Web Crawling with Python: The Ultimate Guide
Web crawling is a helpful way to collect data from the internet, often used for indexing websites, tracking changes, or gathering large amounts of information. In this article, we’ll break down the basics of web crawling, introduce you to useful tools and libraries in Python, and walk you through simple examples to help you get started!
Web crawling is the process of automatically navigating the internet to gather information from websites. It involves exploring multiple pages on a single site (or even across many sites) to collect vast amounts of data. Large-scale crawlers are used by search engines and other companies to index websites and gather data for various purposes.
For example: Googlebot visits billions of pages every day, following links between pages and websites to keep Google’s search results up-to-date. Googlebot starts by visiting a few key URLs and then follows the links on those pages to discover new ones. It uses smart algorithms to decide which pages to crawl and how often, so it can provide the most relevant search results for users.
Python is a great choice for web crawling because it’s simple to learn and has many helpful libraries. Tools like Scrapy, BeautifulSoup, and Selenium make it easy to crawl websites and collect data, no matter how simple or complex the task is.
Web crawling and web scraping are closely related, but they’re not the same thing.
Web Crawling is like a spider that moves from page to page across a website (or even multiple websites) to collect data. It’s more about exploring and indexing large amounts of information, usually by following links between pages.
Web Scraping, on the other hand, focuses on extracting specific pieces of data from a webpage. It’s like zooming in on the details — such as gathering product prices, contact info, or text from a single page or a set of pages.
So, crawling is the process of discovering and collecting data across many pages, while scraping is the act of pulling out specific information from those pages.
Let’s walk through an example of how a basic web crawler gathers information from a website.
- Starting with Seed URLs
Imagine you want to collect information about blog posts on a website. Your seed URL could be the homepage of the blog, such as https://example.com.
- Requesting the Web Page
The crawler sends an HTTP request to https://example.com, asking the server to send back the HTML content of the homepage. The server responds with the HTML of the page.
- Parsing the HTML Content
The crawler then parses the HTML of the homepage. It looks for specific elements, such as links to blog posts (which are usually contained in <a> tags) and other useful information like page titles or metadata.
- Extracting Links
From the homepage, the crawler finds links to other pages—let's say it finds the following links:
https://example.com/blog/post1
https://example.com/blog/post2
https://example.com/about
The crawler adds these links to its list of pages to visit.
- Following Links
The crawler now requests the first blog post, https://example.com/blog/post1. It sends another HTTP request and retrieves the HTML content for that page.
- Parsing the Blog Post
On the blog post page, the crawler looks for additional links (e.g., links to other blog posts, categories, or tags) and data (e.g., the blog post title, author, and publication date). The data is extracted and stored.
- Extracting More Links
From https://example.com/blog/post1, the crawler finds links to other posts:
https://example.com/blog/post3
https://example.com/blog/post4
These new links are added to the list of URLs to crawl.
- Storing Data
The crawler collects the blog post title, author, date, and content from https://example.com/blog/post1 and stores it in a structured format, like a database or CSV file.
- Avoiding Redundancy
The crawler keeps track of URLs it has already visited. If it encounters https://example.com/blog/post1 again, it will skip it to avoid crawling the same page multiple times.
Before starting the crawl, the crawler checks the robots.txt file at https://example.com/robots.txt to ensure it’s allowed to crawl the site. If the file disallows crawling certain sections of the website (like an admin panel), the crawler will avoid those areas.
The crawler continues this process, visiting pages, extracting links, and collecting data until it has crawled all the pages or reached its limit.
This basic workflow allows the crawler to gather large amounts of data from across a website, following links and gathering the desired content in an automated manner.
Python offers a range of powerful libraries for web crawling, both built-in and third-party, that make it easy to collect data from websites. Here’s an overview of the standard libraries and some popular third-party options you can use for web crawling:
1. Standard Libraries
urllib
urllib is a built-in Python library that provides functions for working with URLs. It can be used to send HTTP requests, parse URLs, and handle responses. While not specifically designed for web crawling, it allows you to fetch pages, making it a basic tool for simple crawlers.
http.client
http.client is another standard library that can be used for handling HTTP requests. It offers more control over the request/response cycle and allows for a more customized approach to fetching data.
2. Third-Party Libraries
Requests
The requests library is one of the most popular third-party libraries for sending HTTP requests in Python. It simplifies the process of interacting with web pages and is often used in web scraping and crawling tasks. Requests allows for easy handling of GET, POST, and other HTTP requests.
BeautifulSoup
While not a crawler by itself, BeautifulSoup is often used in conjunction with crawlers to parse and extract data from HTML pages. It makes it easy to navigate and search the document tree, extract links, and parse content.
Scrapy
Scrapy is a powerful and flexible web crawling framework that is designed specifically for large-scale web scraping and crawling tasks. It allows you to define spiders (crawlers) that can navigate through websites and extract data automatically. Scrapy handles everything from making requests to storing scraped data, making it ideal for more complex crawling projects.
Selenium
Selenium is primarily known for automating browsers for web testing, but it is also frequently used in web crawling when dealing with dynamic web pages (JavaScript-heavy sites). It can interact with JavaScript and load content that isn’t immediately visible in the raw HTML.
The re library in Python is useful for extracting, processing, and manipulating text during web scraping. Here's how it can assist:
- Extracting Links: Use regular expressions to find all href attributes (links) in a page's HTML.
