Web Scraping in Python: Efficient Data Collection Automation
Web scraping is a method of gathering data from websites. It allows you to extract the necessary information for analysis, price monitoring, news tracking, and various other purposes. Web scrapers or parsers are tools used to perform web scraping. The most convenient and popular language for writing web scrapers is Python, although almost any language can be used for this purpose. Users choose Python for several reasons: its easy syntax, a wide range of handy libraries for parsing, and constant support and updates.
- Tags: An HTML document consists of various tags that define the structure and content. For example:
<html>: The root element of an HTML document.<head>: Contains metadata like the page title (<title>) and links to styles.<body>: The main part of the document, containing the visible content of the page.
- Elements: Inside tags, there can be elements like:
<h1>,<h2>, ...,<h6>: Headers of various levels.<p>: A paragraph of text.<a>: A link.<img>: An image.<div>,<span>: Containers for grouping other elements.
- Attributes: Tags can have attributes that provide additional information about the element. For example:
<a href="https://example.com">: Thehrefattribute specifies the URL for a link.<img src="image.jpg" alt="image description">: Thesrcattribute specifies the path to the image, andaltprovides alternative text.
Before selecting appropriate tools to write a scraper, you need to study the target website and determine if it contains dynamic content. To do this, load the page, open the Network tab in Developer Tools, and check if Fetch/XHR requests are being made (these technologies allow web pages to dynamically update content based on data received from the server):
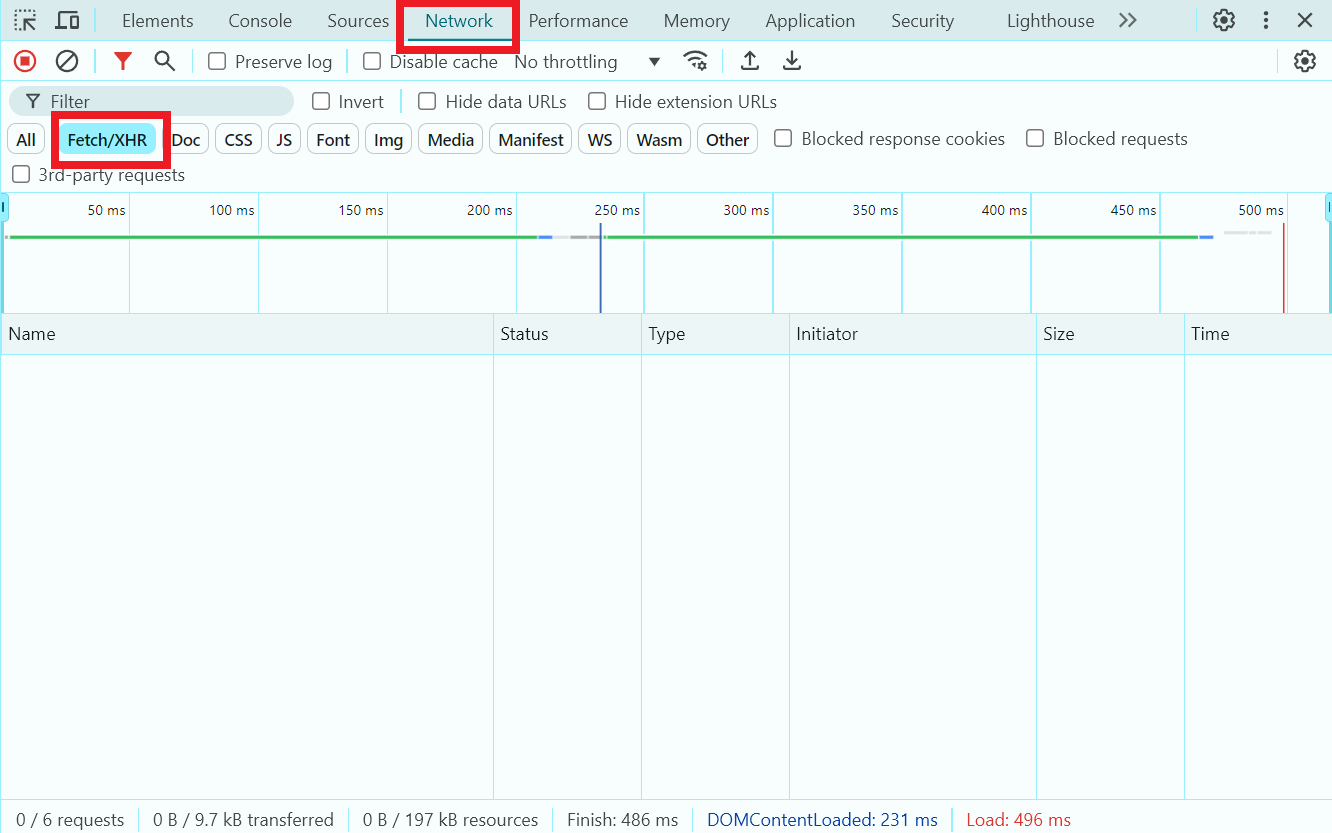
- If Fetch/XHR requests are not being made: You can use libraries like BeautifulSoup and requests.
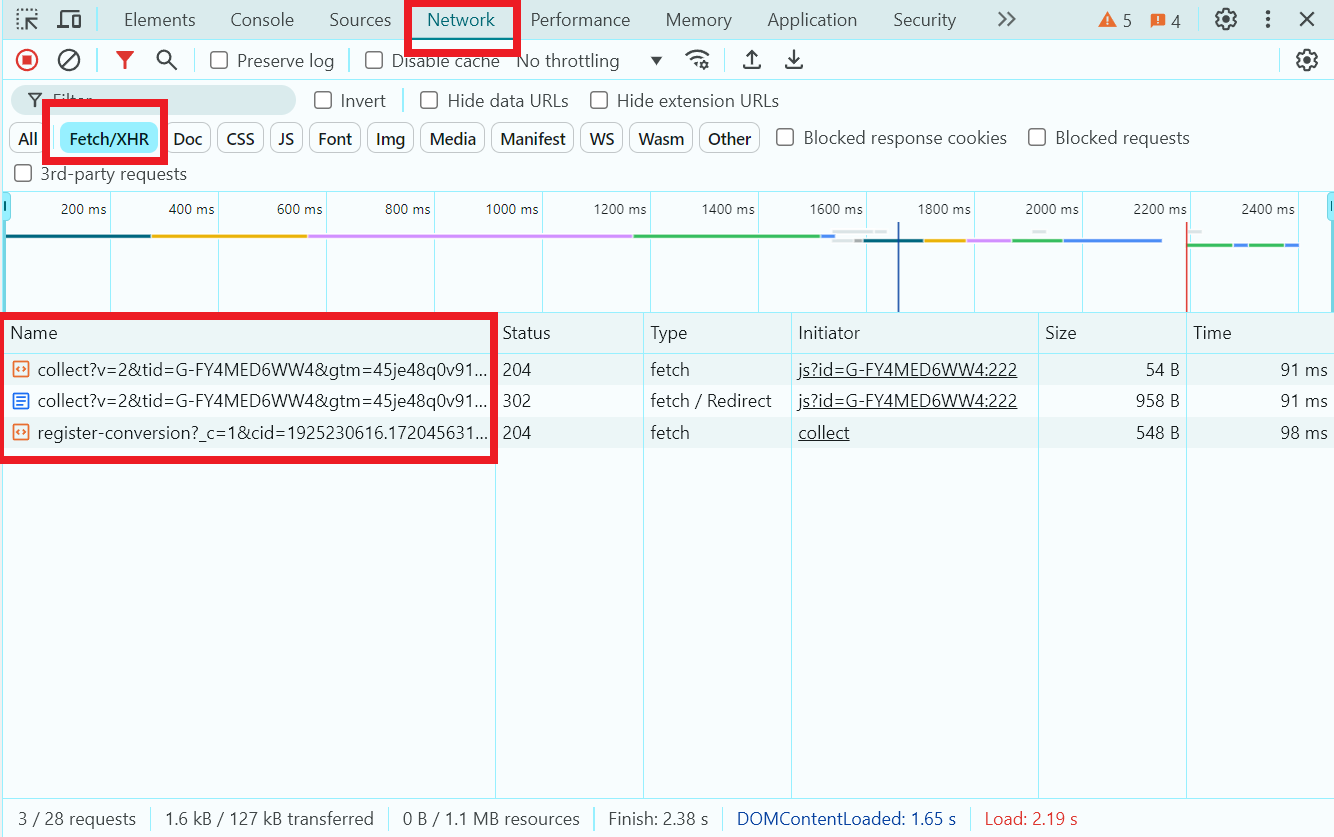
- If the website contains dynamic content: You should use tools like Selenium or Playwright to load the web pages.
