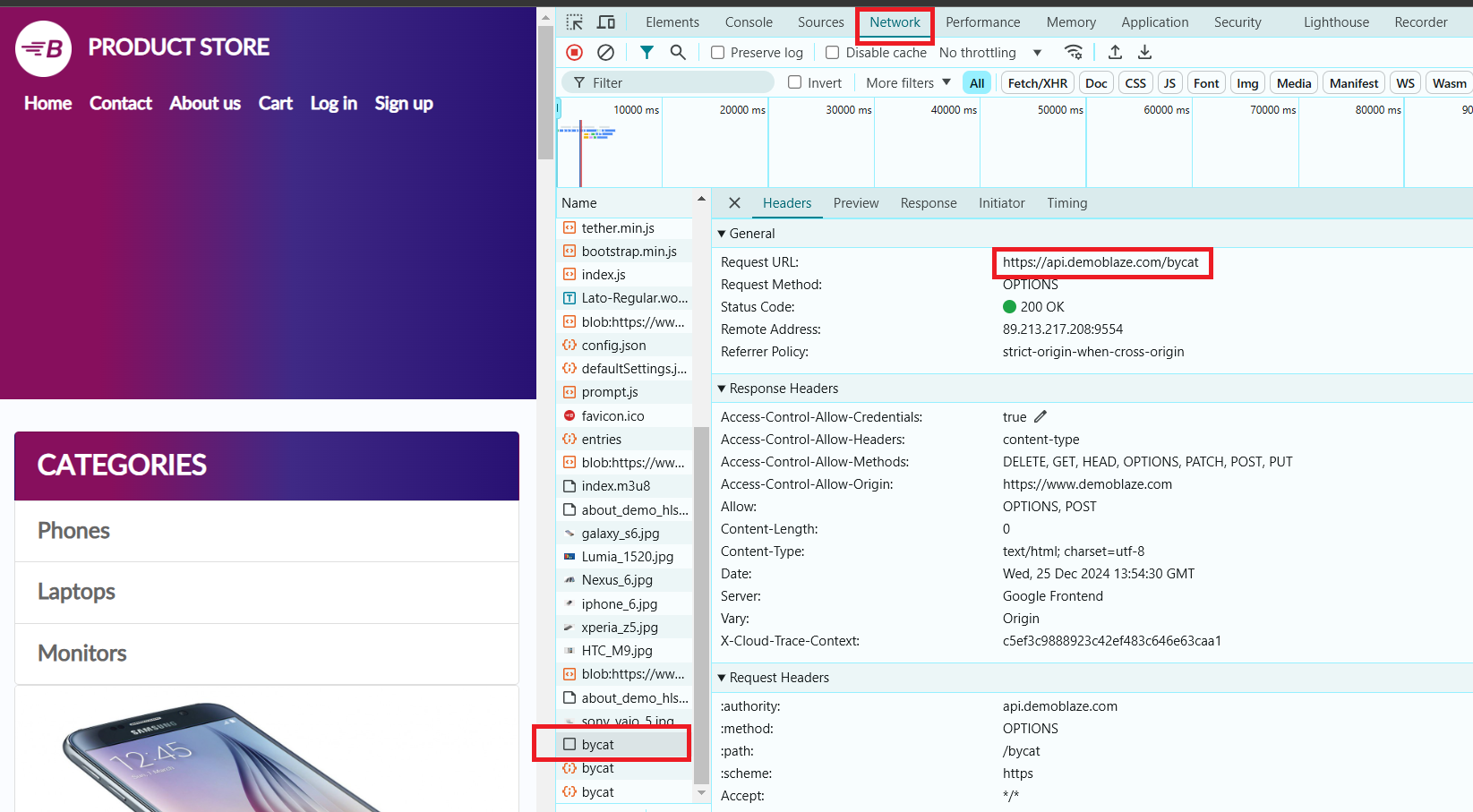
В нашем примере мы будем использовать сайт https://www.demoblaze.com/#. Поскольку сайт отображает контент с использованием JavaScript, Jsoup не сможет напрямую извлечь данные. Однако сайт использует API, которое можно вызвать напрямую для получения информации о продуктах.
При анализе сайта Demoblaze было установлено, что данные о продуктах загружаются через динамичные запросы, а не в статичном HTML. API https://api.demoblaze.com/bycat — это внутренний API, используемый для получения данных о продуктах на сайте.