- Data Extraction: Easily extract specific data like prices or product names using patterns.
- Cleaning Data: Remove unwanted spaces or tags from the scraped content.
- Handling Dynamic Content: Extract data embedded in JavaScript or complex HTML structures.
- Filtering Elements: Search for elements with specific attributes (e.g., class or ID) using patterns.
While powerful and fast, regular expressions should be used carefully, as they can be hard to debug and may not be suitable for all HTML parsing tasks.
In this tutorial, we’ll walk through the process of building a simple web crawler in Python. This crawler will visit a website, extract links, and crawl through them to gather more data. We’ll be using the requests library to fetch pages and BeautifulSoup to parse the HTML. This example crawls pages starting from https://www.wikipedia.org/ and collects links it finds on each page, navigating through the website.
Before you begin, make sure you have:
Python 3+: Download the installer from the official website, run it, and follow the installation instructions.
A Python IDE: You can use Visual Studio Code with the Python extension or PyCharm Community Edition.
Documentation for requests and BeautifulSoup: Take a look at their official documentation to get familiar with how they work.
- Install required libraries
Before starting, you need to install the necessary libraries: requests and BeautifulSoup. You can install them using pip:
pip install requests beautifulsoup4- Set up logging
Logging will help you track what your crawler is doing. We’ll configure basic logging to show helpful messages as the crawler runs. This sets up the logging format and the logging level to INFO, which will display important messages during the crawl.
import logging
logging.basicConfig(
format='%(asctime)s %(levelname)s: %(message)s',
level=logging.INFO
)- Create the Crawler Class
The crawler will be contained in a class, which we will call SimpleCrawler. Inside this class, we’ll define methods for fetching pages, extracting links, and managing the crawling process.
class SimpleCrawler:
def __init__(self, start_urls=[]):
self.visited = set()
self.to_visit = start_urlsself.visited: A set to keep track of the URLs we’ve already visited.
self.to_visit: A list that stores URLs that we still need to crawl.
- Fetching a web page
The next step is creating a method to download the content of a page using the requests library.
def fetch_page(self, url):
"""Download the page content."""
try:
response = requests.get(url)
response.raise_for_status()
return response.text
except requests.exceptions.RequestException as e:
logging.error(f"Failed to fetch {url}: {e}")
return NoneThe fetch_page method sends a GET request to the provided URL.
If successful, it returns the HTML content of the page. Otherwise, it logs the error and returns None.
- Extracting links from a page
Now we need to extract the links (URLs) from the HTML of the page. We’ll use BeautifulSoup to parse the HTML and find all the <a> tags with the href attribute.
def extract_links(self, url, html):
"""Extract and yield all linked URLs from the page."""
soup = BeautifulSoup(html, 'html.parser')
for anchor in soup.find_all('a', href=True):
link = anchor['href']
full_url = urljoin(url, link)
yield full_urlBeautifulSoup(html, 'html.parser') parses the HTML content.
soup.find_all('a', href=True) finds all anchor tags with an href attribute.
urljoin(url, link) ensures that relative URLs are properly converted into absolute URLs.
- Adding URLs to the queue
We need a way to add new URLs to the list of URLs to visit, but only if they haven’t been visited before.
def add_to_queue(self, url):
"""Add a URL to the list of URLs to visit if it's not already visited or queued."""
if url not in self.visited and url not in self.to_visit:
self.to_visit.append(url)This method ensures that we don’t revisit URLs we’ve already crawled or added to the queue.
- Processing each page
Now let’s write the method to process each page. It will fetch the page, extract the links, and add them to the queue.
def process_page(self, url):
"""Process a single page and collect links."""
logging.info(f'Processing: {url}')
html = self.fetch_page(url)
if html:
for link in self.extract_links(url, html):
self.add_to_queue(link)This method calls the fetch_page method to download the page content and then extracts and queues the links found on the page.
- The crawling loop
The main loop will keep running until all URLs have been visited. It will pop a URL from the list of URLs to visit, process it, and mark it as visited.
def crawl(self):
"""Crawl the web starting from the initial URLs."""
while self.to_visit:
url = self.to_visit.pop(0)
if url not in self.visited:
self.process_page(url)
self.visited.add(url)The loop continues as long as there are URLs to visit.
It processes the URL, extracts links, and adds them to the queue.
It marks the URL as visited after processing it.
- Running the Crawler
Finally, let’s create an instance of the SimpleCrawler class and start crawling from a given list of URLs.
if __name__ == '__main__':
start_urls = ['https://www.wikipedia.org/']
crawler = SimpleCrawler(start_urls)
crawler.crawl()This part initializes the crawler with a list of starting URLs and begins the crawl.