For a test static page to extract some data, we’ll choose https://quotes.toscrape.com/. Let’s write a simple scraper to extract the first three quotes and their authors.
For our purpose, the BeautifulSoup and requests libraries are sufficient. Let’s create a new file in the editor/IDE and add the libraries to the project using the command:
pip install beautifulsoup4 requests
BeautifulSoup facilitates searching and extracting data:
By Tags:
title_tag = soup.title print(title_tag) # <title>Page Title</title>By Text: To extract text from a tag, use the
.get_text()method:header_text = soup.h1.get_text() print(header_text) # HeaderBy Classes, IDs, and Attributes:
elements = soup.find_all(class_='my-class') element = soup.find(id='my-id') links = soup.find_all('a', href=True)For More Complex Queries: You can use CSS selectors with the
.select()method:headers = soup.select('h1')
Let’s return to the target page, find the necessary elements, and start writing the code.
Open the newly created file and import the previously installed libraries:
import requests
from bs4 import BeautifulSoupSpecify the URL of the required page, set the User-Agent header to simulate browser activity, and send a GET request to the page:
url = 'https://quotes.toscrape.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(url, headers=headers)Check if the request was successful:
if response.status_code == 200:
# Create a BeautifulSoup object to parse the HTML
soup = BeautifulSoup(response.text, 'html.parser')In a separate browser window with the target page open, locate all blocks with quotes, iterate over the first three quote blocks, and extract the quote text in your code:
Tip: For quick searching and analysis of the necessary information, hover your cursor over the desired element, right-click, and select "Inspect." This will open Developer Tools, where you can view the element in the HTML structure of the page and explore additional elements it may contain. Highlighting the selected elements makes the task easier.