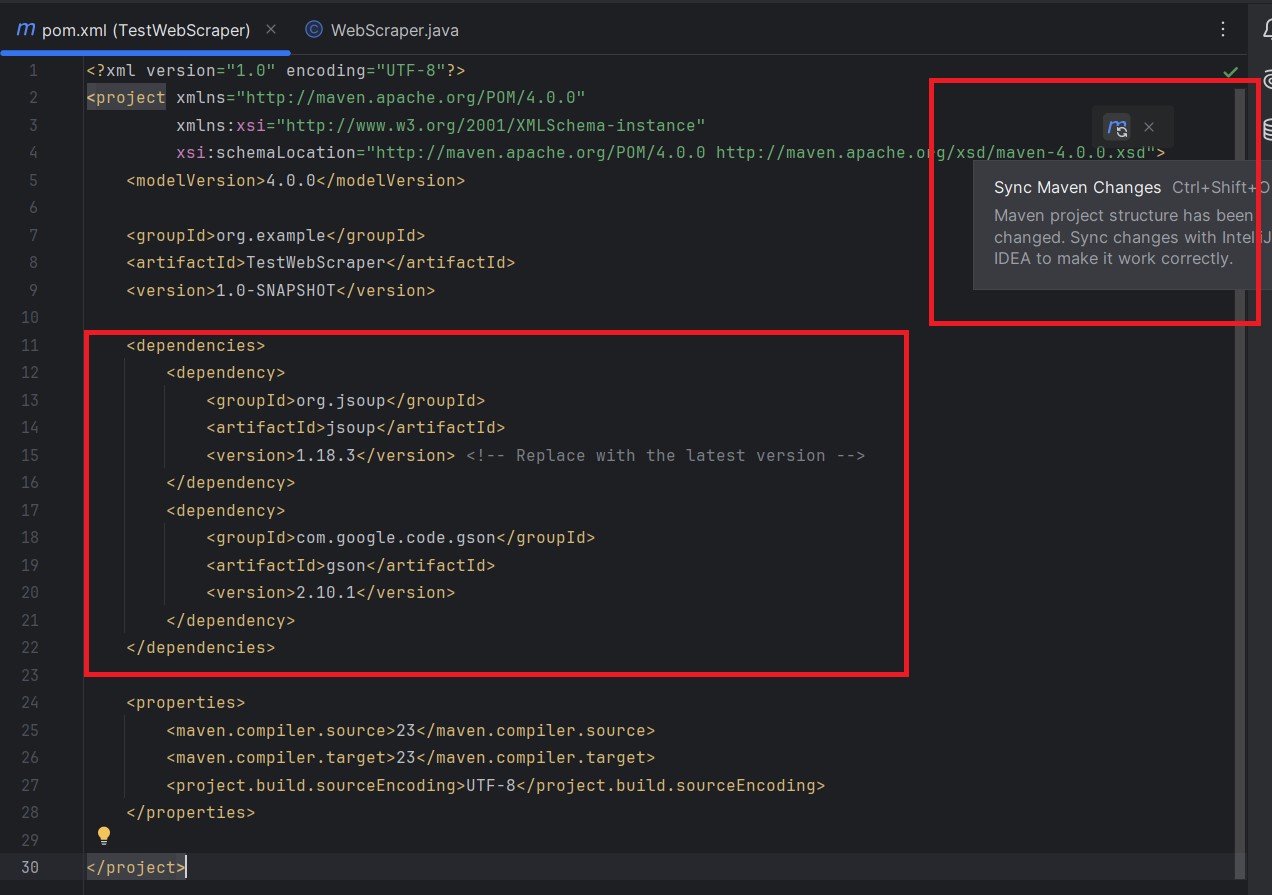
Затем вам нужно будет добавить библиотеки Jsoup и Gson в ваш проект.
В файле pom.xml добавьте следующие зависимости для Jsoup и Gson внутри секции <dependencies>:
<dependencies>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.18.3</version> <!-- Replace with the latest version -->
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.10.1</version>
</dependency>
</dependencies>Не забудьте синхронизировать изменения Maven:
Давайте попробуем извлечь название и цену каждого продукта с выбранной страницы. Но сначала давайте исследуем элементы на странице.
- Откройте DevTools (нажмите клавишу F12 в большинстве браузеров).
- Выберите категорию «Phones». В вкладке «Network» появится API-запрос, который мы будем использовать для извлечения необходимых данных.
Этот API принимает POST-запрос с телом в формате JSON, в котором указывается категория продукта, например, и отвечает JSON-объектом, содержащим массив элементов в ключе «Items». Каждый элемент имеет такие свойства, как «title» и «price».
Теперь давайте перейдём к написанию кода для нашего веб-скрапера!
1. Перед тем как начать, ознакомьтесь с документацией по Jsoup и Gson.
2. Откройте ранее созданный класс WebScraper.java и импортируйте все необходимые зависимости:
import com.google.gson.Gson;
import com.google.gson.JsonArray;
import com.google.gson.JsonObject;
import java.io.OutputStream;
import java.net.HttpURLConnection;
import java.net.URI;
import java.net.URL;
import java.nio.charset.StandardCharsets;
import java.util.Scanner;3. Основной метод:
public class WebScraper {
public static void main(String[] args) {
try {
// API URL
String apiUrl = "https://api.demoblaze.com/bycat";
// Request parameter for product category
String category = "phone"; // Can be changed to "laptop", "monitor", etc.
// Fetch response from API
String jsonResponse = fetchApiResponse(apiUrl, category);
// Parse the JSON response
Gson gson = new Gson();
JsonObject responseObject = gson.fromJson(jsonResponse, JsonObject.class);
JsonArray items = responseObject.getAsJsonArray("Items");
// Output product information
for (int i = 0; i < items.size(); i++) {
JsonObject item = items.get(i).getAsJsonObject();
String title = item.get("title").getAsString();
String price = item.get("price").getAsString();
System.out.println("Product: " + title);
System.out.println("Price: $" + price);
System.out.println("-----------------------");
}
} catch (Exception e) {
System.err.println("An error occurred: " + e.getMessage());
}
}
}API URL: переменная apiUrl содержит конечную точку API, которая возвращает детали продукта в зависимости от указанной категории.
Категория: переменная category используется для указания категории продукта, чтобы отфильтровать запрос API (по умолчанию это "phones", но можно изменить на "laptops", "monitors" и т.д.).
Получение ответа от API: метод fetchApiResponse() вызывается для отправки POST-запроса к API и получения ответа в виде строки JSON.
Парсинг JSON-ответа:
Для парсинга JSON-ответа используется Gson, который преобразует его в объект JsonObject.
Ожидается, что в JSON-ответе будет массив элементов под ключом "Items".
Цикл по элементам: цикл for проходит по массиву продуктов (items) в JSON, извлекает название и цену каждого элемента и выводит их в консоль.