Here’s the full code:
import logging
from urllib.parse import urljoin
import requests
from bs4 import BeautifulSoup
logging.basicConfig(
format='%(asctime)s %(levelname)s: %(message)s',
level=logging.INFO
)
class SimpleCrawler:
def __init__(self, start_urls=[]):
self.visited = set()
self.to_visit = start_urls
def fetch_page(self, url):
"""Download the page content."""
try:
response = requests.get(url)
response.raise_for_status()
return response.text
except requests.exceptions.RequestException as e:
logging.error(f"Failed to fetch {url}: {e}")
return None
def extract_links(self, url, html):
"""Extract and yield all linked URLs from the page."""
soup = BeautifulSoup(html, 'html.parser')
for anchor in soup.find_all('a', href=True):
link = anchor['href']
full_url = urljoin(url, link)
yield full_url
def add_to_queue(self, url):
"""Add a URL to the list of URLs to visit if it's not already visited or queued."""
if url not in self.visited and url not in self.to_visit:
self.to_visit.append(url)
def process_page(self, url):
"""Process a single page and collect links."""
logging.info(f'Processing: {url}')
html = self.fetch_page(url)
if html:
for link in self.extract_links(url, html):
self.add_to_queue(link)
def crawl(self):
"""Crawl the web starting from the initial URLs."""
while self.to_visit:
url = self.to_visit.pop(0)
if url not in self.visited:
self.process_page(url)
self.visited.add(url)
if __name__ == '__main__':
start_urls = ['https://www.wikipedia.org/']
crawler = SimpleCrawler(start_urls)
crawler.crawl()
Output example:
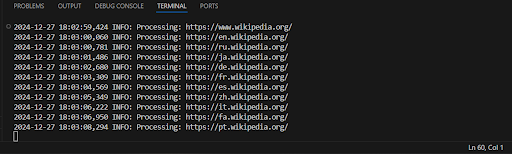
This crawler performs basic tasks of extracting links from web pages, but it has several limitations and shortcomings that may affect its performance, resilience, and scalability.
- No depth or page limit:
The crawler will continue scraping pages indefinitely, potentially overloading the server or getting stuck in loops. Pages might link to each other cyclically.
- Inefficient link handling:
All found links are added to the queue for visiting, but the crawler doesn't check if the link has already been processed (it checks only against the visited list).
Adding links to the to_visit list dynamically can cause the list to grow too large and lead to memory overflow.
- Single-threaded (serial) scraping:
This crawler works in a single thread, which makes it slow for large-scale scraping. It processes pages one by one, which increases scraping time.
- Lack of error handling or timeout management:
In case of HTTP errors like timeouts or temporary server issues, the crawler simply logs the error and continues. Improving this by adding better error handling and retry logic would make it more resilient.
- No robots.txt handling:
The crawler doesn't check if scraping is allowed by the site's robots.txt, which could lead to violating the site's scraping policy.
- No request delays:
Without delays between requests, the crawler might overload the server, leading to IP bans or blocking.
- No support for dynamic content:
This crawler works only with static content. It cannot handle pages that generate content dynamically using JavaScript.
- Use Multitasking or Multithreading:
Using concurrency (via modules like concurrent.futures or asyncio for asynchronous scraping) can significantly speed up the scraping process. Multithreaded crawlers process multiple pages at once, improving performance.
Example: aiohttp and asyncio for asynchronous requests.
- Use more advanced libraries:
Scrapy: a most popular framework for web crawling and scraping that includes built-in support for concurrency, session management, error handling, and more.
Playwright or Selenium: for handling dynamic pages that generate content using JavaScript.
Prevent Cyclic Links:
Adding logic to check for recursion depth or limiting the number of pages to visit can prevent the crawler from getting stuck in infinite loops.
- Introduce delays between requests:
Adding random delays between requests or fixed timeouts can help avoid overloading the server and prevent IP blocks.
- Improve error handling and retry logic:
Implement retry mechanisms for network errors or server-side errors (e.g., 500 or 503). The requests library supports Retry via urllib3.
- Use a database or file system for queue management:
Instead of storing links in memory, use a database (like SQLite or Redis) to manage the queue, improving scalability.
- Parallel processing:
Use libraries like Celery or Dask for distributed processing, enabling you to handle large-scale scraping tasks.
Now that we are familiar with the imperfections of our code and have learned about more efficient methods, let's rewrite our code and make it more successful:
import logging
from urllib.parse import urljoin
import requests
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor
logging.basicConfig(
format='%(asctime)s %(levelname)s: %(message)s',
level=logging.INFO
)
class SimpleCrawler:
def __init__(self, start_urls=[]):
self.visited = set()
self.to_visit = start_urls
self.found_links = []
def fetch_page(self, url):
"""Download the page content."""
try:
response = requests.get(url)
response.raise_for_status()
return response.text
except requests.exceptions.RequestException as e:
logging.error(f"Failed to fetch {url}: {e}")
return None
def extract_links(self, url, html):
"""Extract and yield all linked URLs from the page."""
soup = BeautifulSoup(html, 'html.parser')
for anchor in soup.find_all('a', href=True):
link = anchor['href']
full_url = urljoin(url, link)
if full_url not in self.visited and full_url not in self.to_visit:
self.found_links.append(full_url)
def process_page(self, url):
"""Process a single page and collect links."""
html = self.fetch_page(url)
if html:
self.extract_links(url, html)
self.visited.add(url)
def crawl(self):
"""Crawl the web starting from the initial URLs."""
with ThreadPoolExecutor(max_workers=10) as executor:
# Add initial URLs to the queue
while self.to_visit:
url = self.to_visit.pop(0)
if url not in self.visited:
executor.submit(self.process_page, url)
# Wait for all pages to be processed
executor.shutdown(wait=True)
return self.found_links
if __name__ == '__main__':
start_urls = ['https://www.wikipedia.org/']
crawler = SimpleCrawler(start_urls)
links = crawler.crawl()
print("Found links:")
for link in links:
print(link)
We’ve made some improvements to the crawler to enhance its speed and efficiency. The changes will help you gather links more quickly without any unnecessary delays.
