Se você chegou nesta página, provavelmente já está familiarizado com o conceito de web scraping em Java e está buscando se aprofundar mais nos detalhes. Ótimo, você está no caminho certo! Neste guia, explicaremos os conceitos básicos de web scraping em Java de maneira simples e acessível, além de demonstrarmos como extrair dados de um site real, incluindo elementos estáticos e dinâmicos. Tudo o que você precisa para começar de forma rápida e conveniente na coleta das informações necessárias está bem aqui. Então, vamos começar!
Web scraping é como enviar um assistente digital para coletar informações para você a partir de sites. Imagine que você está navegando na internet, copiando textos ou coletando imagens – mas, em vez de fazer isso manualmente, um programa faz isso por você, muito mais rápido e de forma mais eficiente. Com web scraping, você pode extrair dados úteis, como preços, avaliações ou detalhes de contato, e salvá-los em um formato que atenda às suas necessidades, como uma planilha ou banco de dados.
É uma ferramenta poderosa usada em áreas como pesquisa de mercado, análise competitiva e agregação de dados. Seja você um iniciante ou um desenvolvedor experiente, o web scraping pode simplificar a forma como você coleta e organiza informações da web.
Java é uma excelente escolha para web scraping, e aqui está o porquê:
Confiabilidade e Desempenho: Java é conhecido por seu desempenho robusto e pela capacidade de lidar com tarefas complexas. Seja para fazer scraping de sites pequenos ou de aplicações de grande escala, o Java oferece a estabilidade necessária para resultados consistentes.
Bibliotecas Abrangentes: Com bibliotecas como o Jsoup para análise de HTML e o Selenium para interagir com páginas web dinâmicas, o Java tem todas as ferramentas que você precisa para web scraping.
Compatibilidade entre Plataformas: Escreva seu código uma vez e execute-o em qualquer lugar. A independência de plataforma do Java significa que você pode desenvolver seus scripts de scraping em um sistema operacional e implantá-los em outro com facilidade.
Threads e Escalabilidade: As capacidades de multithreading do Java permitem fazer scraping de várias páginas simultaneamente, economizando tempo e melhorando a eficiência.
Comunidade e Suporte: O uso disseminado do Java significa que há uma vasta comunidade de desenvolvedores disponível para fornecer suporte, compartilhar soluções e oferecer conselhos.
Ao escolher o Java, você está optando por uma linguagem versátil, poderosa e bem suportada – perfeita para enfrentar projetos de web scraping de qualquer escala!
Para um web scraping bem-sucedido em Java, existem várias ferramentas e bibliotecas poderosas que podem ajudá-lo a coletar dados de páginas da web de forma eficiente. Vamos dar uma olhada em algumas opções populares:
Jsoup
O Jsoup é uma das bibliotecas mais populares para análise de HTML em Java. Ele oferece uma API simples e intuitiva para extrair dados de documentos HTML. Se você precisa recuperar informações rapidamente de uma página da web e trabalhar com o DOM (Modelo de Objeto de Documento), o Jsoup é uma escolha ideal.
Vantagens:
- Fácil de usar.
- Suporta a análise de HTML e o trabalho com seletores CSS.
- Permite limpar o HTML de lixo e tags desnecessárias.
- API simples para obter elementos e seus atributos.
Apache HttpClient
O Apache HttpClient é uma biblioteca que ajuda a trabalhar com requisições HTTP, oferecendo recursos como manipulação de cookies, cabeçalhos e autenticação. Se você precisa apenas enviar requisições e recuperar dados de um site (sem lidar com JavaScript), esta é uma excelente opção.
Vantagens:
- Flexibilidade na configuração de requisições HTTP.
- Capacidade de trabalhar com vários métodos HTTP (GET, POST, PUT, etc.).
- Integra-se bem com outras bibliotecas para processamento de dados.
HtmlUnit
O HtmlUnit é um navegador "sem cabeça" (headless) que permite interagir com páginas da web sem precisar abrir um navegador real. Ele é ideal para testes e scraping de sites onde a renderização visual não é necessária.
Vantagens:
- Leve (não necessita de uma interface gráfica).
- Adequado para scraping de páginas dinâmicas (suporta JavaScript).
- Desempenho rápido.
Selenium WebDriver
O Selenium é uma ferramenta popular para automação de navegadores. Ele é perfeito para scraping de páginas dinâmicas onde os dados são carregados usando JavaScript. Com o Selenium, você pode controlar um navegador, simular ações do usuário (cliques, digitação) e extrair as informações necessárias.
Vantagens:
- Adequado para sites dinâmicos (onde os dados são carregados por meio de JavaScript).
- Suporta múltiplos navegadores (Chrome, Firefox, Safari e outros).
- Capacidade de simular o comportamento real do usuário.
Essas bibliotecas e ferramentas oferecem funcionalidades poderosas para trabalhar com páginas da web e coletar dados. Dependendo das suas tarefas, você pode escolher uma ou mais delas. Por exemplo, para uma análise simples de HTML, o Jsoup é uma excelente escolha, enquanto para páginas dinâmicas, o Selenium ou o HtmlUnit seriam mais adequados. Sua escolha depende da complexidade do seu projeto e de como os dados são carregados nos sites de destino.
Aqui está uma visão geral dos melhores editores e IDEs para web scraping em Java, junto com os prós e contras de cada um:
- IntelliJ IDEA
O IntelliJ IDEA é uma das IDEs mais populares e poderosas para desenvolvimento em Java. Ele oferece uma série de recursos que podem ser úteis para web scraping.
Prós:
- O IntelliJ entende o contexto do código, oferecendo sugestões e correções precisas.
- Suporta todos os sistemas de build populares (Maven, Gradle) e frameworks.
- Uma poderosa e fácil de usar ferramenta de depuração.
- Oferece plugins para trabalhar com bancos de dados, Docker, testes e muito mais.
- Interface intuitiva e fácil de usar.
Contras:
- Pode ser exigente com os recursos do sistema, especialmente em computadores mais antigos ou com menor poder de processamento.
- Embora exista uma versão gratuita (Community), algumas funcionalidades estão disponíveis apenas na versão paga (Ultimate).
Nuances:
- Adequado para desenvolvedores que trabalham em projetos complexos ou em equipes, pois oferece ferramentas poderosas de refatoração e colaboração.
- Eclipse
O Eclipse é uma das IDEs mais antigas e conhecidas para Java. Ele oferece recursos extensivos para o desenvolvimento em Java e outras linguagens.
Prós:
- O Eclipse é uma IDE gratuita com a possibilidade de modificá-la.
- Uma grande quantidade de plugins e extensões.
- Adequado para o desenvolvimento de aplicações grandes.
Contras:
- A interface do Eclipse não é tão amigável quanto a do IntelliJ IDEA.
- Algumas operações podem ser lentas, especialmente ao usar muitos plugins ou projetos grandes.
Nuances:
- O Eclipse é mais adequado para desenvolvedores experientes que precisam de mais personalização e extensões. Iniciantes podem achar a interface confusa.
- JDeveloper
O JDeveloper é uma IDE da Oracle, projetada para o desenvolvimento em Java EE (Enterprise Edition).
Prós:
- Totalmente integrado com os produtos da Oracle, tornando-se uma escolha ideal para o desenvolvimento em Java EE.
- Inclui ferramentas para trabalhar com bancos de dados, serviços web e muitas outras tecnologias.
Contras:
- Em comparação com o Eclipse ou IntelliJ IDEA, o JDeveloper tem uma comunidade de usuários menor.
- Pode não ser tão conveniente para desenvolvedores que trabalham fora do ecossistema Java EE.
Nuances:
- Melhor adequado para projetos de grande escala em Java EE, especialmente se você estiver trabalhando com produtos da Oracle.
- Apache NetBeans
O Apache NetBeans é uma versão aprimorada do NetBeans, apoiada pela Apache Software Foundation.
Prós:
- Ao contrário da versão anterior, esta versão é ativamente suportada e desenvolvida.