4. Метод: fetchApiResponse
private static String fetchApiResponse(String apiUrl, String category) throws Exception {
URI uri = new URI(apiUrl);
URL url = uri.toURL();
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("POST");
connection.setRequestProperty("Content-Type", "application/json");
connection.setDoOutput(true);
// Request body
String jsonInputString = "{\"cat\":\"" + category + "\"}";
try (OutputStream os = connection.getOutputStream()) {
byte[] input = jsonInputString.getBytes(StandardCharsets.UTF_8);
os.write(input, 0, input.length);
}
// Read the response
StringBuilder response = new StringBuilder();
try (Scanner scanner = new Scanner(connection.getInputStream(), StandardCharsets.UTF_8)) {
while (scanner.hasNextLine()) {
response.append(scanner.nextLine());
}
}
return response.toString();
}Пояснение каждой части:
- Создание URI и URL:
Объекты URI и URL создаются из предоставленного API URL (apiUrl). Это позволяет программе установить соединение с сервером.
- Открытие HTTP-соединения:
HttpURLConnection используется для открытия соединения с API. Метод setRequestMethod("POST") указывает, что это POST-запрос.
Метод setRequestProperty("Content-Type", "application/json") гарантирует, что тип контента запроса — JSON.
Метод setDoOutput(true) позволяет записывать тело запроса (данные в формате JSON).
- Тело запроса:
Тело запроса строится как строка JSON: {"cat":"<category>"}, где <category> — это категория продукта (например, "phone").
Метод getOutputStream() используется для отправки строки JSON на сервер.
- Чтение ответа:
Ответ от API считывается из входного потока соединения с помощью Scanner.
Ответ добавляется в объект StringBuilder, который затем возвращается как строка.
Вот полный код:
import com.google.gson.Gson;
import com.google.gson.JsonArray;
import com.google.gson.JsonObject;
import java.io.OutputStream;
import java.net.HttpURLConnection;
import java.net.URI;
import java.net.URL;
import java.nio.charset.StandardCharsets;
import java.util.Scanner;
public class WebScraper {
public static void main(String[] args) {
try {
// API URL
String apiUrl = "https://api.demoblaze.com/bycat";
// Request parameter for product category
String category = "phone"; // Can be changed to "laptop", "monitor", etc.
// Fetch response from API
String jsonResponse = fetchApiResponse(apiUrl, category);
// Parse the JSON response
Gson gson = new Gson();
JsonObject responseObject = gson.fromJson(jsonResponse, JsonObject.class);
JsonArray items = responseObject.getAsJsonArray("Items");
// Output product information
for (int i = 0; i < items.size(); i++) {
JsonObject item = items.get(i).getAsJsonObject();
String title = item.get("title").getAsString();
String price = item.get("price").getAsString();
System.out.println("Product: " + title);
System.out.println("Price: $" + price);
System.out.println("-----------------------");
}
} catch (Exception e) {
System.err.println("An error occurred: " + e.getMessage());
}
}
}
private static String fetchApiResponse(String apiUrl, String category) throws Exception {
URI uri = new URI(apiUrl);
URL url = uri.toURL();
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("POST");
connection.setRequestProperty("Content-Type", "application/json");
connection.setDoOutput(true);
// Request body
String jsonInputString = "{\"cat\":\"" + category + "\"}";
try (OutputStream os = connection.getOutputStream()) {
byte[] input = jsonInputString.getBytes(StandardCharsets.UTF_8);
os.write(input, 0, input.length);
}
// Read the response
StringBuilder response = new StringBuilder();
try (Scanner scanner = new Scanner(connection.getInputStream(), StandardCharsets.UTF_8)) {
while (scanner.hasNextLine()) {
response.append(scanner.nextLine());
}
}
return response.toString();
}
}Вывод:
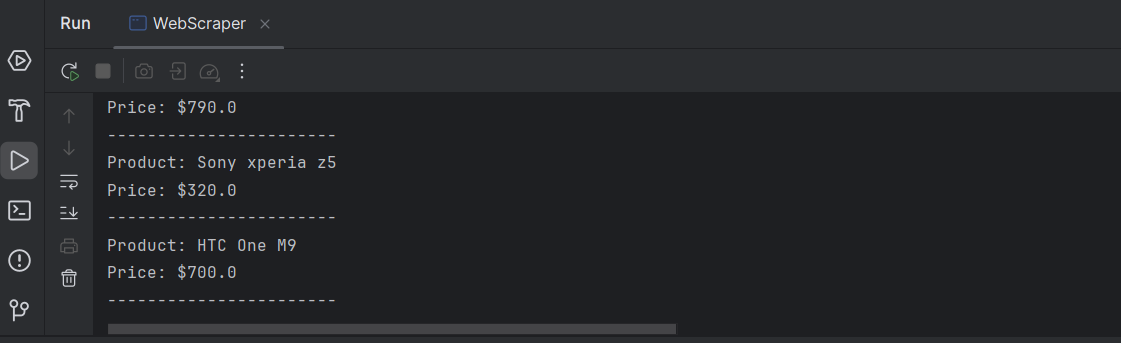
Поздравляю! Вы успешно извлекли необходимые данные о каждом продукте на странице.
Вот пример того, как скрапить данные с сайта Books to Scrape, используя Java. Мы будем использовать HttpURLConnection для отправки запросов и Jsoup для парсинга HTML.
GET-запрос: Метод Jsoup.connect(url).get() отправляет HTTP GET-запрос на указанный URL (https://books.toscrape.com/) и возвращает содержимое страницы в виде объекта Document.