What was changed:
- Multitasking: We used ThreadPoolExecutor for parallel page loading, which speeds up execution.
- Collecting all links at once: All the found links are saved in the found_links list, and the results are printed after processing all pages.
- Removal of intermediate outputs: Logging for each page was removed to speed up execution.
Explanation:
- ThreadPoolExecutor allows processing multiple pages simultaneously (in parallel), significantly speeding up the process, especially when there are many links.
- The found_links list stores all the links found on the pages. After all pages have been processed, these links are printed.
Output example:
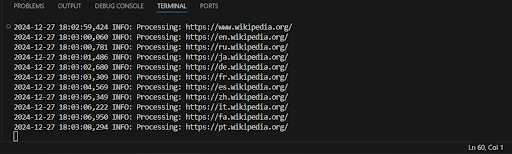
Hooray, now our code works much faster and outputs all the found links at once!
After running a web crawler, it’s important to store the data you collect. One of the most popular and easy ways to save crawled links is by using a JSON file. JSON is lightweight, easy to read, and widely used for data exchange. Let's look at how you can save your found links in a file and share a couple of ways to do it.
Here’s how you can do it using the SimpleCrawler example from before:
import json
import logging
from urllib.parse import urljoin
import requests
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor
logging.basicConfig(
format='%(asctime)s %(levelname)s: %(message)s',
level=logging.INFO
)
class SimpleCrawler:
def __init__(self, start_urls=[]):
self.visited = set()
self.to_visit = start_urls
self.found_links = []
def fetch_page(self, url):
try:
response = requests.get(url)
response.raise_for_status()
return response.text
except requests.exceptions.RequestException as e:
logging.error(f"Failed to fetch {url}: {e}")
return None
def extract_links(self, url, html):
soup = BeautifulSoup(html, 'html.parser')
for anchor in soup.find_all('a', href=True):
link = anchor['href']
full_url = urljoin(url, link)
if full_url not in self.visited and full_url not in self.to_visit:
self.found_links.append(full_url)
def process_page(self, url):
html = self.fetch_page(url)
if html:
self.extract_links(url, html)
self.visited.add(url)
def crawl(self):
with ThreadPoolExecutor(max_workers=10) as executor:
while self.to_visit:
url = self.to_visit.pop(0)
if url not in self.visited:
executor.submit(self.process_page, url)
executor.shutdown(wait=True)
return self.found_links
def save_to_json(self, filename):
"""Save the found links to a JSON file."""
with open(filename, 'w', encoding='utf-8') as file:
json.dump(self.found_links, file, ensure_ascii=False, indent=4)
logging.info(f"Found links saved to {filename}")
if __name__ == '__main__':
start_urls = ['https://www.wikipedia.org/']
crawler = SimpleCrawler(start_urls)
links = crawler.crawl()
# Save the links to a JSON file
crawler.save_to_json('found_links.json')
print("Found links have been saved to 'found_links.json'")The found_links.json file will look something like this:
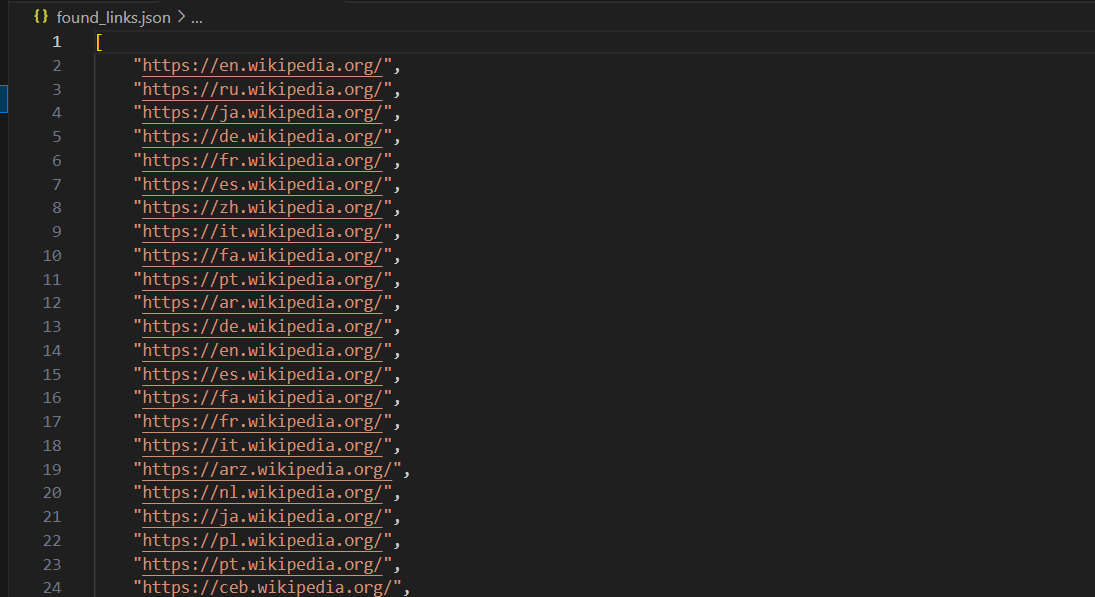
Different Ways to Save Crawled Links
Besides saving links to a JSON file, there are several other ways you can store the data you collect from web crawling. Here are a few popular methods:
Saving to a CSV File
A CSV file is another simple and widely used format for storing data. It's perfect for tabular data, and you can easily open CSV files with spreadsheet software like Excel or Google Sheets.