- Totalmente gratuita e open-source.
Contras:
- Não é tão popular quanto o IntelliJ IDEA ou o Eclipse: possui menos recursos e documentação em comparação com outras IDEs.
- Pode ser mais lento: às vezes pode ser mais demorado do que outras ferramentas.
Nuances:
- Uma excelente escolha para quem busca uma IDE gratuita e open-source para desenvolvimento em Java, mas não precisa de desempenho máximo ou de um grande número de plugins.
- Visual Studio Code (VS Code)
O VS Code é um editor leve com vários plugins, tornando-o adequado para uma grande variedade de linguagens de programação, incluindo Java.
Prós:
- Rápido e consome poucos recursos.
- Plugins para Java estão disponíveis para funcionalidades como autocompletar, depuração e mais.
- Interface amigável: altamente personalizável e fácil de usar.
Contras:
- Não é uma IDE completa: comparado ao IntelliJ IDEA ou Eclipse, o VS Code não oferece todos os recursos de uma IDE, como refatoração poderosa ou gerenciamento de grandes projetos.
- Pode não ter todas as funcionalidades necessárias para projetos Java de grande escala.
Nuances:
- Perfeito para projetos menores ou de médio porte e prototipagem rápida. Ideal para desenvolvedores que valorizam simplicidade e velocidade.
Agora que nos familiarizamos com as principais e mais populares ferramentas para web scraping em Java, vamos escolher a que melhor atende às nossas necessidades e seguir com a preparação para o web scraping. Para o nosso exemplo, escolheremos o IntelliJ IDEA e o Jsoup.
1. Instalar o IntelliJ IDEA
- Visite o site oficial do IntelliJ IDEA.
- Baixe e instale a versão Community Edition (gratuita) ou a Ultimate Edition (paga).
2. Criar um Novo Projeto
- Abra o IntelliJ IDEA e selecione "New Project".
- Escolha Java como o tipo de projeto.
- Certifique-se de que o Project SDK está configurado para uma versão adequada do Java (Java 8 ou superior).
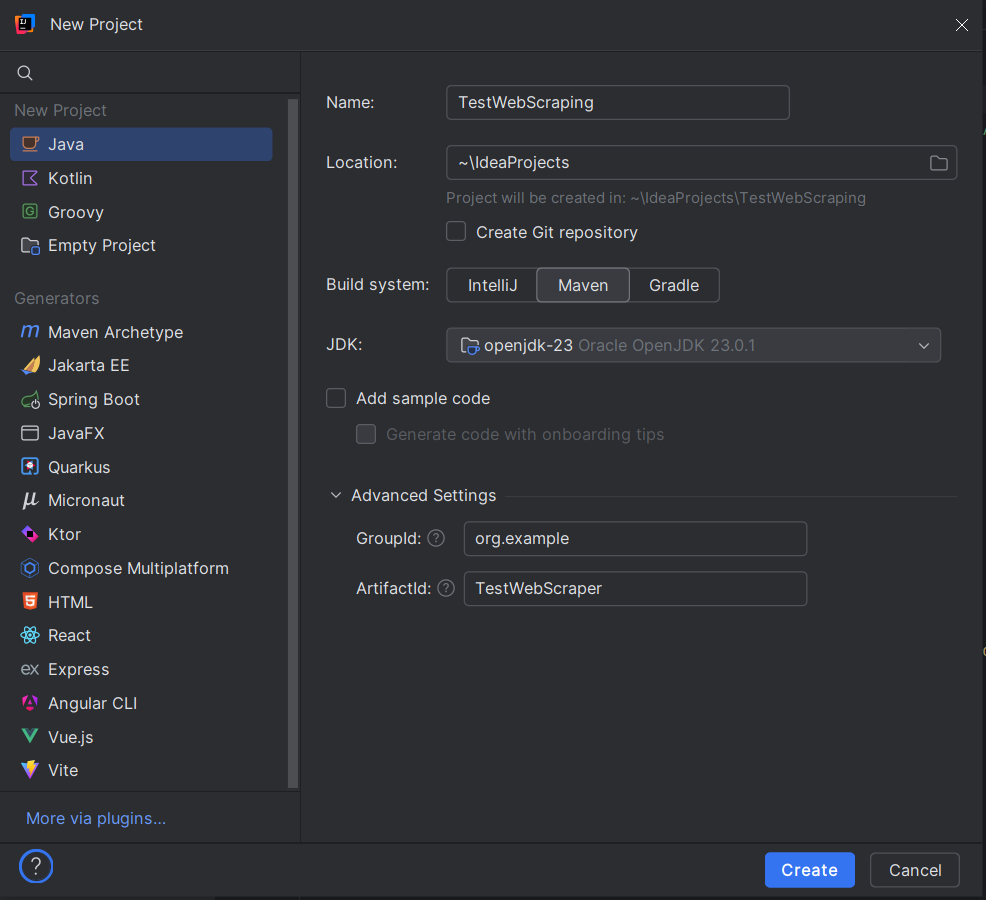
3. Configurar Nome e Localização do Projeto
- Digite um nome para o seu projeto (por exemplo, TestWebScraping).
- Escolha o local para os arquivos do seu projeto.
- Ao criar um projeto no IntelliJ IDEA, escolha Maven. No diálogo que aparecerá:
- GroupId: defina um identificador único para o seu projeto, como org.example.
- ArtifactId: este é o nome do seu projeto, por exemplo, TestWebScraper.
- Clique em Create.
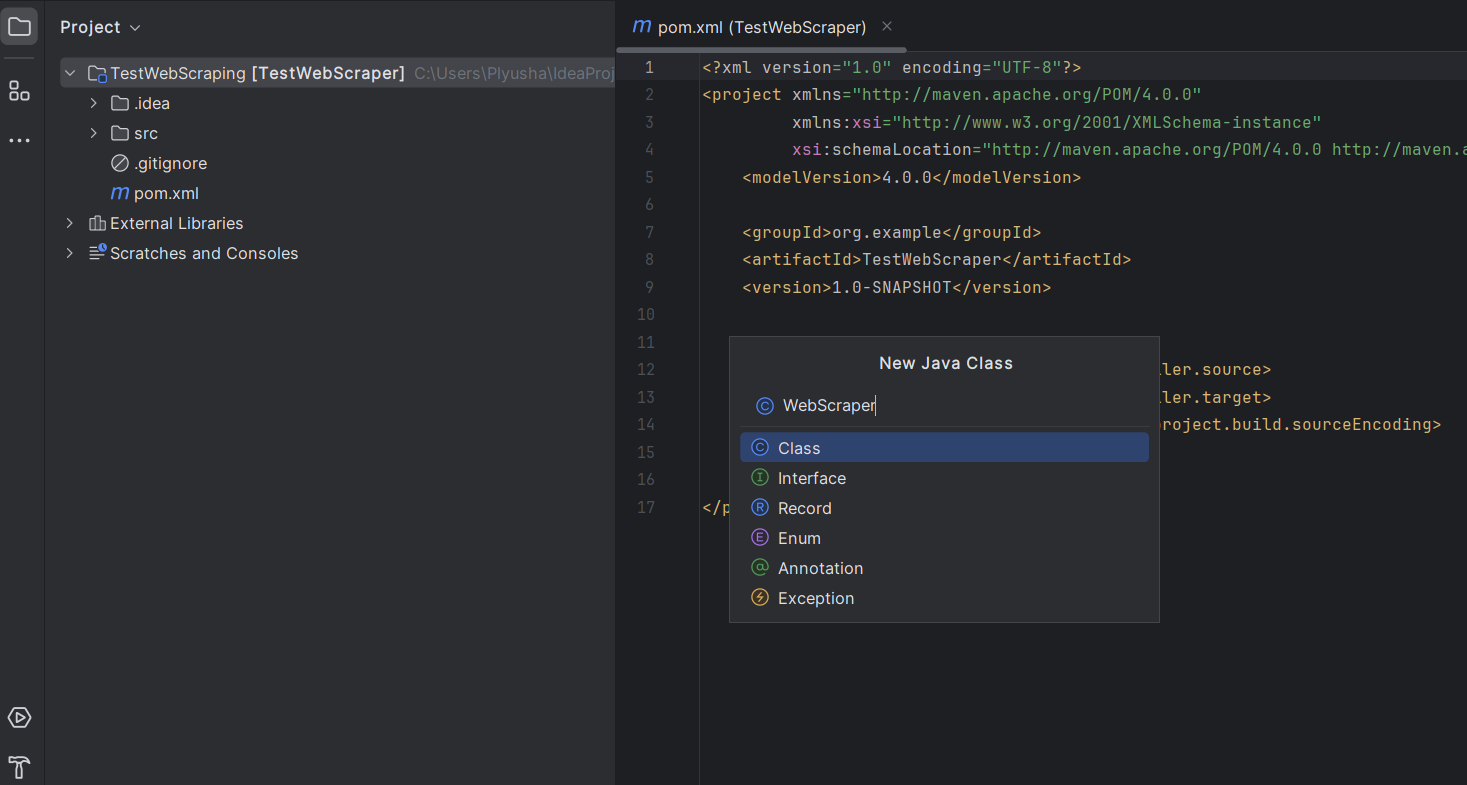
4. Configurar a Estrutura do Projeto
Após a criação do projeto, o IntelliJ IDEA abrirá automaticamente a estrutura do projeto.