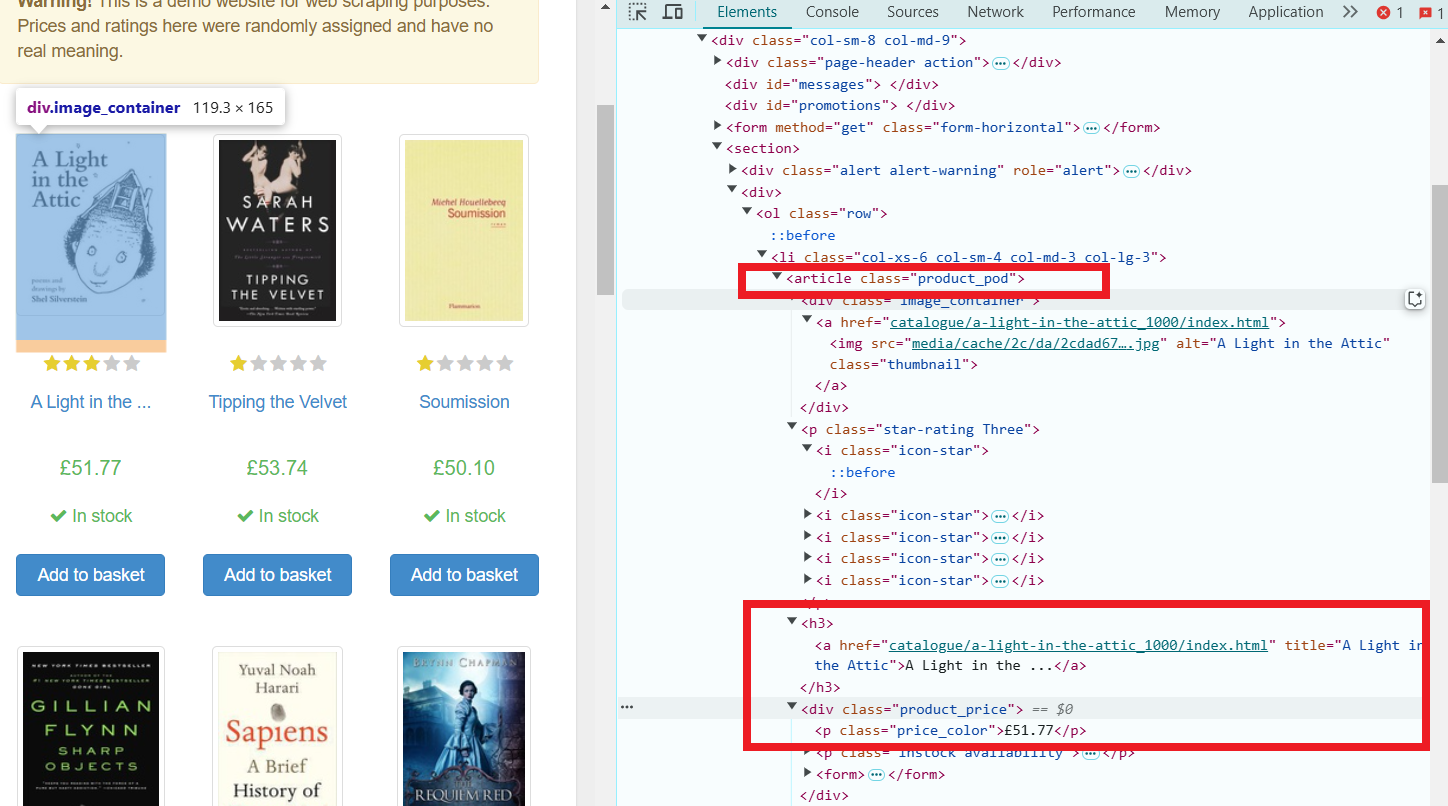
Выбор элементов:
Метод doc.select(".product_pod") выбирает все элементы с классом product_pod, которые представляют собой отдельные книги.
Метод book.select("h3 a").attr("title") извлекает название каждой книги, которое хранится в атрибуте title тега a внутри элемента h3.
Метод book.select(".price_color").text() получает текстовое содержимое (цену) из элемента с классом price_color.
Отображение данных: программа затем проходит по каждой книге, извлекая и выводя её название и цену.
Пример кода:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
public class BookScraper {
public static void main(String[] args) {
try {
// URL of the website
String url = "https://books.toscrape.com/";
// Send a GET request to fetch the page
Document doc = Jsoup.connect(url).get();
// Select all book items on the page
Elements books = doc.select(".product_pod");
// Loop through each book element and extract title and price
for (Element book : books) {
String title = book.select("h3 a").attr("title");
String price = book.select(".price_color").text();
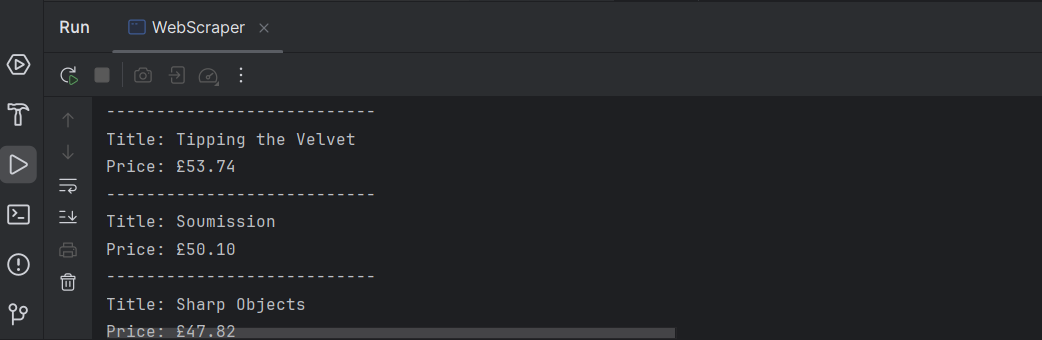
System.out.println("Title: " + title);
System.out.println("Price: " + price);
System.out.println("---------------------------");
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
Готово! Теперь у нас есть список названий и цен для всех книг, представленных на странице.