import csv
class SimpleCrawler:
# Previous code...
def save_to_csv(self, filename):
"""Save the found links to a CSV file."""
with open(filename, 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(['URL']) # Column header
for link in self.found_links:
writer.writerow([link])
logging.info(f"Found links saved to {filename}")
if __name__ == '__main__':
start_urls = ['https://www.wikipedia.org/']
crawler = SimpleCrawler(start_urls)
links = crawler.crawl()
# Save the links to a CSV file
crawler.save_to_csv('found_links.csv')
print("Found links have been saved to 'found_links.csv'")Saving to a Database (SQLite)
If you want to store your links in a database for easy querying, using SQLite is a good option. SQLite is a lightweight database that doesn't require a separate server and works well for small to medium-sized data storage needs.
import sqlite3
class SimpleCrawler:
# Previous code...
def save_to_database(self, db_name):
"""Save the found links to a SQLite database."""
conn = sqlite3.connect(db_name)
cursor = conn.cursor()
# Create a table if it doesn't exist
cursor.execute('''
CREATE TABLE IF NOT EXISTS links (
id INTEGER PRIMARY KEY AUTOINCREMENT,
url TEXT UNIQUE
)
''')
# Insert each link into the database
for link in self.found_links:
cursor.execute('INSERT OR IGNORE INTO links (url) VALUES (?)', (link,))
conn.commit()
conn.close()
logging.info(f"Found links saved to {db_name}")
if __name__ == '__main__':
start_urls = ['https://www.wikipedia.org/']
crawler = SimpleCrawler(start_urls)
links = crawler.crawl()
# Save the links to a SQLite database
crawler.save_to_database('found_links.db')
print("Found links have been saved to 'found_links.db'")Saving to an Excel File (XLSX)
If you prefer working with Excel, you can save your data directly to an Excel file using the openpyxl library.
from openpyxl import Workbook
class SimpleCrawler:
# Previous code...
def save_to_excel(self, filename):
"""Save the found links to an Excel file."""
workbook = Workbook()
sheet = workbook.active
sheet.append(['URL']) # Column header
for link in self.found_links:
sheet.append([link])
workbook.save(filename)
logging.info(f"Found links saved to {filename}")
if __name__ == '__main__':
start_urls = ['https://www.wikipedia.org/']
crawler = SimpleCrawler(start_urls)
links = crawler.crawl()
# Save the links to an Excel file
crawler.save_to_excel('found_links.xlsx')
print("Found links have been saved to 'found_links.xlsx'")Now, let's create a crawler using Scrapy (read the documentation before starting) for the Amazon.com website.
- Open the Webpage: open the Amazon search results page (e.g., https://www.amazon.com/s?k=phones) in your browser.
- Right-click on any part of the page and click Inspect or press Ctrl+Shift+I (Windows/Linux) or Cmd+Option+I (Mac). This opens the DevTools window, where you can inspect the structure of the page.
- Now, you’ll find the elements you need to extract data from by inspecting the HTML code. Hover over a product name on the Amazon page. In DevTools, the corresponding HTML will be highlighted. Right-click on the product name and click Inspect.
- Look for the tag and class attributes. For example, the product name is in a <span> inside an anchor tag (<a>), and it has a specific class (a-text-normal).
In our case, the selector to extract the product name is: a.a-link-normal.s-line-clamp-2.a-text-normal span::text.
