Web Scraping with Python and Selenium: Tutorial and Examples
Website scraping is the process of extracting data from web pages. This process usually involves using a program or scripts that retrieve information presented on websites, which can be used in different areas and for different purposes. For example, to compare competitors' prices and services, analyze consumer preferences, monitor various news and events, and much more. To go deeper into web scraping with Selenium and CapMonster Cloud, check out our comprehensive guide.
The steps of web scraping include:
- Defining objectives: The first step is to understand what information needs to be extracted and on which web resources.
- Analyze the structure of the target web page: Examine the HTML code of pages to understand where and how the desired information is stored. Finding and defining elements such as tags, IDs, classes, etc.
- Development of a script to retrieve data: Writing a code (e.g., in Python using the Selenium browser automation library) that will visit web pages, retrieve the necessary data and save it in a structured form.
- Data processing: Extracted data often requires transformation for further use. This may include removing duplicates, correcting formats, filtering unnecessary data, etc.
- Data saving: Save extracted and processed data in a convenient format, e.g. CSV, JSON, database, etc.
It is also important to keep track of changes on the target site so that you can update the script in a timely manner if necessary.
The Python programming language and Selenium library are often used for web scraping for the following reasons:
- Ease of use: Python is easy to use and has many libraries for web scraping.
- Action emulation, access to dynamic content: With Selenium you can automate user actions in a web browser, including emulation of page scrolling and clicking buttons required to load data.
- Anti-crawlers: Some sites have special security mechanisms, and using emulation of real user actions helps to bypass these mechanisms.
- Broad support: A large community and many resources make these tools easy to use.
Let's look at an example of a simple script for web scraping. For the example, let's take the page https://webscraper.io/test-sites/e-commerce/allinone/product/123, where we will search in the product card for the price of 128 GB HDD capacity.
- If you don't have Python installed on your computer yet, go to the official Python website and download the appropriate version for your operating system (Windows, macOS, Linux). In the terminal of your development environment, you can check the Python version with the following command:
- Next, you need to install Selenium by executing the command:
- Create a new file and import the required libraries:
- It is also necessary to add the 'By' class to the project, we will need it to define strategies for searching elements on the web page in Selenium:
ChromeDriver options (ChromeOptions) are needed to configure the behavior and startup settings of the Chrome browser when automating with Selenium. Here are some of these options:
A full list of parameters can be viewed here.
- In our example, incognito mode is set. Initialize the Chrome driver and navigate to the desired product card page:
In Selenium, the search for elements on a web page is performed using various methods provided by the By class. These methods allow you to find elements by various criteria, for example, element ID, class name, tag name, attribute name, link text, XPath or CSS selector.
Example of an ID search:
By class name:
By tag name:
By attribute name:
By link text:
By CSS selector:
By XPath:
If you need to find multiple elements, the find_elements method is used instead of find_element.
- In our example, we need to find the location of the “128” button element and price information:
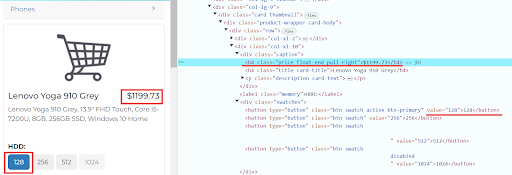
In Selenium, simulation of actions on a web page is performed using methods provided by the WebElement object. These methods allow you to interact with elements on the page the way a user does: click, enter text, etc.