Веб-скрапинг динамичных сайтов включает в себя взаимодействие с страницами, которые загружают свой контент через JavaScript, часто с использованием AJAX (Asynchronous JavaScript and XML). В отличие от статичных сайтов, которые предоставляют весь контент в HTML при загрузке страницы, динамичные сайты получают и отображают контент динамически после загрузки страницы. Это означает, что вам нужно учитывать этот дополнительный слой сложности при скрапинге. Для динамичного веб-скрапинга в Java часто используются библиотеки, такие как Selenium или Playwright, так как они позволяют автоматизировать браузер и взаимодействовать с веб-страницами, основанными на JavaScript.
Чтобы определить, является ли сайт динамичным, вы можете использовать DevTools в вашем браузере, которые позволяют проверять сетевые запросы и ответы, видеть, как контент загружается в реальном времени, и анализировать, как данные извлекаются.
- Откройте DevTools:
Щелкните правой кнопкой мыши в любом месте на странице и выберите «Inspect», или нажмите Ctrl+Shift+I (Windows/Linux) или Cmd+Option+I (Mac).
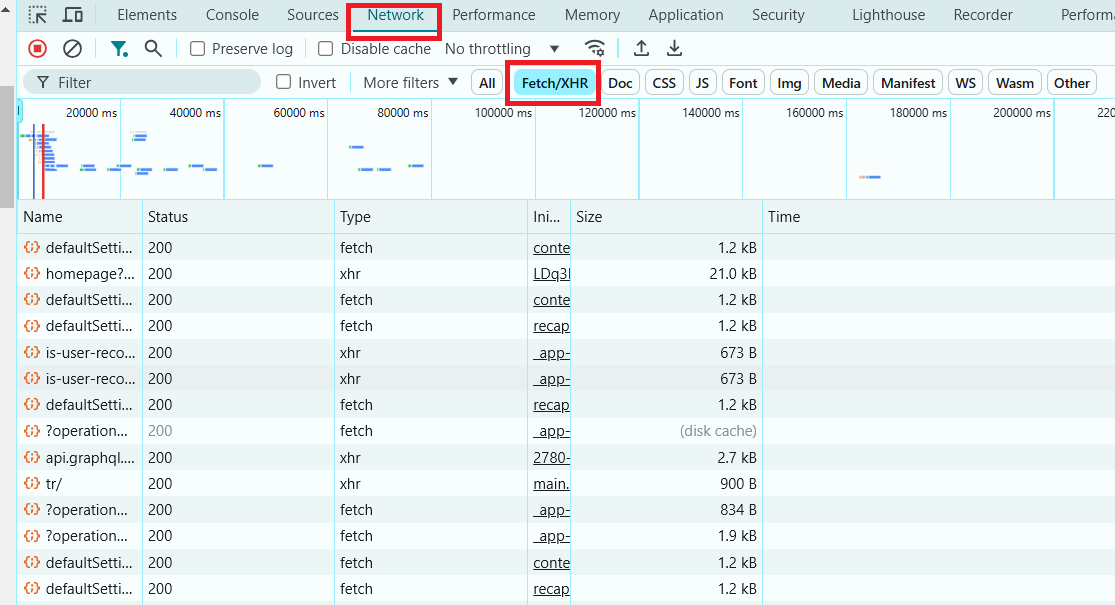
- Перейдите на вкладку Network:
Нажмите на вкладку Network в окне инструментов разработчика. Это покажет всю сетевую активность, происходящую во время загрузки страницы и после её загрузки.
- Перезагрузите страницу:
Обновите веб-страницу. Наблюдайте за вкладкой Network во время перезагрузки страницы.
- Фильтруйте XHR (AJAX) запросы:
Ищите XHR или Fetch в фильтрах на вкладке Network. Это запросы, которые загружают данные динамически. Если вы видите, что эти запросы получают JSON, HTML или другие данные, это указывает на то, что страница является динамичной.
- Проверьте загрузку контента после загрузки страницы:
После того как страница загрузится, проверьте, появляется ли дополнительный контент или изменяется ли что-то. Если вы видите новый контент, который появляется после первоначальной загрузки без обновления страницы, значит, сайт вероятно использует AJAX.
Теперь, когда вы знаете, как определить динамичные сайты, давайте посмотрим, как скрапить такой сайт.
Давайте рассмотрим пример того, как скрапить главную страницу IMDb с использованием Selenium. IMDb — отличный пример динамичного сайта, где контент загружается асинхронно после загрузки страницы.
Чтобы извлечь данные с веб-страницы с помощью Selenium (ссылка на документацию), важно правильно определить элементы, из которых вы хотите извлечь информацию. Давайте найдем необходимые элементы для извлечения данных на странице IMDb:
- Откройте браузер и перейдите по адресу: https://www.imdb.com/?ref_=nv_home.
- Откройте DevTools: щелкните правой кнопкой мыши в любом месте на странице и выберите Inspect, или нажмите Ctrl+Shift+I (Windows/Linux) или Cmd+Option+I (Mac), чтобы открыть Инструменты разработчика.
- Найдите раздел "Featured Today": щелкните правой кнопкой мыши на названии или изображении в области "Featured Today" и выберите Inspect. Это выделит HTML-код, связанный с этим разделом.