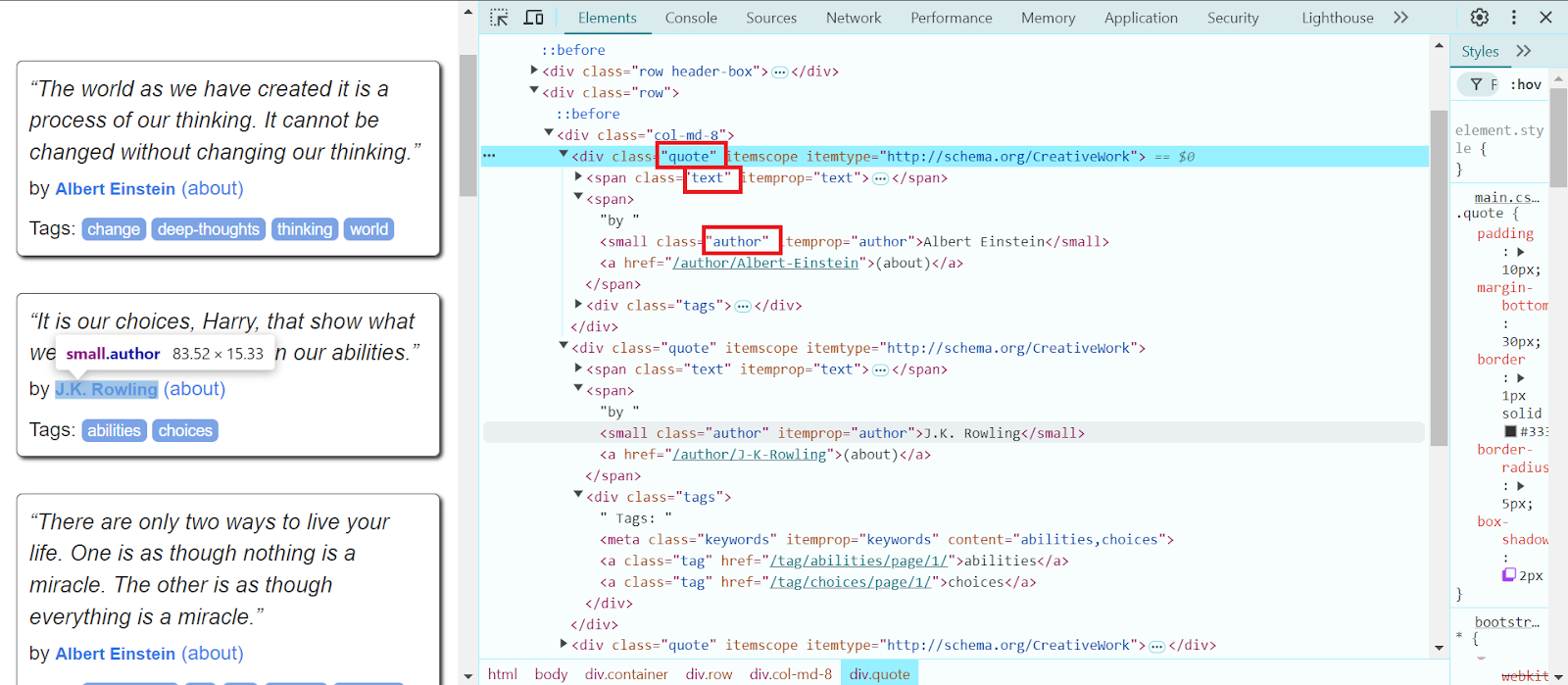
quotes = soup.select('.quote')
for quote in quotes[:3]:
text = quote.select_one('.text').get_text(strip=True)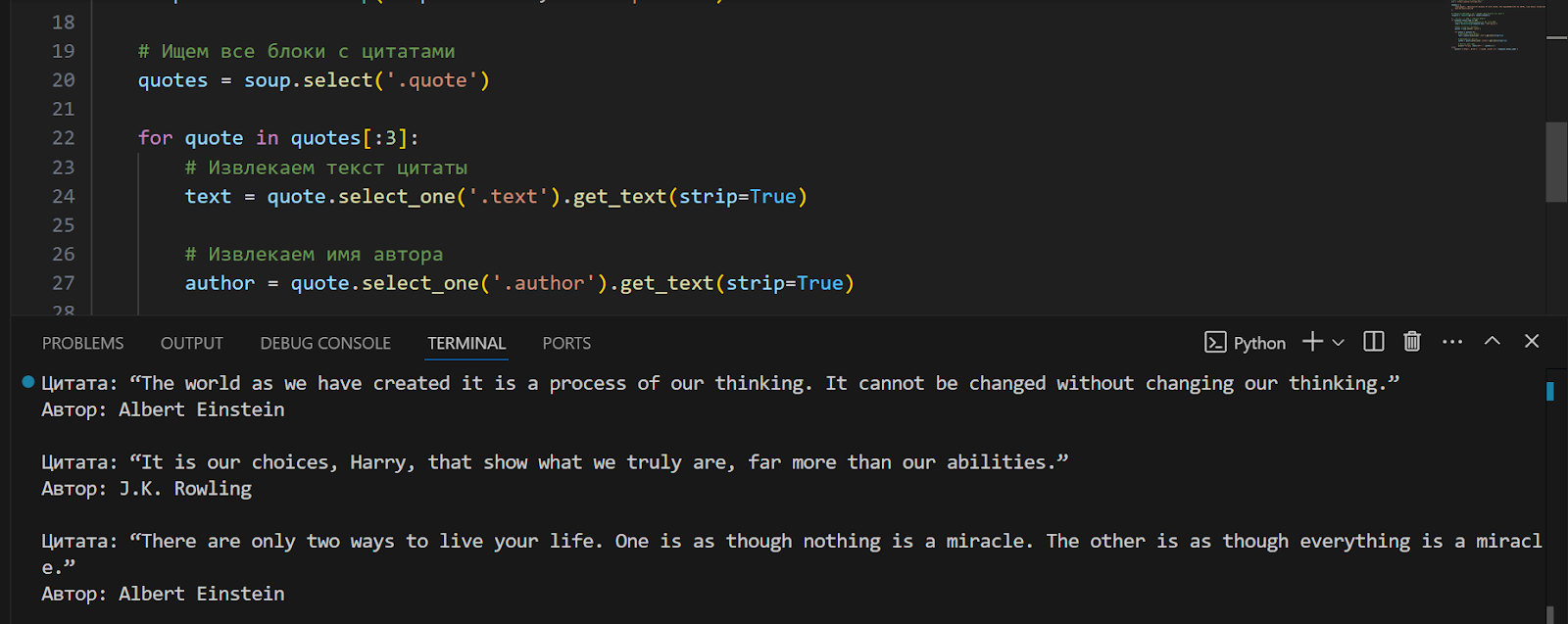
As an example of scraping a dynamic website, let's use https://parsemachine.com. Specifically, we'll work with the test page https://parsemachine.com/sandbox/catalog/, which displays cards for 12 products. We'll try to extract the name of each product and its link. Since the site is dynamic, we'll use Playwright. This browser automation tool finds and extracts elements on web pages using CSS, XPath selectors, text, and ARIA selectors, and it supports combining selectors for precise selection.
First, create a new project, install Playwright, and the Chromium browser with the following commands:
pip install playwright playwright install chromiumNext, find the elements you are interested in using the Developer Tools. Import Playwright, launch the browser, and navigate to the desired page:
from playwright.sync_api import sync_playwright url = 'https://parsemachine.com/sandbox/catalog/' def scrape_with_playwright(): with sync_playwright() as p: browser = p.chromium.launch(headless=False) page = browser.new_page() page.goto(url)We’ll look for all product cards, iterate over each card, and extract the link to the product page:
product_cards = page.query_selector_all('.card.product-card') for card in product_cards: title_tag = card.query_selector('.card-title .title') title = title_tag.inner_text() if title_tag else 'No title available'Extract the product page link:
product_link = title_tag.get_attribute('href') if title_tag else 'No link available'If the link is relative, add the base URL:
if product_link and not product_link.startswith('http'): product_link = f'https://parsemachine.com{product_link}'Finally, close the browser and define the function to run the script:
browser.close() scrape_with_playwright()Here’s the complete code:
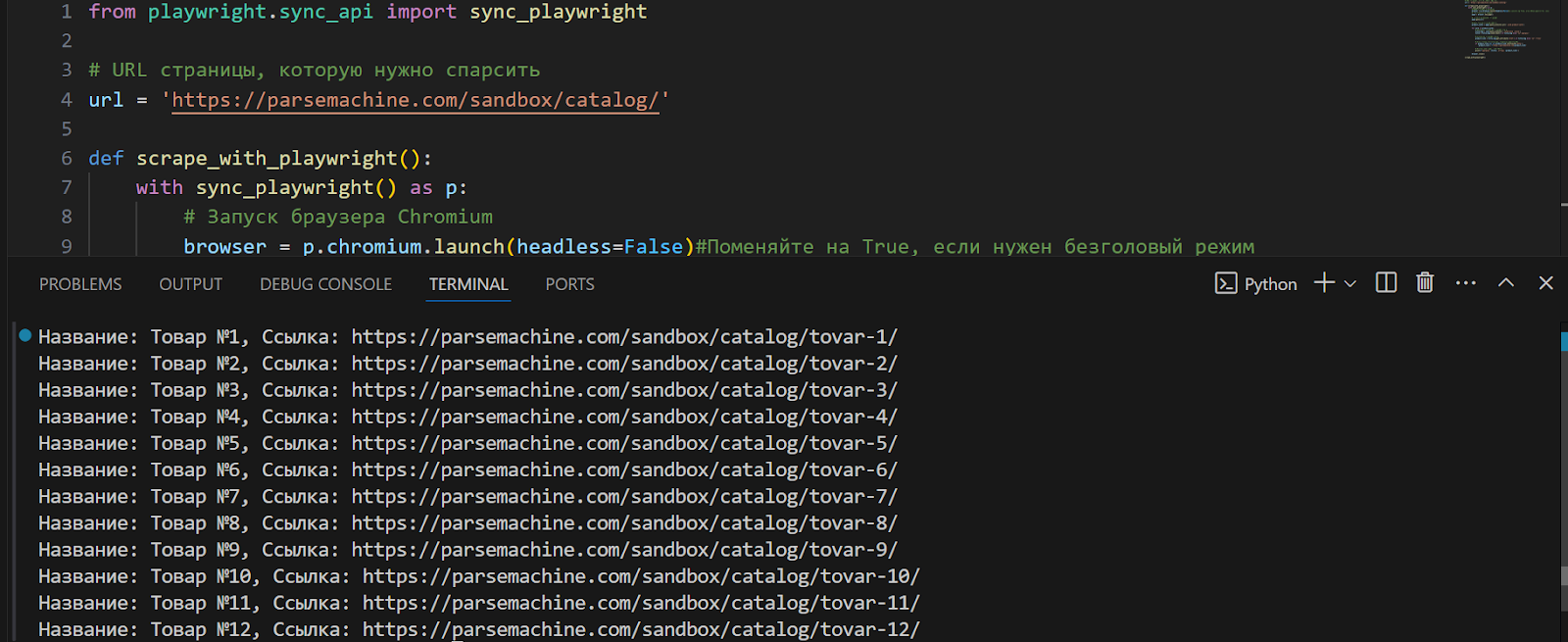
from playwright.sync_api import sync_playwright # URL of the target page url = 'https://parsemachine.com/sandbox/catalog/' def scrape_with_playwright(): with sync_playwright() as p: # Launch Chromium browser browser = p.chromium.launch(headless=False) # Change to True for headless mode # Open a new tab page = browser.new_page() # Navigate to the target page page.goto(url) # Find all product cards product_cards = page.query_selector_all('.card.product-card') for card in product_cards: # Extract the product title title_tag = card.query_selector('.card-title .title') title = title_tag.inner_text() if title_tag else 'No title available' # Extract the product link product_link = title_tag.get_attribute('href') if title_tag else 'No link available' # If the link is relative, add the base URL if product_link and not product_link.startswith('http'): product_link = f'https://parsemachine.com{product_link}' # Print product information print(f'Title: {title}, Link: {product_link}') browser.close() scrape_with_playwright()Run the script, and it will output the required information – the names of each product listed on the page and their respective links.
To save the extracted information, it's essential to understand a bit about the formats used for storing results:
CSV – One of the most popular formats for storing tabular data. It is a text file where each line corresponds to a single record, and values are separated by commas. Advantages of this format include: support by most data processing applications, including Excel; ease of reading and editing using text editors. Disadvantages: limited capabilities for storing complex data structures (e.g., nested data); issues with escaping commas and special characters.