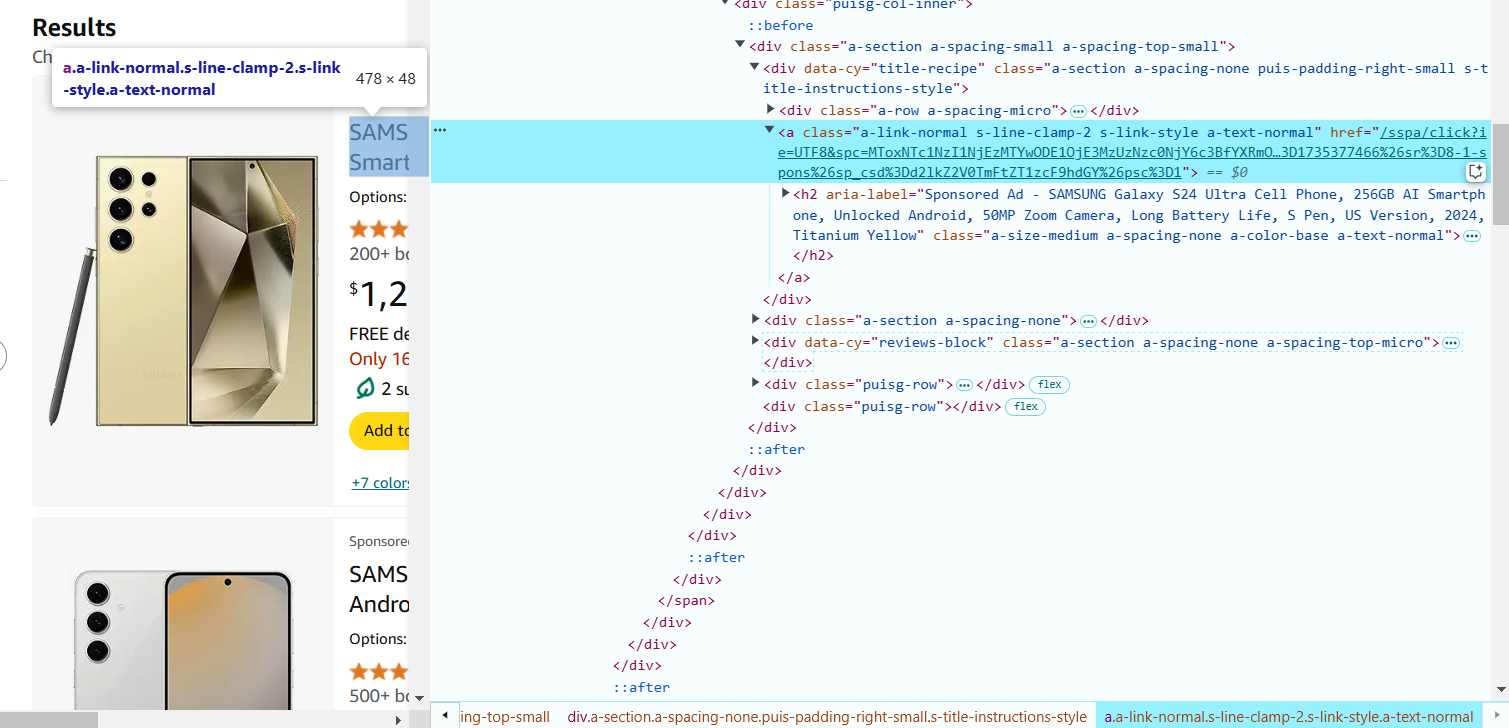
- Hover over the product rating (stars) and right-click to Inspect. The rating is often in a <i> tag with classes like a-icon-star-small. The selector to extract the rating is: i.a-icon-star-small span.a-icon-alt::text.
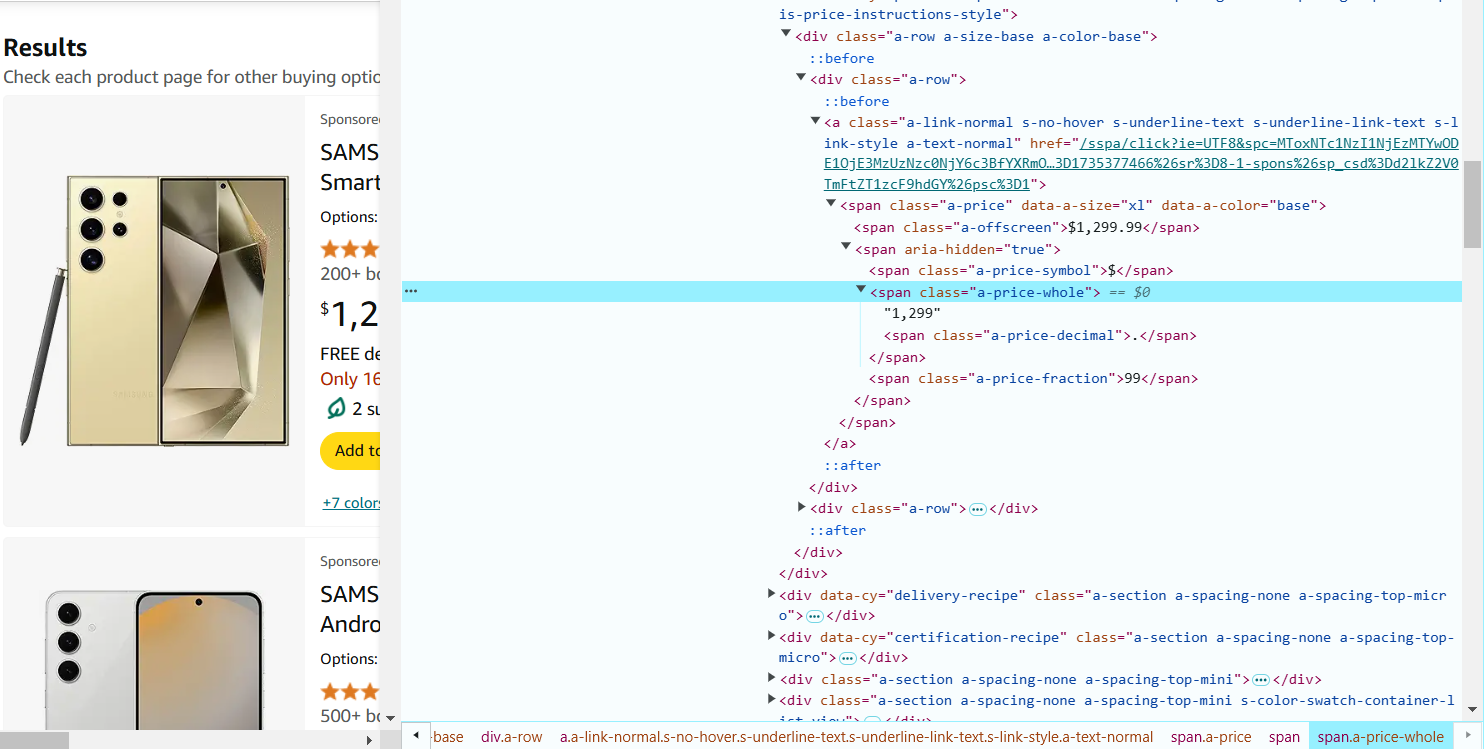
- Hover over the product rating (stars) and right-click to Inspect. The rating is often in a <i> tag with classes like a-icon-star-small. The selector to extract the rating is: i.a-icon-star-small span.a-icon-alt::text.