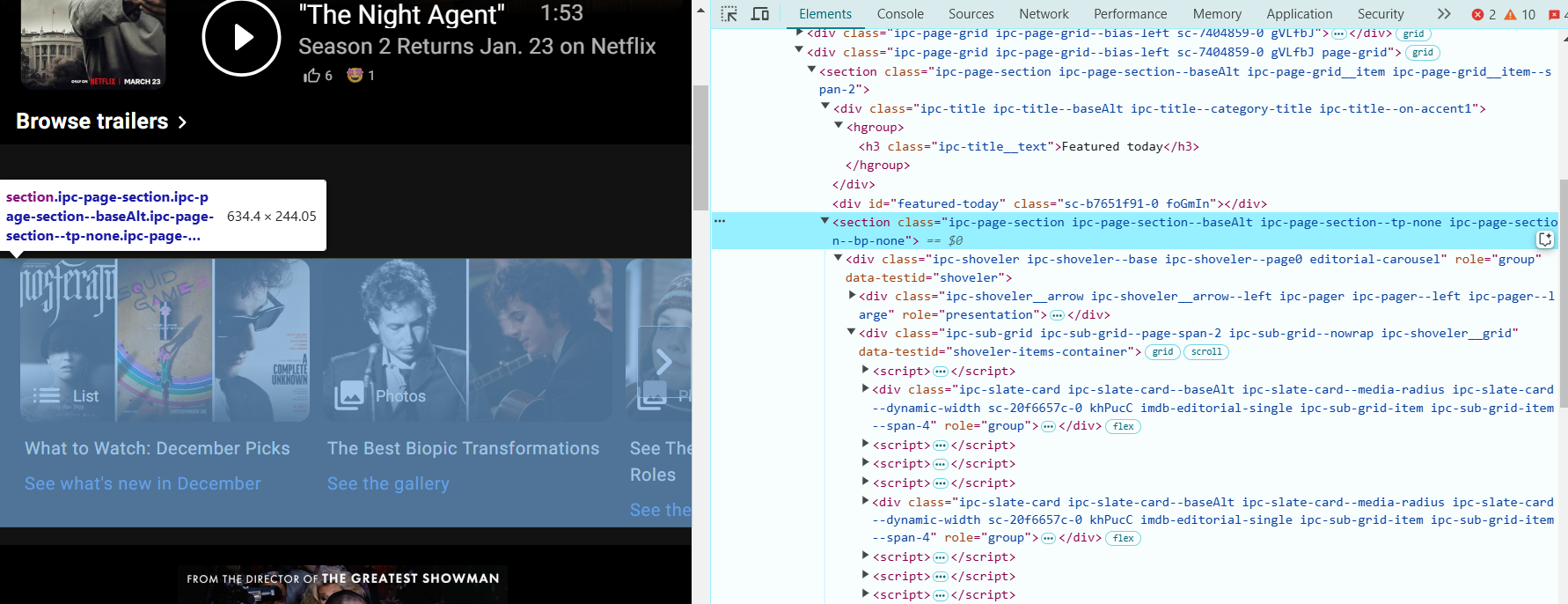
- В DevTools посмотрите на структуру HTML страницы. Раздел "Featured Today" будет иметь следующий HTML:
<section class="ipc-page-section ipc-page-section--baseAlt ipc-page-section--tp-none ipc-page-section--bp-none">
Этот раздел содержит названия фильмов или шоу, которые мы хотим скрапить.
- Названия фильмов или шоу находятся внутри элементов <div> с классом ipc-slate-card__title-text. Ищите что-то вроде этого:
<div class="ipc-slate-card__title-text">Movie Title</div>- Каждое название — это ссылка, обернутая в тег <a>. Ссылка будет выглядеть примерно так:
<a class="ipc-link" href="https://www.imdb.com/title/tt1234567/">Link</a>- Добавьте зависимости в раздел <dependencies>. Скопируйте зависимости для Selenium Java и Selenium ChromeDriver в раздел <dependencies> вашего файла pom.xml. Вот как это должно выглядеть:
<dependencies>
<!-- Selenium WebDriver -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>4.27.0</version>
</dependency>
<!-- Selenium ChromeDriver -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-chrome-driver</artifactId>
<version>4.27.0</version>
</dependency>
</dependencies>- Теперь мы можем перейти к коду:
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.util.List;
public class WebScraper {
public static void main(String[] args) {
// Create an instance of the driver
WebDriver driver = new ChromeDriver();
try {
// Open the IMDb homepage
driver.get("https://www.imdb.com/?ref_=nv_home");
System.out.println("Featured Today on IMDb:");
// Extract the container of the "Featured Today" section by class
WebElement pageSectionContainer = driver.findElement(By.cssSelector("section.ipc-page-section.ipc-page-section--baseAlt.ipc-page-section--tp-none.ipc-page-section--bp-none"));
// Find the titles in the section
List<WebElement> titles = pageSectionContainer.findElements(By.cssSelector("div.ipc-slate-card__title-text"));
// Extract actions (e.g., links)
List<WebElement> actions = pageSectionContainer.findElements(By.cssSelector("a.ipc-link"));
// Iterate over and print the titles and actions
int count = 0;
for (int i = 0; i < titles.size() && count < 10; i++) {
String title = titles.get(i).getText();
String action = actions.get(i).getAttribute("href");
System.out.printf("%d. %s - Link: %s%n", ++count, title, action);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
driver.quit();
}
}
}Пояснение скрапера:
- Мы инициализируем ChromeDriver и открываем главную страницу IMDb.
- Мы используем CSS-селектор для нахождения раздела "Featured Today". Он идентифицируется по определенному набору классов, используемых на странице.
- Как только раздел найден, мы находим отдельные названия фильмов и соответствующие ссылки, используя подходящие CSS-селекторы (ipc-slate-card__title-text для названий и ipc-link для ссылок).
- Мы проходим по списку названий и ссылок и выводим первые 10 рекомендованных элементов.
Существует несколько способов сохранить данные после веб-скрапинга, включая:
Текстовые файлы (TXT) — для простого хранения данных в текстовом формате.