- Crie uma classe Java dentro desse pacote: clique com o botão direito no seu novo pacote e selecione New -> Java Class.
- Dê o nome de WebScraper ou qualquer outro nome que preferir.
5. Adicionar Dependências
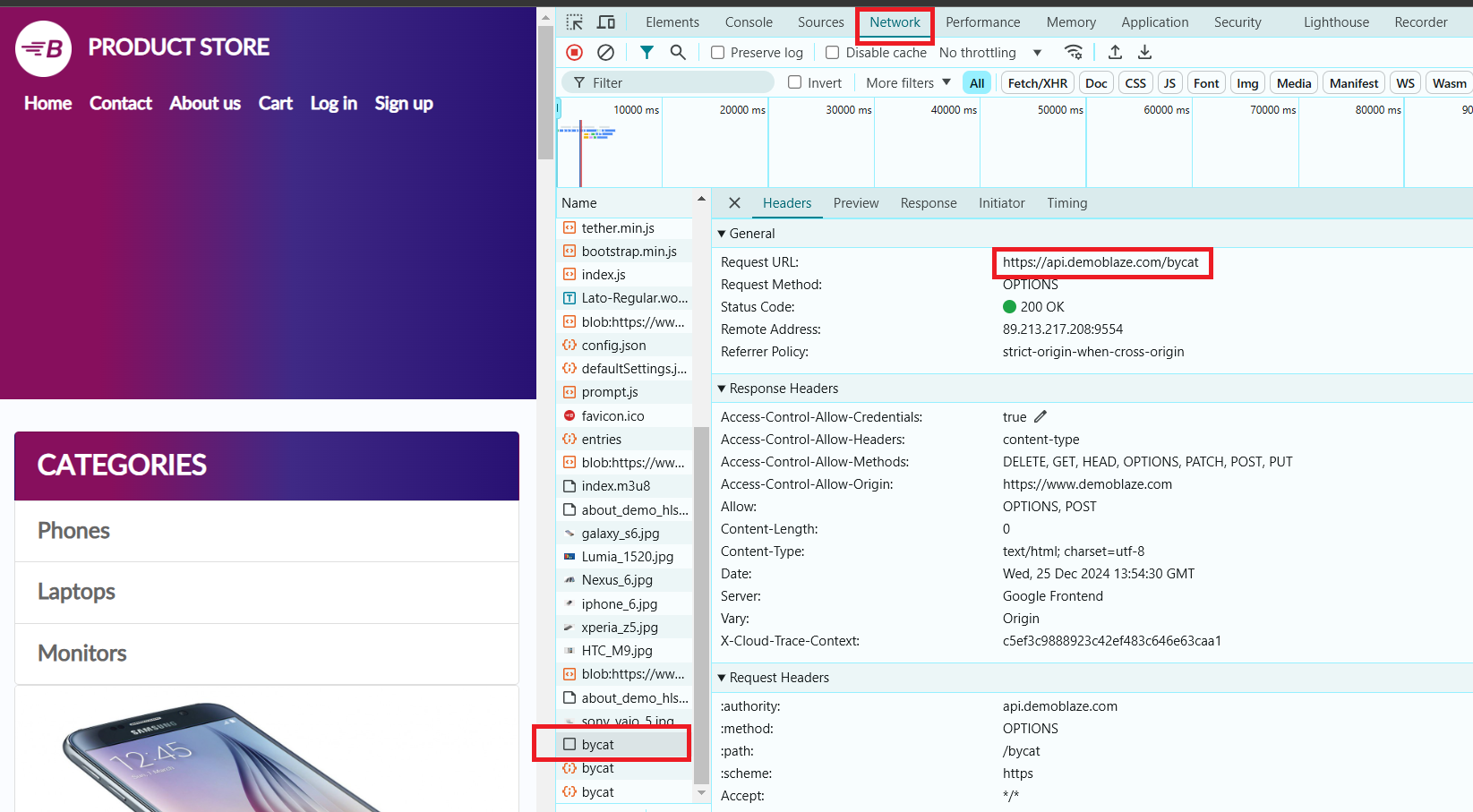
No nosso exemplo, usaremos o site https://www.demoblaze.com/#. Como o site renderiza conteúdo usando JavaScript, o Jsoup não será capaz de recuperar os dados diretamente. No entanto, o site utiliza uma API que pode ser chamada diretamente para obter informações sobre os produtos.
Ao analisar o site Demoblaze, descobrimos que os dados dos produtos são carregados por meio de requisições dinâmicas, e não no HTML estático. A API https://api.demoblaze.com/bycat é uma API interna usada para recuperar dados dos produtos no site.
Agora, vamos adicionar as dependências necessárias para interagir com a API no seu projeto.