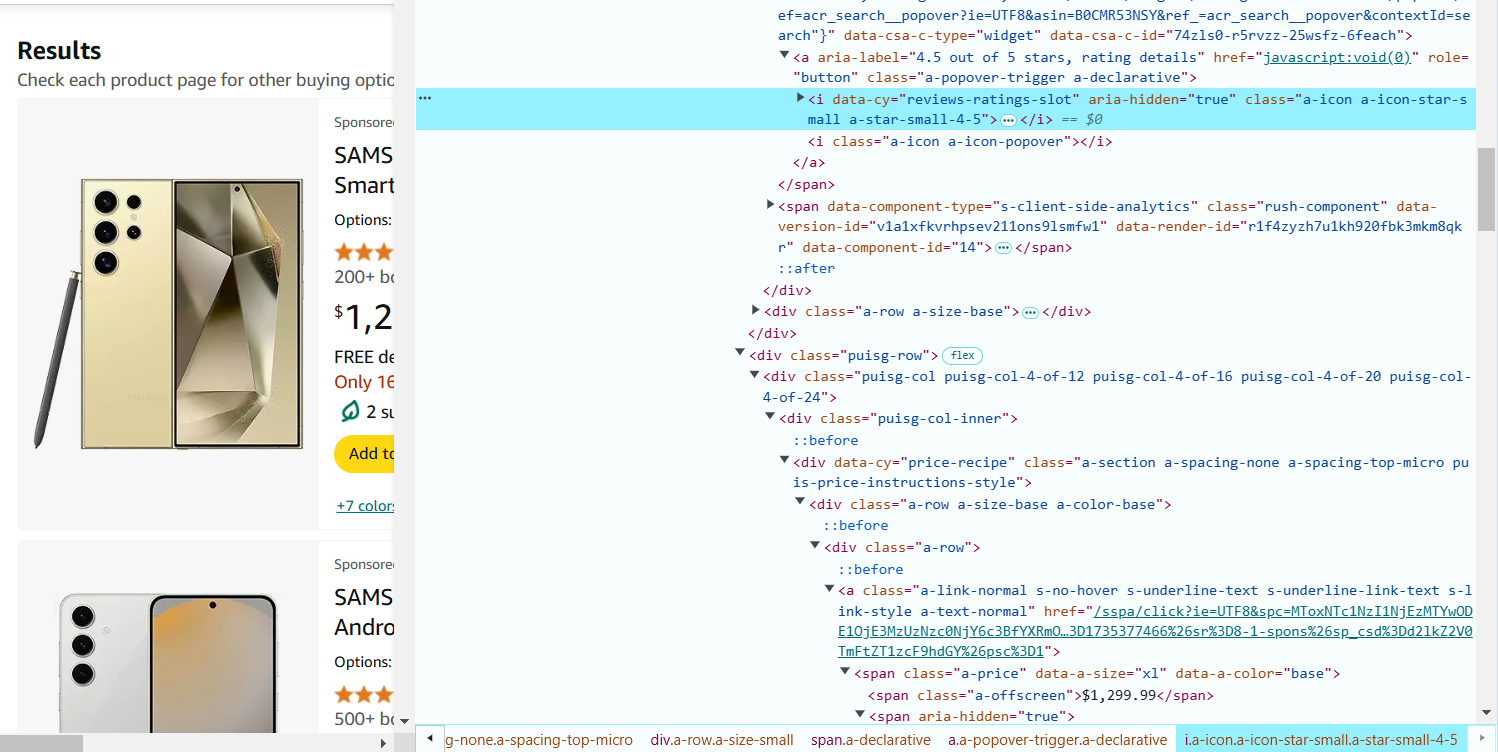
- Hover over the reviews count and right-click to Inspect. The number of reviews is in a <span> tag with the class a-size-base.s-underline-text. The selector to extract the reviews count is: span.a-size-base.s-underline-text::text.