CSV файлы — для хранения данных в табличном формате, легко анализируемых и обрабатываемых в Excel или других аналитических инструментах.
Базы данных — для более сложных проектов с большими объемами данных (например, MySQL, SQLite).
JSON или XML — для структурированных данных, идеально подходящих для обмена данными между приложениями.
В нашем примере текстовые файлы или CSV будут наилучшими вариантами. Это связано с тем, что данные состоят из простых текстовых строк и ссылок, которые легко организовать в таблицу для последующего анализа, особенно когда данных немного. Формат CSV особенно полезен для хранения данных в таблице с несколькими столбцами (например, название и ссылка).
Сохранение в текстовый файл:
Чтобы сохранить данные в простой текстовый файл, можно использовать классы FileWriter и BufferedWriter:
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
import java.util.List;
public class WebScraper {
public static void main(String[] args) {
// Create an instance of the driver
WebDriver driver = new ChromeDriver();
try {
// Open the IMDb homepage
driver.get("https://www.imdb.com/?ref_=nv_home");
System.out.println("Featured Today on IMDb:");
// Extract the container of the "Featured Today" section by class
WebElement pageSectionContainer = driver.findElement(By.cssSelector("section.ipc-page-section.ipc-page-section--baseAlt.ipc-page-section--tp-none.ipc-page-section--bp-none"));
// Find the titles in the section
List<WebElement> titles = pageSectionContainer.findElements(By.cssSelector("div.ipc-slate-card__title-text"));
// Extract actions (e.g., links)
List<WebElement> actions = pageSectionContainer.findElements(By.cssSelector("a.ipc-link"));
// Create a FileWriter to save data to a file
BufferedWriter writer = new BufferedWriter(new FileWriter("featured_today_imdb.txt"));
writer.write("Featured Today on IMDb:\n");
writer.write("--------------------------------\n");
// Iterate over and save the titles and actions to the text file
int count = 0;
for (int i = 0; i < titles.size() && count < 10; i++) {
String title = titles.get(i).getText();
String action = actions.get(i).getAttribute("href");
writer.write(String.format("%d. %s - Link: %s%n", ++count, title, action));
}
writer.close(); // Don't forget to close the writer!
} catch (Exception e) {
e.printStackTrace();
} finally {
driver.quit();
}
}
}Сохранение в CSV файл:
Если вы предпочитаете сохранять данные в формате CSV, вы можете использовать следующий код, который записывает данные в виде значений, разделенных запятыми:
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.io.FileWriter;
import java.io.IOException;
import java.util.List;
public class WebScraper {
public static void main(String[] args) {
// Create an instance of the driver
WebDriver driver = new ChromeDriver();
try {
// Open the IMDb homepage
driver.get("https://www.imdb.com/?ref_=nv_home");
System.out.println("Featured Today on IMDb:");
// Extract the container of the "Featured Today" section by class
WebElement pageSectionContainer = driver.findElement(By.cssSelector("section.ipc-page-section.ipc-page-section--baseAlt.ipc-page-section--tp-none.ipc-page-section--bp-none"));
// Find the titles in the section
List<WebElement> titles = pageSectionContainer.findElements(By.cssSelector("div.ipc-slate-card__title-text"));
// Extract actions (e.g., links)
List<WebElement> actions = pageSectionContainer.findElements(By.cssSelector("a.ipc-link"));
// Create a FileWriter to save data to a CSV file
FileWriter writer = new FileWriter("featured_today_imdb.csv");
writer.append("Title, Link\n");
// Iterate over and save the titles and actions to the CSV file
int count = 0;
for (int i = 0; i < titles.size() && count < 10; i++) {
String title = titles.get(i).getText();
String action = actions.get(i).getAttribute("href");
writer.append(String.format("\"%s\", \"%s\"\n", title, action));
count++;
}
writer.flush(); // Ensure everything is written to the file
writer.close(); // Close the writer
} catch (Exception e) {
e.printStackTrace();
} finally {
driver.quit();
}
}
}
Теперь вы можете сохранить извлеченные данные с IMDb в текстовый файл или CSV файл, что упростит их анализ или обмен!
При осуществлении веб-скрапинга важно обеспечить безопасность как для скрапера, так и для целевого веб-сайта. Вот несколько лучших практик безопасности:
- Избегайте перегрузки веб-сайта запросами с одного IP-адреса. Используйте прокси-серверы для ротации IP-адресов и распределения нагрузки.
- Некоторые веб-сайты используют меры защиты, такие как CAPTCHA или другие техники противодействия скрапингу. Важно эффективно их обрабатывать, возможно, с помощью инструментов, таких как CapMonster Cloud для решения CAPTCHA.
- Чтобы избежать блокировки как бота, ограничьте количество запросов, добавив задержки между ними. Это имитирует поведение обычного пользователя и предотвращает перегрузку сервера.
- Изменяйте строку User-Agent в вашем скрапере, чтобы имитировать различные браузеры. Это помогает избежать обнаружения.
- Будьте осторожны с хранением конфиденциальных пользовательских данных (например, паролей), полученных в процессе скрапинга. Соблюдайте законы о защите данных, такие как GDPR, если это применимо.
- И, наконец, всегда проверяйте Условия использования (TOS) веб-сайта и убедитесь, что скрапинг разрешен. Игнорирование этого может привести к юридическим последствиям.
Чтобы ускорить процесс веб-скрапинга и сделать его более эффективным, учитывайте следующие советы:
- Используйте безголовые браузеры, такие как Chrome или Firefox в режиме без графического интерфейса (non-GUI), чтобы ускорить скрапинг. Это избавляет от накладных расходов на рендеринг пользовательского интерфейса.
Пример: используйте ChromeOptions в Selenium для работы в безголовом режиме.