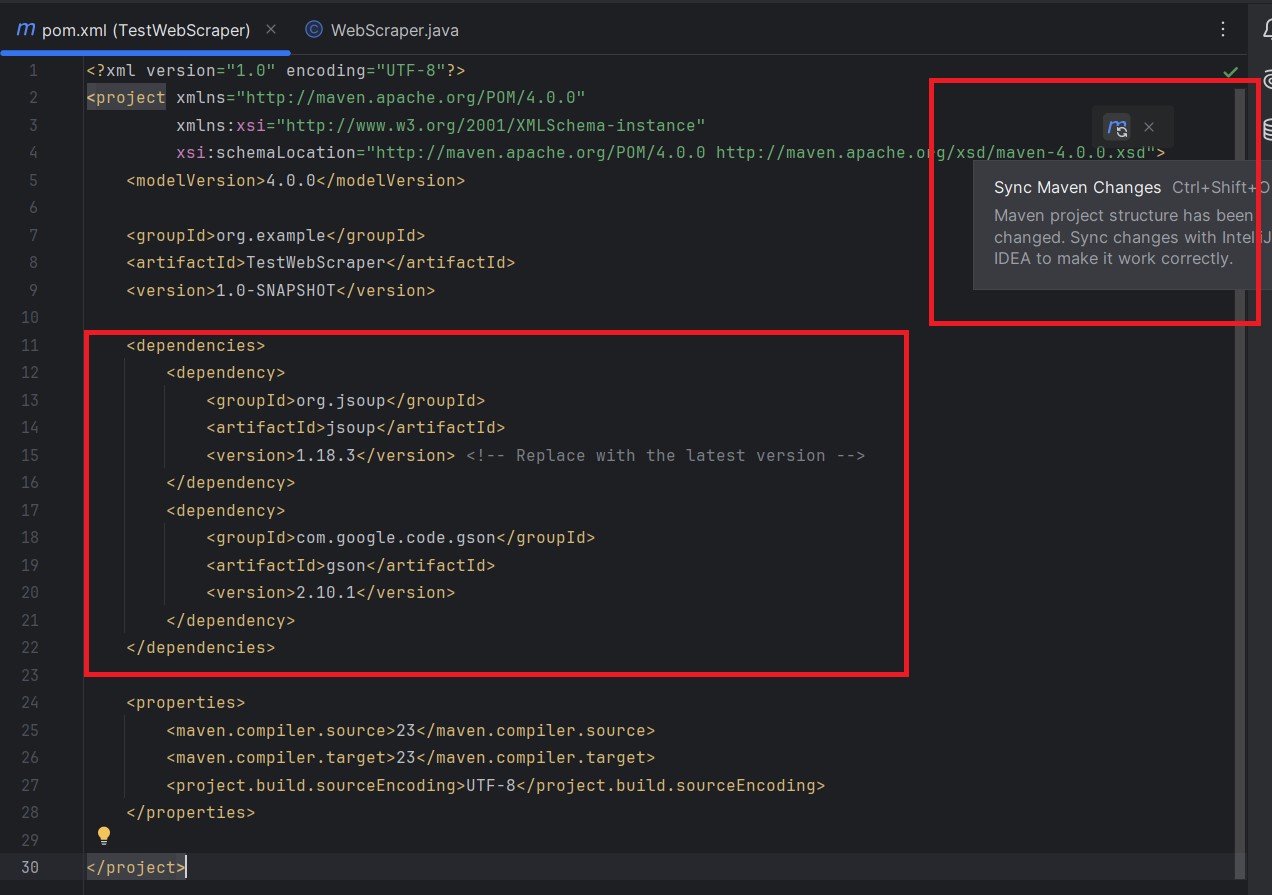
Então, você precisará adicionar as bibliotecas Jsoup e Gson ao seu projeto.
No arquivo pom.xml, adicione as seguintes dependências do Jsoup e Gson dentro da seção :
<dependencies>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.18.3</version> <!-- Substitua pela versão mais recente -->
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.10.1</version>
</dependency>
</dependencies>Não se esqueça de sincronizar as alterações do Maven:
Vamos tentar extrair o nome e o preço de cada produto da página selecionada. Mas antes, vamos inspecionar os elementos da página.
- Abra as Ferramentas de Desenvolvedor (pressionando a tecla F12 na maioria dos navegadores).
- Selecione a categoria "Phones". Na aba "Network", aparecerá uma requisição de API, que usaremos para extrair os dados necessários.
Essa API aceita uma requisição POST com um corpo JSON especificando a categoria do produto, por exemplo, e responde com um objeto JSON contendo um array de itens na chave "Items". Cada item tem propriedades como "title" e "price".
Agora, vamos começar a escrever o código para o nosso web scraper!
- Antes de começar, familiarize-se com a documentação do Jsoup e Gson.
- Abra a classe WebScraper.java criada anteriormente e importe todas as dependências necessárias:
import com.google.gson.Gson;
import com.google.gson.JsonArray;
import com.google.gson.JsonObject;
import java.io.OutputStream;
import java.net.HttpURLConnection;
import java.net.URI;
import java.net.URL;
import java.nio.charset.StandardCharsets;
import java.util.Scanner;- Método Principal:
public class WebScraper {
public static void main(String[] args) {
try {
// API URL
String apiUrl = "https://api.demoblaze.com/bycat";
// Parâmetro de solicitação para categoria de produto
String category = "phone"; // Pode ser alterado para "laptop", "monitor", etc.
// Buscar resposta da API
String jsonResponse = fetchApiResponse(apiUrl, category);
// Analisar a resposta JSON.
Gson gson = new Gson();
JsonObject responseObject = gson.fromJson(jsonResponse, JsonObject.class);
JsonArray items = responseObject.getAsJsonArray("Items");
// Exibir informações do produto
for (int i = 0; i < items.size(); i++) {
JsonObject item = items.get(i).getAsJsonObject();
String title = item.get("title").getAsString();
String price = item.get("price").getAsString();
System.out.println("Product: " + title);
System.out.println("Price: $" + price);
System.out.println("-----------------------");
}
} catch (Exception e) {
System.err.println("An error occurred: " + e.getMessage());
}
}
}URL da API: a variável apiUrl contém o endpoint da API, que retorna os detalhes dos produtos com base na categoria especificada.
Categoria: a variável category é usada para especificar a categoria do produto para filtrar a consulta da API (o padrão é "phones", mas pode ser alterado para "laptops", "monitors, etc.).
Buscar Resposta da API: o método fetchApiResponse() é chamado para enviar uma requisição POST à API e recuperar a resposta como uma string JSON.
Analisar Resposta JSON:
- O Gson é utilizado para analisar a resposta JSON em um JsonObject.
- Espera-se que a resposta JSON tenha um array de itens sob a chave "Items".
Percorrer Itens: o laço for percorre o array JSON de produtos (itens), extrai o título e o preço de cada item e os imprime no console.
- Método: fetchApiResponse
private static String fetchApiResponse(String apiUrl, String category) throws Exception {
URI uri = new URI(apiUrl);
URL url = uri.toURL();
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("POST");
connection.setRequestProperty("Content-Type", "application/json");
connection.setDoOutput(true);
// Corpo da solicitação
String jsonInputString = "{\"cat\":\"" + category + "\"}";
try (OutputStream os = connection.getOutputStream()) {
byte[] input = jsonInputString.getBytes(StandardCharsets.UTF_8);
os.write(input, 0, input.length);
}
// Ler a resposta
StringBuilder response = new StringBuilder();
try (Scanner scanner = new Scanner(connection.getInputStream(), StandardCharsets.UTF_8)) {
while (scanner.hasNextLine()) {
response.append(scanner.nextLine());
}
}
return response.toString();
}Explicação de Cada Parte:
- Criação de URI e URL:
Os objetos URI e URL são criados a partir da URL da API fornecida (apiUrl). Isso permite que o programa estabeleça uma conexão com o servidor.
- Abrindo Conexão HTTP:
HttpURLConnection é usado para abrir uma conexão com a API. O método setRequestMethod("POST") especifica que esta é uma requisição POST.
O setRequestProperty("Content-Type", "application/json") garante que o tipo de conteúdo da requisição seja JSON.
setDoOutput(true) permite escrever o corpo da requisição (os dados em JSON).
- Corpo da Requisição:
O corpo da requisição é construído como uma string JSON: {"cat":""}, onde é a categoria do produto (por exemplo, "phone").
getOutputStream() é usado para enviar a string JSON ao servidor.
- Lendo a Resposta:
A resposta da API é lida do fluxo de entrada da conexão usando um Scanner.
A resposta é adicionada a um objeto StringBuilder, que é retornado como uma string.
Aqui está o código completo:
import com.google.gson.Gson;
import com.google.gson.JsonArray;
import com.google.gson.JsonObject;
import java.io.OutputStream;
import java.net.HttpURLConnection;
import java.net.URI;
import java.net.URL;
import java.nio.charset.StandardCharsets;
import java.util.Scanner;
public class WebScraper {
public static void main(String[] args) {
try {
// API URL
String apiUrl = "https://api.demoblaze.com/bycat";
// Parâmetro de solicitação para categoria de produto
String category = "phone"; // Can be changed to "laptop", "monitor", etc.
// Buscar resposta da API.