JSON – A text-based data interchange format that is convenient for representing structured data. It is widely used in web development. Pros: supports nested and hierarchical data structures; well-supported by most programming languages; easily readable by both humans and machines. JSON is suitable for storing data that may need to be transmitted via APIs. Cons: JSON files can be larger compared to CSV; processing can be slower due to its more complex structure.
XLS – Designed for Excel spreadsheets, it stores data about cells, formatting, and formulas. It is commonly used for storing databases. To work with XLS in Python, you need third-party libraries, such as pandas. This format allows for storing data in a readable and presentable format. The main drawback is the need for additional libraries, which can increase server load and data processing time.
XML – A markup language used for storing and transmitting data. It supports nested structures and attributes. Pros: structured; allows for storing complex data structures; well-supported by various standards and systems. Cons: XML files can be bulky and complex to process; processing XML may be slow due to its structure.
Databases are used for storing large volumes of structured data. Examples include MySQL, PostgreSQL, MongoDB, SQLite. Pros: supports large volumes of data and quick access; easy to organize and relate data; supports transactions and data recovery. Cons: requires extra effort for setup and maintenance.
For our scrapers, we will choose the CSV format because the extracted data is tabular (quote text and author, product names and links) and the data volume is relatively small, without nested structures. Additional information on how to read and write in this format can be found here. We will add CSV import to our quote code, create a writer object, and write the quote data (the quotes themselves and their authors):
with open('quotes.csv', 'w', newline='', encoding='utf-8') as csvfile: csvwriter = csv.writer(csvfile) csvwriter.writerow(['Quote', 'Author']) for quote in quotes[:3]: text = quote.select_one('.text').get_text(strip=True) author = quote.select_one('.author').get_text(strip=True) csvwriter.writerow([text, author])We will also add additional console outputs and error handling:
print("Data successfully written to quotes.csv") except requests.RequestException as e: print(f'Error requesting the page: {e}') except Exception as e: print(f'An error occurred: {e}')Here’s the complete updated code:
import requests from bs4 import BeautifulSoup import csv # URL of the target page url = 'https://quotes.toscrape.com/' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.6613.85 Safari/537.36' } try: # Send a GET request to the page with the user agent response = requests.get(url, headers=headers) response.raise_for_status() # Check for HTTP errors # Create a BeautifulSoup object for parsing HTML soup = BeautifulSoup(response.text, 'html.parser') # Find all blocks with quotes quotes = soup.select('.quote') # Open CSV file for writing with open('quotes.csv', 'w', newline='', encoding='utf-8') as csvfile: # Create a writer object csvwriter = csv.writer(csvfile) # Write headers csvwriter.writerow(['Quote', 'Author']) # Write quote data for quote in quotes[:3]: # Extract the quote text text = quote.select_one('.text').get_text(strip=True) # Extract the author's name author = quote.select_one('.author').get_text(strip=True) # Write to CSV file csvwriter.writerow([text, author]) print("Data successfully written to quotes.csv") except requests.RequestException as e: print(f'Error requesting the page: {e}') except Exception as e: print(f'An error occurred: {e}')We will perform similar actions with the second scraper:
from playwright.sync_api import sync_playwright import csv # URL of the target page url = 'https://parsemachine.com/sandbox/catalog/' def scrape_with_playwright(): try: with sync_playwright() as p: # Launch Chromium browser browser = p.chromium.launch(headless=False) # Change to True for headless mode try: # Open a new tab page = browser.new_page() # Navigate to the target page page.goto(url) # Find all product cards product_cards = page.query_selector_all('.card.product-card') # Open CSV file for writing with open('products.csv', 'w', newline='', encoding='utf-8') as csvfile: # Create a writer object csvwriter = csv.writer(csvfile) # Write headers csvwriter.writerow(['Title', 'Link']) # Extract data from product cards and write to CSV for card in product_cards: # Extract product title title_tag = card.query_selector('.card-title .title') title = title_tag.inner_text() if title_tag else 'No title available' # Link to the product page product_link = title_tag.get_attribute('href') if title_tag else 'No link available' # If the link is relative, add the base URL if product_link and not product_link.startswith('http'): product_link = f'https://parsemachine.com{product_link}' # Write data to CSV file csvwriter.writerow([title, product_link]) # Print product information print(f'Title: {title}, Link: {product_link}') print("Data successfully written to products.csv") except Exception as e: print(f'Error working with Playwright: {e}') finally: # Close the browser browser.close() print("Browser closed.") except Exception as e: print(f'Error launching Playwright: {e}') scrape_with_playwright()Changing, Complex Website Structure: One of the most common obstacles in web scraping is the changing structure of the website and code obfuscation. Even minor changes in the HTML markup or page structure can cause scraping scripts to stop working. This may require frequent code updates to adapt to new changes.