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless");
WebDriver driver = new ChromeDriver(options);
- Кэшируйте данные, когда это возможно, чтобы избежать повторных запросов на одно и то же. Если вы работаете с большими наборами данных, хранение результатов в локальной базе данных может быть более эффективным.
- Используйте более эффективные XPath и CSS-селекторы, чтобы минимизировать обход DOM. Избегайте слишком общих селекторов, которые могут привести к ненужным проверкам. Например, вместо использования findElement(By.xpath("//div[@class='example']/a"), используйте более конкретный путь, если это возможно.
- Если страница не требует JavaScript для рендеринга контента, избегайте использования таких инструментов, как Selenium, и выбирайте более быстрые библиотеки, такие как Jsoup, которые непосредственно парсят HTML.
- Параллельная обработка. Используйте несколько потоков или процессов для одновременного скрапинга нескольких страниц. Это может значительно сократить время, необходимое для скрапинга большого количества страниц.
- Инструменты: рассмотрите возможность использования библиотек, таких как ExecutorService в Java для многозадачности.
Вот пример параллельности в Java для веб-скрапинга с использованием библиотеки java.util.concurrent, которая предоставляет инструменты для многозадачного программирования.
import java.io.IOException;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class ParallelWebScraping {
// Method to scrape the content of a page
public static String scrapePage(String url) throws IOException {
System.out.println("Scraping URL: " + url + " in thread: " + Thread.currentThread().getName());
Document doc = Jsoup.connect(url).get();
return doc.title(); // Returning the page title as an example
}
public static void main(String[] args) {
// List of URLs to scrape
List<String> urls = Arrays.asList(
"https://example.com",
"https://example.org",
"https://example.net"
);
// Create a fixed thread pool
ExecutorService executorService = Executors.newFixedThreadPool(3);
try {
// Create tasks for parallel execution
List<Callable<String>> tasks = urls.stream()
.map(url -> (Callable<String>) () -> scrapePage(url))
.toList();
// Execute tasks and collect results
List<Future<String>> results = executorService.invokeAll(tasks);
// Print the results
for (Future<String> result : results) {
System.out.println("Page title: " + result.get());
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// Shutdown the thread pool
executorService.shutdown();
}
}
}- Мы определяем список URL-адресов для скрапинга.
- Создается фиксированный пул потоков, чтобы ограничить количество одновременно работающих потоков.
- Каждый Callable представляет собой задачу, которая возвращает результат после выполнения (в данном случае — заголовок страницы).
- Метод invokeAll выполняет все задачи параллельно и возвращает список объектов Future, содержащих результаты.
- Для получения и парсинга веб-страниц используется библиотека Jsoup.
- Извлекаем заголовки страниц (или другие данные) из объектов Future.
Java — отличный выбор для веб-скрапинга, предоставляющий мощные инструменты и библиотеки для извлечения данных. В этой статье мы обсудили основные подходы, включая скрапинг статических и динамических сайтов, работу с API и поделились полезными советами для более эффективного извлечения данных.
С такими инструментами, как CapMonster Cloud для обхода CAPTCHA, Java позволяет решать даже самые сложные задачи. Экспериментируйте, развивайте свои навыки и исследуйте новые способы автоматизации. Мир данных ждёт, чтобы вы его раскрыли!
- Что такое веб-скрапинг и как он работает?
Веб-скрапинг — это процесс автоматического извлечения данных с веб-страниц. Он включает в себя использование программного обеспечения для получения HTML-кода страницы, извлечения необходимой информации и дальнейшей обработки или сохранения этих данных.
- Какие лучшие инструменты для веб-скрапинга в Java?
Популярные инструменты для веб-скрапинга в Java включают:
- Jsoup — для парсинга HTML.
- Selenium — для автоматизации браузера, особенно для динамических сайтов.
- HtmlUnit — легковесный браузер для автоматизации.
- Как обойти защиту от скрапинга (например, CAPTCHA)?
Для обхода CAPTCHA можно использовать такие сервисы, как CapMonster Cloud, которые автоматически решают CAPTCHA для вашего скрипта, позволяя продолжать скрапинг без задержек.
- Можно ли использовать веб-скрапинг на всех сайтах?
Не все сайты разрешают веб-скрапинг. Перед началом работы необходимо проверить условия использования сайта, чтобы убедиться, что скрапинг разрешен. Многие сайты используют защиту, такую как CAPTCHA или блокировку IP-адресов, чтобы предотвратить скрапинг.
- Какие типы данных я могу извлечь с помощью веб-скрапинга?
Вы можете извлекать различные типы данных, такие как:
- Тексты (например, заголовки, описания).
- Цены товаров.
- Данные пользователей.
- Новости.
Структурированные данные, такие как таблицы и списки.
- Как обработать динамическое содержимое на сайтах?
Для динамического содержимого, загружаемого через JavaScript, можно использовать такие инструменты, как Selenium, которые имитируют действия пользователя в браузере и позволяют извлекать данные с динамически генерируемых страниц.
7. Как ускорить процесс скрапинга?
- Используйте многозадачность и параллельные запросы для ускорения сбора данных.
- Ограничьте частоту запросов, чтобы избежать блокировки.
- Используйте прокси-серверы для распределения нагрузки.
8. Что делать, если сайт блокирует мои запросы?
Если сайт блокирует ваши запросы, вы можете:
- Использовать прокси-серверы для смены вашего IP-адреса.
- Добавлять задержки между запросами.
- Менять свой user agent, чтобы имитировать реальные браузеры.
- Использовать фингерпринтинг (подмена данных сессии), чтобы ваши запросы выглядели как запросы реальных пользователей (например, изменяя заголовки запросов, cookies, рефереры и accept-languages).
- Использовать сервисы решения CAPTCHA.