String jsonResponse = fetchApiResponse(apiUrl, category);
// Analisar a resposta JSON
Gson gson = new Gson();
JsonObject responseObject = gson.fromJson(jsonResponse, JsonObject.class);
JsonArray items = responseObject.getAsJsonArray("Items");
// Exibir informações do produto
for (int i = 0; i < items.size(); i++) {
JsonObject item = items.get(i).getAsJsonObject();
String title = item.get("title").getAsString();
String price = item.get("price").getAsString();
System.out.println("Product: " + title);
System.out.println("Price: $" + price);
System.out.println("-----------------------");
}
} catch (Exception e) {
System.err.println("An error occurred: " + e.getMessage());
}
}
}
private static String fetchApiResponse(String apiUrl, String category) throws Exception {
URI uri = new URI(apiUrl);
URL url = uri.toURL();
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("POST");
connection.setRequestProperty("Content-Type", "application/json");
connection.setDoOutput(true);
// Corpo da solicitação
String jsonInputString = "{\"cat\":\"" + category + "\"}";
try (OutputStream os = connection.getOutputStream()) {
byte[] input = jsonInputString.getBytes(StandardCharsets.UTF_8);
os.write(input, 0, input.length);
}
// Ler a resposta
StringBuilder response = new StringBuilder();
try (Scanner scanner = new Scanner(connection.getInputStream(), StandardCharsets.UTF_8)) {
while (scanner.hasNextLine()) {
response.append(scanner.nextLine());
}
}
return response.toString();
}
}Saída:
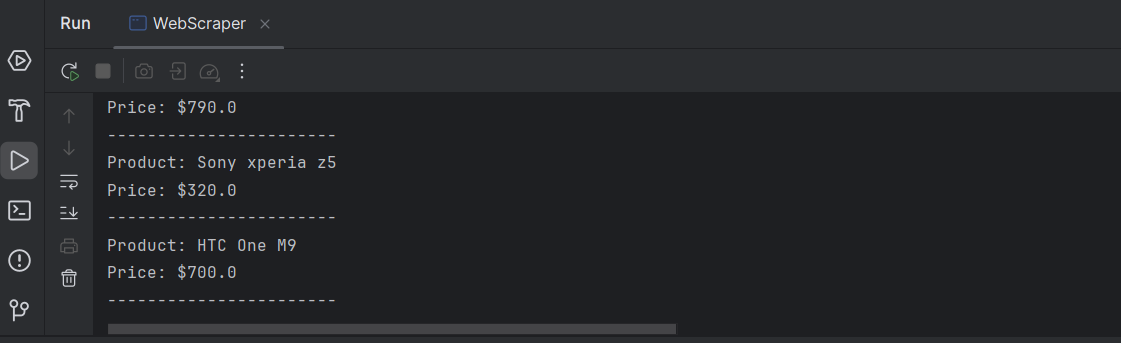
Parabéns! Você extraiu com sucesso as informações necessárias de cada produto na página.
Aqui está um exemplo de como extrair dados do site Books to Scrape usando Java. Usaremos HttpURLConnection para fazer requisições e Jsoup para analisar o HTML.
Requisição GET: O método Jsoup.connect(url).get() envia uma requisição HTTP GET para a URL especificada (https://books.toscrape.com/) e retorna o conteúdo da página como um Document.
Selecionando Elementos:
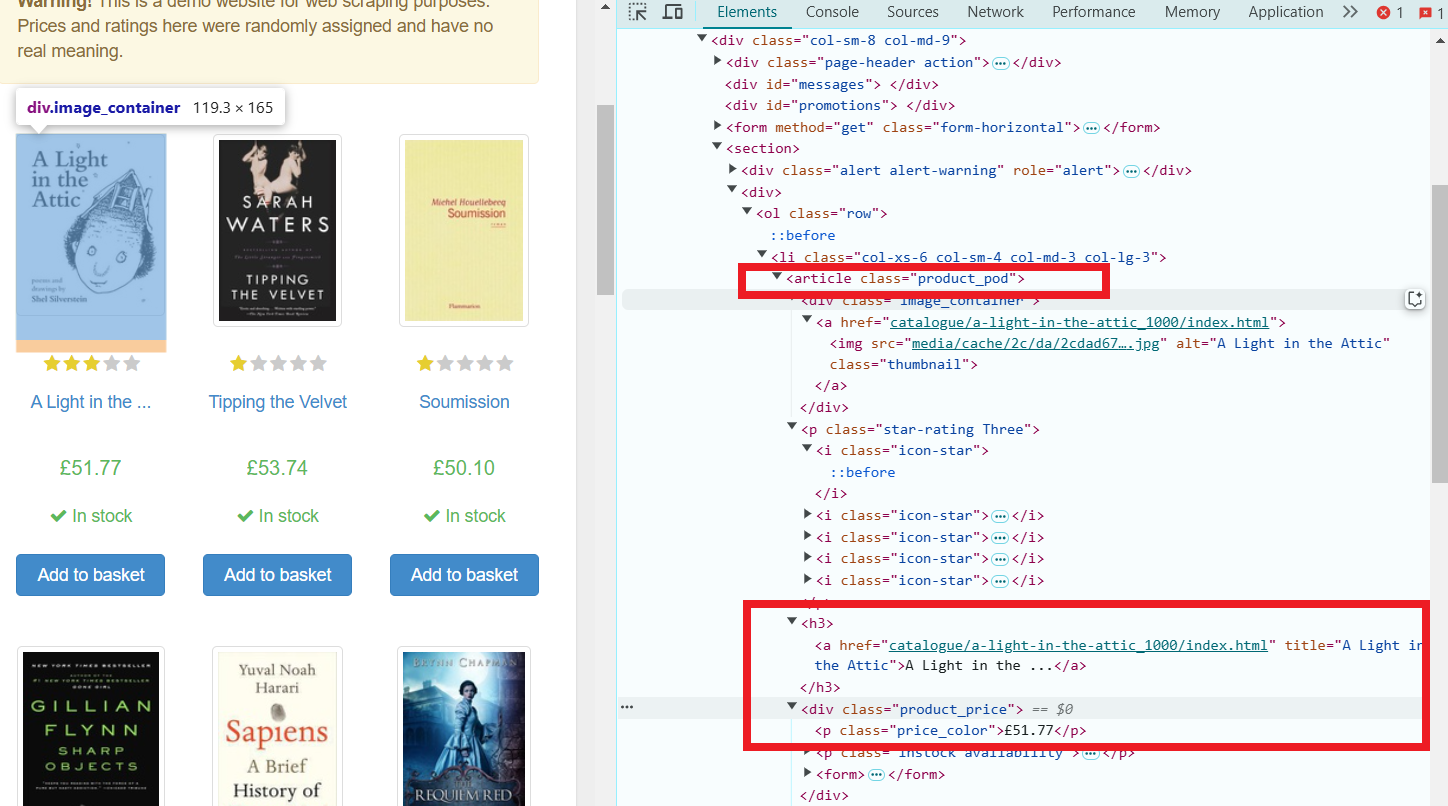
doc.select(".product_pod") seleciona todos os elementos com a classe product_pod, que são os livros individuais.
book.select("h3 a").attr("title") extrai o título de cada livro, que está armazenado no atributo title da tag a dentro do elemento h3.
book.select(".price_color").text() obtém o conteúdo de texto (preço) do elemento com a classe price_color.
Exibindo os Dados: o programa então percorre cada livro, extraindo e imprimindo seu título e preço.