Here are a few such methods:
- Let's go back to our example. XPath is used to search for the desired button, and then you need to click on it and find the element with the price:
- Now it remains to print the price of the product with the required HDD volume to the console:
So here's what the full code looks like:
It is very common for websites to display various banners and pop-ups that can interfere with script execution. In such cases, you can configure ChromeDriver settings to disable these elements. Here are some of such settings:
On the website we are using in our example, a cookie banner appears when the page loads. You can also try to remove it in other ways, one of which is to use a separate script that blocks such notifications. Let's start by examining this element:
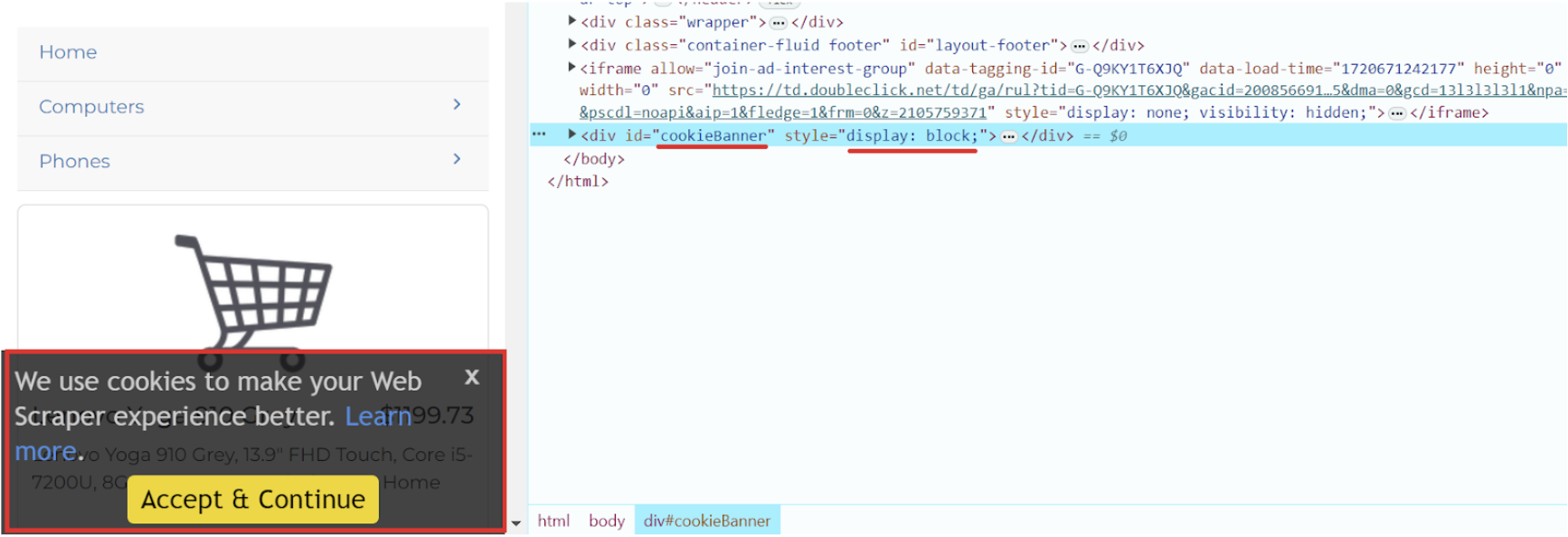
Now we can hide this banner by adding it to our script:
Another effective way is to use Chrome extensions that automatically accept or block all cookie banners. You can install these extensions in your browser and then plug them into ChromeOptions. Download a suitable extension in .crx format. Use it in your script:
This approach will save you from having to manually interact with such elements when the page loads.
Often when extracting data, there are obstacles in the form of captchas designed to protect against bots. To overcome such limitations, specialized services that recognize different types of captchas are most effective. One such tool is CapMonster Cloud, which can automatically solve even the most complex captchas in the shortest possible time. This service offers both browser extensions (for Chrome, for Firefox) and API methods (you can read about them in the documentation), which you can integrate into your code to get tokens, successfully bypass the protection and continue the work of your script.
This script solves the captcha on a page, and then extracts the header of the same page and outputs it to the console:
Using Python and Selenium for web scraping opens up many opportunities to automate the collection of data from websites, while integration with Capmonster Cloud helps you easily solve captchas and greatly simplifies the data collection process. These tools not only make your work faster, but also ensure that the data you collect is accurate and reliable. You can use them to collect data from a wide variety of sources, from online stores to news sites, and use it to analyze, research, or create your own projects. And you don't have to have advanced programming knowledge - modern technologies make web scraping accessible even for beginners. So, if simplicity, maximum convenience and time-saving in working with data are important for you, Python, Selenium and Capmonster Cloud are the perfect combination to achieve this goal! You can find out more about how to use Selenium in our comprehensive guide.
Note: We'd like to remind you that the product is used to automate testing on your own websites and on websites to which you have legal access.