Request Limits: Many websites have limits on the number of requests that can be sent within a certain timeframe. If your requests exceed the set limits, your IP address may be temporarily blocked.
IP Blocking: Websites can block IP addresses that they identify as suspicious or overly active, which can be a significant obstacle for scraping. In this case, quality proxy servers may be needed to bypass such blocks.
CAPTCHA: Many web resources implement protective measures in the form of CAPTCHAs to prevent automated actions. CAPTCHA requires manual input or the use of specialized services to bypass.
One of the best services today is CapMonster Cloud – its API allows for easy integration into code for bypassing CAPTCHA and continuing scraper operation. It is easy to connect, provides quick solutions for various types of CAPTCHAs with minimal errors – it supports reCAPTCHA, DataDome, Amazon CAPTCHA, and others. CapMonster Cloud can be considered an optimal choice as an auxiliary tool and an important part of the web scraping process.
- Use Proxy and User-Agent Rotation: To avoid IP blocking and bypass request limits, this helps mimic requests from various devices and browsers.
- Add Error Handling and Retries: A web page may be temporarily unavailable, or a request may fail. A retry mechanism and error handling will help ensure your script is resilient to such situations and prevent the scraping process from being interrupted.
- Review the website’s robots.txt file: This file contains guidelines for bots about which parts of the site can and cannot be crawled. Adhering to these recommendations helps avoid legal issues and conflicts with site owners.
- Introduce Random Delays Between Requests: To avoid suspicious activity and reduce the likelihood of blocking.
These recommendations will help your script mimic the behavior of a real user, thus reducing the chance of detection.
In summary, web scraping in Python is one of the most popular methods for efficiently collecting data from various websites. We discussed how to choose the right tools for web scraping, the installation process of Python and necessary libraries, and writing code to extract data and save results in convenient formats. With the step-by-step approach described in this article, even a novice developer can master the basic techniques of web scraping and create their first scraper scripts. Web scraping opens up significant opportunities for data analysis, information gathering, market monitoring, and many other tasks. It's essential to continue learning new tools and techniques to stay relevant in this ever-evolving field.
By using libraries and tools such as BeautifulSoup, requests, Selenium, Playwright, and others mentioned in this guide, you can extract information from both static and dynamic sites. When working with web scraping, it's important to consider legal and ethical aspects, as well as be prepared to bypass various obstacles such as CAPTCHA or dynamic content loading.
Each of the discussed tools and approaches has its advantages and limitations. The choice of the right tool depends on the specifics of the task, the complexity of the web pages, and the volume of data. For effective web scraping, understanding the characteristics of the web pages you are working with is crucial.
We hope that these instructions will help you better understand the web scraping process and provide the necessary foundational knowledge to create your own scrapers. Good luck with your data collection and analysis projects!
Note: We'd like to remind you that the product is used to automate testing on your own websites and on websites to which you have legal access.