Exemplo de Código:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
public class BookScraper {
public static void main(String[] args) {
try {
// URL do site
String url = "https://books.toscrape.com/";
// Envie uma solicitação GET para buscar a página
Document doc = Jsoup.connect(url).get();
// Selecione todos os itens de livro na página
Elements books = doc.select(".product_pod");
// Percorra cada elemento de livro e extraia o título e o preço
for (Element book : books) {
String title = book.select("h3 a").attr("title");
String price = book.select(".price_color").text();
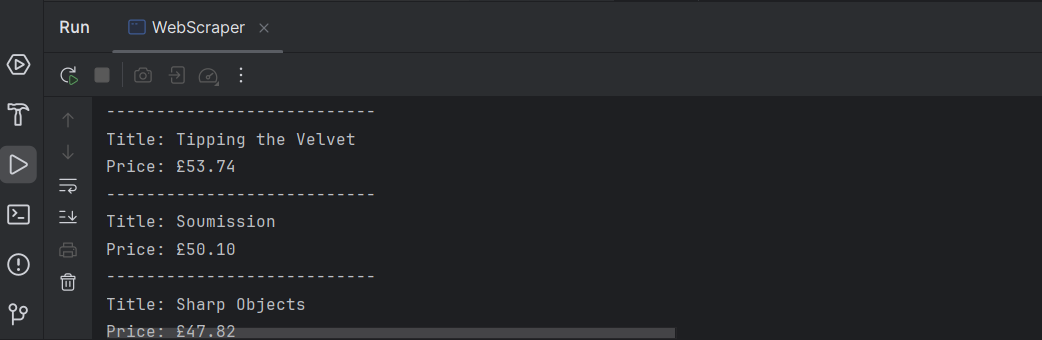
System.out.println("Title: " + title);
System.out.println("Price: " + price);
System.out.println("---------------------------");
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
Pronto! Agora temos uma lista de títulos e preços de todos os livros exibidos na página.
O web scraping de sites dinâmicos envolve a interação com páginas que carregam seu conteúdo via JavaScript, muitas vezes usando AJAX (JavaScript Assíncrono e XML). Diferentemente dos sites estáticos, que fornecem todo o seu conteúdo no HTML quando a página é carregada, os sites dinâmicos buscam e exibem o conteúdo dinamicamente após o carregamento da página. Isso significa que você precisa lidar com essa camada extra de complexidade ao fazer o scraping. Para scraping dinâmico na web em Java, bibliotecas como Selenium ou Playwright são frequentemente usadas, pois permitem automatizar o navegador e interagir com páginas controladas por JavaScript.
Para identificar um site dinâmico, você pode usar as DevTools no seu navegador, que permitem inspecionar requisições e respostas de rede, ver o carregamento de conteúdo dinâmico em tempo real e analisar como os dados são buscados.
- Abrir as DevTools:
Clique com o botão direito em qualquer lugar da página e selecione Inspecionar, ou pressione Ctrl+Shift+I (Windows/Linux) ou Cmd+Option+I (Mac).
- Ir para a Aba Network:
Clique na aba Network na janela das Ferramentas de Desenvolvedor. Isso mostrará toda a atividade de rede enquanto a página carrega e depois de carregada.
- Recarregar a Página:
Atualize a página. Observe a aba Network enquanto a página é recarregada.
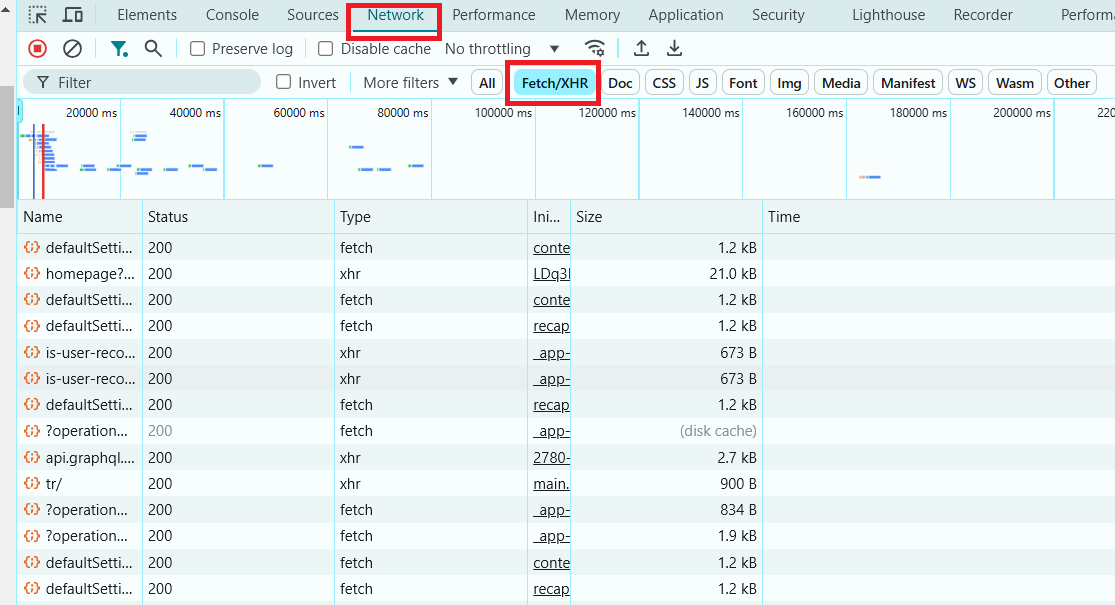
- Filtrar Requisições XHR (AJAX):
Procure por XHR ou Fetch nos filtros dentro da aba Network. Estas são as requisições que buscam dados dinamicamente. Se você ver essas requisições buscando JSON, HTML ou outros dados, isso indica que a página é dinâmica.
- Verificar Conteúdo Carregado Após o Carregamento da Página:
Depois que a página estiver carregada, verifique se conteúdo adicional aparece ou muda. Se você ver mais conteúdo aparecendo após o carregamento inicial sem uma atualização da página, é provável que o site esteja usando AJAX.
Agora que você sabe como identificar sites dinâmicos, vamos ver como fazer o scraping de um deles.
Vamos passar por um exemplo de como fazer o scraping da página inicial do IMDb usando Selenium. O IMDb é um ótimo exemplo de site dinâmico, onde o conteúdo é carregado de forma assíncrona após o carregamento da página.
Para fazer o scraping de dados de uma página web usando o Selenium (link da documentação), é essencial identificar corretamente os elementos dos quais você deseja extrair informações. Vamos localizar os elementos necessários para a extração de dados, usando a página do IMDb:
- Abra seu navegador e acesse: https://www.imdb.com/?ref_=nv_home.
- Abrir o DevTools: clique com o botão direito em qualquer lugar da página e selecione Inspecionar, ou pressione Ctrl+Shift+I (Windows/Linux) ou Cmd+Option+I (Mac) para abrir as Ferramentas de Desenvolvedor.
- Localize a seção "Featured Today": clique com o botão direito sobre um título ou imagem na área "Featured Today" e selecione Inspecionar. Isso irá destacar o código HTML relacionado a essa seção.
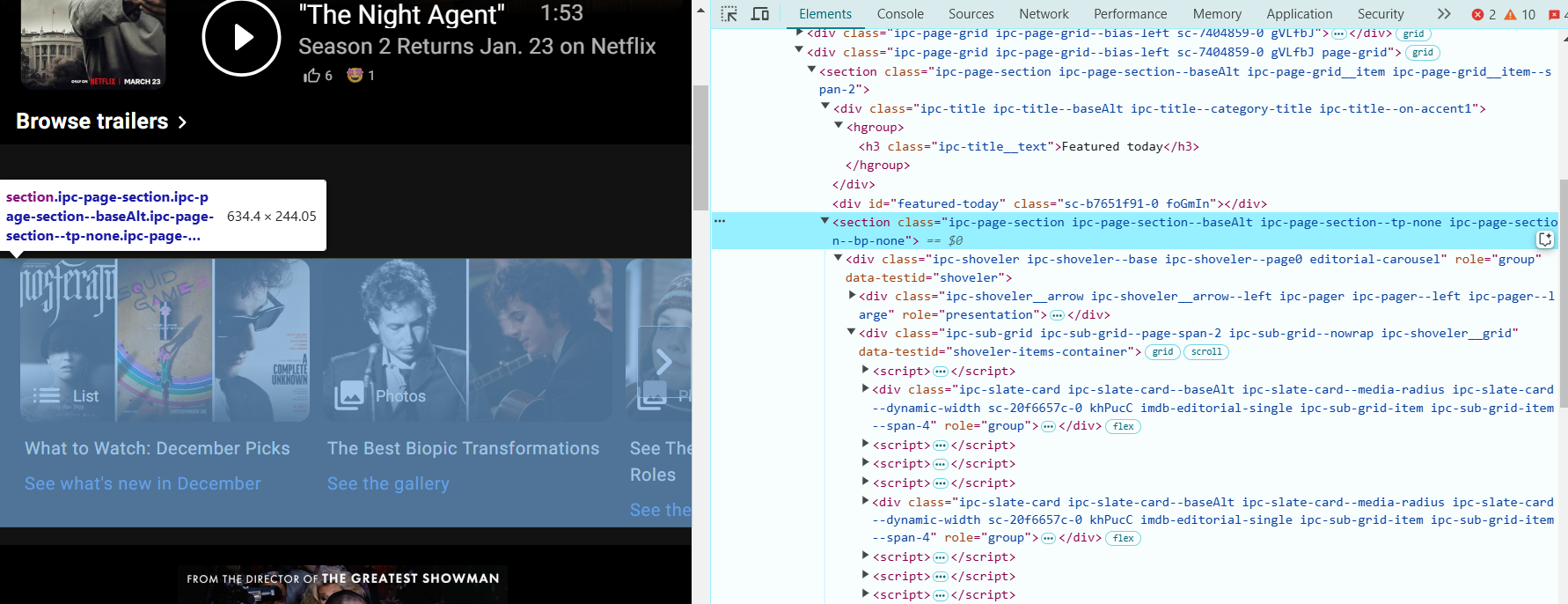
- Nas DevTools, observe a estrutura HTML da página. A seção "Featured Today" terá o seguinte HTML:
<section class="ipc-page-section ipc-page-section--baseAlt ipc-page-section--tp-none ipc-page-section--bp-none">
Esta seção contém os títulos de filmes ou programas que queremos extrair.
- Os títulos de filmes ou programas estão dentro de elementos <div> com a classe ipc-slate-card__title-text. Procure algo assim:
<div class="ipc-slate-card__title-text">Movie Title</div>- Cada título é um link envolto em uma tag <a>. O link será algo assim:
<a class="ipc-link" href="https://www.imdb.com/title/tt1234567/">Link</a>- Adicione as dependências à seção <dependencies>. Copie as dependências para Selenium Java e Selenium ChromeDriver para a seção <dependencies> do seu arquivo pom.xml. Aqui está como deve ficar:
<dependencies>
<!-- Selenium WebDriver -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>4.27.0</version>
</dependency>
<!-- Selenium ChromeDriver -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-chrome-driver</artifactId>
<version>4.27.0</version>
</dependency>
</dependencies>- Agora podemos continuar com o código:
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.util.List;
public class WebScraper {
public static void main(String[] args) {
// Crie uma instância do driver.
WebDriver driver = new ChromeDriver();
try {
// Abra a página inicial do IMDb.
driver.get("https://www.imdb.com/?ref_=nv_home");
System.out.println("Featured Today on IMDb:");
// Extraia o container da seção "Featured Today" pela classe
WebElement pageSectionContainer = driver.findElement(By.cssSelector("section.ipc-page-section.ipc-page-section--baseAlt.ipc-page-section--tp-none.ipc-page-section--bp-none"));
// Encontre os títulos na seção
List<WebElement> titles = pageSectionContainer.findElements(By.cssSelector("div.ipc-slate-card__title-text"));
// Extraia as ações (por exemplo, links)
List<WebElement> actions = pageSectionContainer.findElements(By.cssSelector("a.ipc-link"));
// Itere sobre e imprima os títulos e ações
int count = 0;
for (int i = 0; i < titles.size() && count < 10; i++) {
String title = titles.get(i).getText();
String action = actions.get(i).getAttribute("href");
System.out.printf("%d. %s - Link: %s%n", ++count, title, action);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
driver.quit();
}
}
}
Explicação do Scraper:
- Inicializamos o ChromeDriver e abrimos a página inicial do IMDb.
- Usamos um seletor CSS para encontrar a seção "Featured Today". Isso é identificado por um conjunto específico de classes usadas na página.
- Uma vez localizada a seção, encontramos os títulos individuais dos filmes e os links correspondentes, usando os seletores CSS apropriados (ipc-slate-card__title-text para os títulos e ipc-link para os links).
- Fazemos um loop pela lista de títulos e links e imprimimos os primeiros 10 itens em destaque.
Existem várias maneiras de salvar dados do web scraping, incluindo:
- Arquivos de Texto (TXT) — para armazenamento simples de dados em formato de texto simples.
- Arquivos CSV — para armazenar dados em formato de tabela, fácil de analisar e processar no Excel ou em outras ferramentas de análise.
- Bancos de Dados — para projetos mais complexos com grandes volumes de dados (por exemplo, MySQL, SQLite).
- JSON ou XML — para dados estruturados, ideal para trocar dados entre aplicações.
No nosso exemplo, arquivos de texto ou CSV seriam as melhores opções. Isso ocorre porque os dados consistem em simples strings de texto e links, que são fáceis de organizar em uma tabela para análise posterior, especialmente quando não há muitos dados. O formato CSV é particularmente útil para armazenar dados em uma tabela com várias colunas (por exemplo, título e link).
Salvando em um Arquivo de Texto:
Para salvar os dados em um arquivo de texto simples, você pode usar as classes FileWriter e BufferedWriter:
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
import java.util.List;
public class WebScraper {
public static void main(String[] args) {
// Crie uma instância do driver.
WebDriver driver = new ChromeDriver();
try {
// Abra a página inicial do IMDb
driver.get("https://www.imdb.com/?ref_=nv_home");
System.out.println("Featured Today on IMDb:");
// Extraia o container da seção "Featured Today" pela classe
WebElement pageSectionContainer = driver.findElement(By.cssSelector("section.ipc-page-section.ipc-page-section--baseAlt.ipc-page-section--tp-none.ipc-page-section--bp-none"));
// Encontre os títulos na seção
List<WebElement> titles = pageSectionContainer.findElements(By.cssSelector("div.ipc-slate-card__title-text"));
// Extraia as ações (por exemplo, links)
List<WebElement> actions = pageSectionContainer.findElements(By.cssSelector("a.ipc-link"));
// Crie um FileWriter para salvar os dados em um arquivo
BufferedWriter writer = new BufferedWriter(new FileWriter("featured_today_imdb.txt"));
writer.write("Featured Today on IMDb:\n");
writer.write("--------------------------------\n");
// Itere sobre e salve os títulos e ações no arquivo de texto.
int count = 0;
for (int i = 0; i < titles.size() && count < 10; i++) {
String title = titles.get(i).getText();
String action = actions.get(i).getAttribute("href");
writer.write(String.format("%d. %s - Link: %s%n", ++count, title, action));
}
writer.close(); // Don't forget to close the writer!
} catch (Exception e) {
e.printStackTrace();
} finally {
driver.quit();
}
}
}Salvando em um Arquivo CSV:
Se preferir salvar os dados no formato CSV, você pode usar o seguinte código, que grava os dados como valores separados por vírgula:
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.io.FileWriter;
import java.io.IOException;
import java.util.List;
public class WebScraper {
public static void main(String[] args) {
// Crie uma instância do driver
WebDriver driver = new ChromeDriver();
try {
// Abra a página inicial do IMDb
driver.get("https://www.imdb.com/?ref_=nv_home");
System.out.println("Featured Today on IMDb:");
// Extraia o container da seção "Featured Today" pela classe
WebElement pageSectionContainer = driver.findElement(By.cssSelector("section.ipc-page-section.ipc-page-section--baseAlt.ipc-page-section--tp-none.ipc-page-section--bp-none"));
// Encontre os títulos na seção
List<WebElement> titles = pageSectionContainer.findElements(By.cssSelector("div.ipc-slate-card__title-text"));
// Extraia as ações (por exemplo, links)
List<WebElement> actions = pageSectionContainer.findElements(By.cssSelector("a.ipc-link"));
// Crie um FileWriter para salvar os dados em um arquivo CSV
FileWriter writer = new FileWriter("featured_today_imdb.csv");
writer.append("Title, Link\n");
// Itere sobre e salve os títulos e ações no arquivo CSV
int count = 0;
for (int i = 0; i < titles.size() && count < 10; i++) {
String title = titles.get(i).getText();
String action = actions.get(i).getAttribute("href");
writer.append(String.format("\"%s\", \"%s\"\n", title, action));
count++;
}
writer.flush(); // Ensure everything is written to the file
writer.close(); // Close the writer
} catch (Exception e) {
e.printStackTrace();
} finally {
driver.quit();
}
}
}
Agora você pode salvar os dados extraídos do IMDb em um arquivo de texto ou CSV, facilitando a análise ou o compartilhamento!
Ao realizar web scraping, é crucial garantir que o processo seja seguro tanto para o scraper quanto para o site de destino. Aqui estão algumas melhores práticas de segurança:
- Evite sobrecarregar um site com requisições de um único endereço IP. Use proxies para rotacionar endereços IP e distribuir a carga.
- Alguns sites possuem medidas como CAPTCHA ou outras técnicas anti-scraping. É essencial lidar com essas situações de forma eficaz, possivelmente utilizando ferramentas como o CapMonster Cloud para resolver CAPTCHAs.
- Para evitar ser marcado como um bot, controle a frequência das suas requisições adicionando atrasos entre elas. Isso imita o comportamento humano de navegação e previne a sobrecarga do servidor.
- Altere a string do User-Agent no seu scraper para simular diferentes navegadores. Isso ajuda a prevenir a detecção.
- Tenha cuidado para não armazenar dados sensíveis do usuário (como senhas) durante o processo de scraping. Siga as leis de proteção de dados, como o GDPR, quando aplicável.
- E, por fim, sempre verifique os Termos de Serviço (TOS) do site e garanta que o scraping é permitido. Ignorar isso pode levar a consequências legais.
Para acelerar o processo de web scraping e torná-lo mais eficiente, considere estas dicas:
- Use navegadores headless como Chrome ou Firefox em modo não-GUI para acelerar o scraping. Isso remove o sobrecarga de renderização da interface do usuário.
Exemplo: use o ChromeOptions no Selenium para rodar em modo headless.
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless");
WebDriver driver = new ChromeDriver(options);- Armazene dados em cache sempre que possível para evitar solicitar as mesmas informações várias vezes. Se você estiver lidando com grandes conjuntos de dados, armazenar os resultados em um banco de dados local pode ser mais eficiente.
- Use seletores XPath e CSS mais eficientes para minimizar a navegação no DOM. Evite seletores excessivamente genéricos que possam resultar em verificações desnecessárias. Por exemplo, em vez de usar findElement(By.xpath("//div[@class='example']/a"), utilize um caminho mais específico sempre que possível.
- Se a página não exigir JavaScript para renderizar o conteúdo, evite o uso de ferramentas como o Selenium e opte por bibliotecas mais rápidas, como o Jsoup, que fazem a análise do HTML diretamente.
- Processamento paralelo: Use múltiplas threads ou processos para fazer scraping de várias páginas simultaneamente. Isso pode reduzir drasticamente o tempo necessário para fazer scraping de um grande número de páginas.
Ferramentas: considere o uso de bibliotecas como o ExecutorService em Java para multi-threading.
Aqui está um exemplo de paralelismo em Java para web scraping, usando a biblioteca java.util.concurrent, que fornece ferramentas para programação multithread.
import java.io.IOException;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class ParallelWebScraping {
// Método para raspar o conteúdo de uma página
public static String scrapePage(String url) throws IOException {
System.out.println("Scraping URL: " + url + " in thread: " + Thread.currentThread().getName());
Document doc = Jsoup.connect(url).get();
return doc.title(); // Returning the page title as an example
}
public static void main(String[] args) {
// Lista de URLs para raspar
List<String> urls = Arrays.asList(
"https://example.com",
"https://example.org",
"https://example.net"
);
// Crie um pool de threads fixo
ExecutorService executorService = Executors.newFixedThreadPool(3);
try {
// Crie tarefas para execução paralela
List<Callable<String>> tasks = urls.stream()
.map(url -> (Callable<String>) () -> scrapePage(url))
.toList();
// Execute as tarefas e colete os resultados.
List<Future<String>> results = executorService.invokeAll(tasks);
// Imprima os resultados
for (Future<String> result : results) {
System.out.println("Page title: " + result.get());
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// Desligue o pool de threads
executorService.shutdown();
}
}
}- Definimos uma lista de URLs para fazer o scraping.
- Um pool de threads fixo é criado para limitar o número de threads que estão sendo executadas simultaneamente.
- Cada Callable representa uma tarefa que retorna um resultado após a execução (neste caso, o título da página).
- O método invokeAll executa todas as tarefas em paralelo e retorna uma lista de objetos Future que contêm os resultados.
- A biblioteca Jsoup é usada para buscar e analisar as páginas da web.
- Extraímos os títulos das páginas (ou outros dados) dos objetos Future.
Java é uma excelente escolha para web scraping, oferecendo ferramentas poderosas e bibliotecas para extração de dados. Neste artigo, discutimos abordagens chave, incluindo scraping estático e dinâmico, trabalhando com APIs, e compartilhamos dicas úteis para um processamento de dados mais eficiente.
Com ferramentas como o CapMonster Cloud para contornar CAPTCHAs, Java permite que você enfrente até as tarefas mais desafiadoras. Experimente, expanda suas habilidades e explore novas formas de automatizar. O mundo dos dados está esperando para ser descoberto por você!
- O que é web scraping e como funciona?
Web scraping é o processo de extrair dados automaticamente de páginas da web. Ele envolve o uso de software para recuperar o código HTML de uma página, extrair as informações necessárias e, em seguida, processá-las ou salvá-las.
- Quais são as melhores ferramentas para web scraping em Java?
As ferramentas populares para web scraping em Java incluem:
- Jsoup — para análise de HTML.
- Selenium — para automação de navegador, especialmente para sites dinâmicos.
- HtmlUnit — um navegador leve para automação.
- Como posso contornar proteções contra scraping (como CAPTCHA)?
Para contornar CAPTCHAs, você pode usar serviços como o CapMonster Cloud, que resolve automaticamente CAPTCHAs para seu script, permitindo que você continue o scraping sem atrasos.
- Posso usar web scraping em todos os sites?
Nem todos os sites permitem web scraping. Antes de começar, você deve verificar os termos de serviço do site para garantir que o scraping seja permitido. Muitos sites utilizam proteções como CAPTCHA ou bloqueio de IP para impedir o scraping.
- Quais tipos de dados posso extrair com web scraping?
Você pode extrair diversos tipos de dados, como:
- Texto (por exemplo, títulos, descrições).
- Preços de produtos.
- Dados de usuários.
- Conteúdo de notícias.
- Dados estruturados, como tabelas e listas.
- Como eu lido com conteúdo dinâmico nos sites?
Para conteúdo dinâmico que é carregado via JavaScript, você pode usar ferramentas como o Selenium, que simulam ações de usuário em um navegador e permitem extrair dados de páginas geradas dinamicamente.
- Como posso acelerar o processo de scraping?
- Use multithreading e requisições paralelas para acelerar a coleta de dados.
- Limite a frequência de requisições para evitar bloqueios.
- Use servidores proxy para distribuir a carga.
- O que devo fazer se o site bloquear minhas requisições?
Se o site bloquear suas requisições, você pode:
- Usar proxies para alterar seu endereço IP.
- Adicionar atrasos entre as requisições.
- Alterar seu agente de usuário para simular navegadores reais.
- Usar fingerprinting para emular sessões reais de navegador. Fingerprinting envolve alterar cabeçalhos de requisição e outros dados de sessão (como cookies, referers e accept-languages) para fazer suas requisições parecerem mais com aquelas de um usuário real.
- Utilizar serviços de resolução de CAPTCHA.