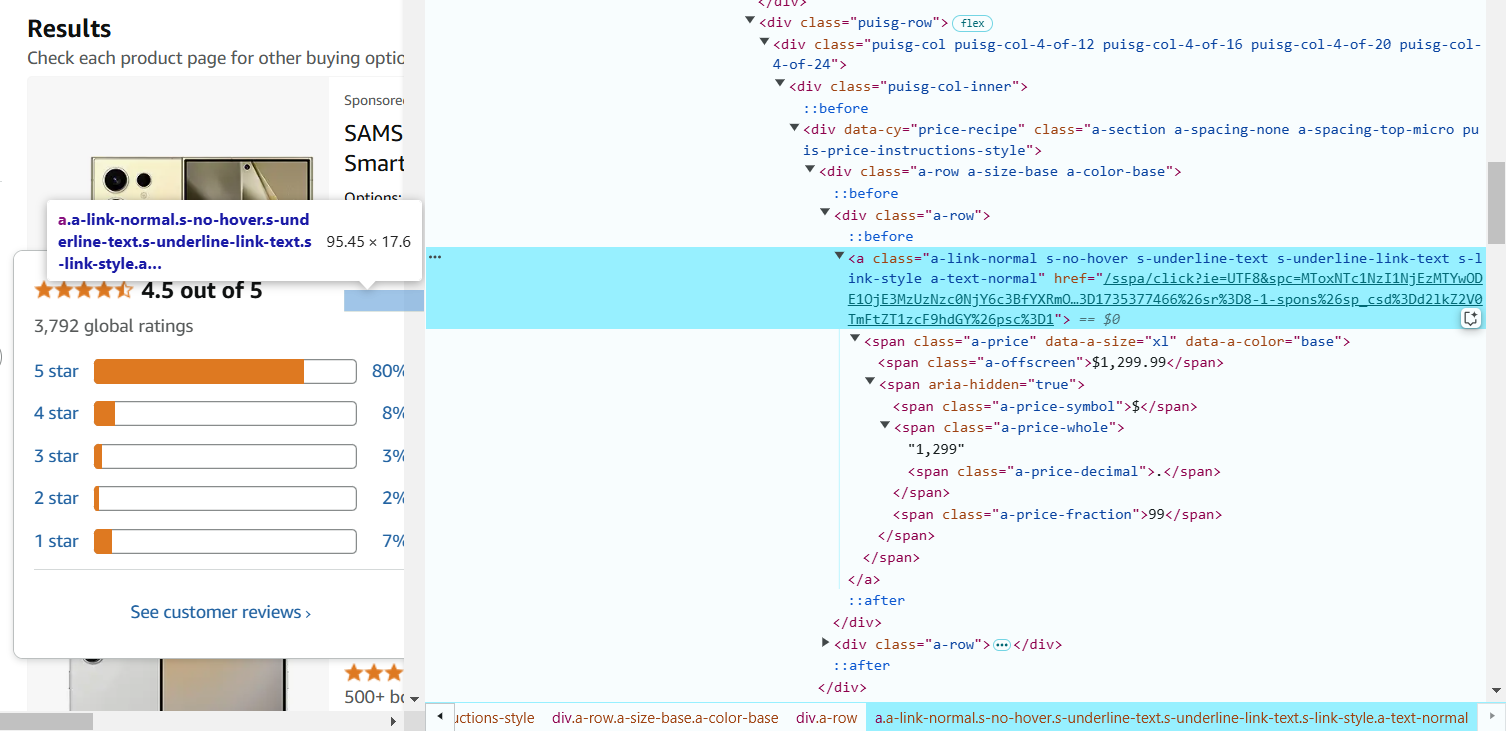
- Hover over the product title (name), and right-click to Inspect. The link is in the anchor (<a>) tag, and the URL is in the href attribute. The selector to extract the product URL is: a.a-link-normal.s-line-clamp-2.s-link-style::attr(href).
Create the Scrapy Spider
Now that you have the necessary CSS selectors, you can use them in the Scrapy spider to extract the data.
import scrapy
class AmazonSpider(scrapy.Spider):
name = "ecommerce"
# Starting URL
start_urls = [
'https://www.amazon.com/s?k=phones'
]
def parse(self, response):
# Add a log for debugging
self.log(f"Parsing page: {response.url}")
# Extract product details
for product in response.css('div.s-main-slot div.s-result-item'):
# Extract product name
name = product.css('a.a-link-normal.s-line-clamp-2.a-text-normal span::text').get()
if name: # Check if we found a product name
self.log(f"Found product: {name}")
# Extract price (may be missing on some products)
price = product.css('span.a-price-whole::text').get()
# Extract rating (may not be present on all products)
rating = product.css('i.a-icon-star-small span.a-icon-alt::text').get()
# Extract number of reviews
reviews = product.css('span.a-size-base.s-underline-text::text').get()
# Extract product URL
product_url = product.css('a.a-link-normal.s-line-clamp-2.s-link-style::attr(href)').get()
yield {
'name': name,
'price': price,
'rating': rating,
'reviews': reviews,
'url': response.urljoin(product_url),
}
# Follow the next page link
next_page = response.css('li.a-last a::attr(href)').get()
if next_page:
self.log(f"Following next page: {next_page}")
yield response.follow(next_page, self.parse)Explanation of the Code:
start_urls: this is the URL to start scraping from. In this case, it’s the Amazon search results for phones.
parse method: this method is used to extract data from the HTML response. It uses CSS selectors to find the relevant elements.
product.css('selector::text'): this extracts text content from elements matching the selector.
product.css('selector::attr(href)'): this extracts the href attribute (URL) from the anchor tag.
Pagination: the spider follows the link to the next page using the next_page link. It ensures that the spider scrapes all product pages.
Run the Spider
After creating the spider, save the file in our Scrapy project’s spiders directory (e.g., amazon_spider.py).
scrapy crawl ecommerce -o products.jsonIn the saved file, the extracted information should look something like this:
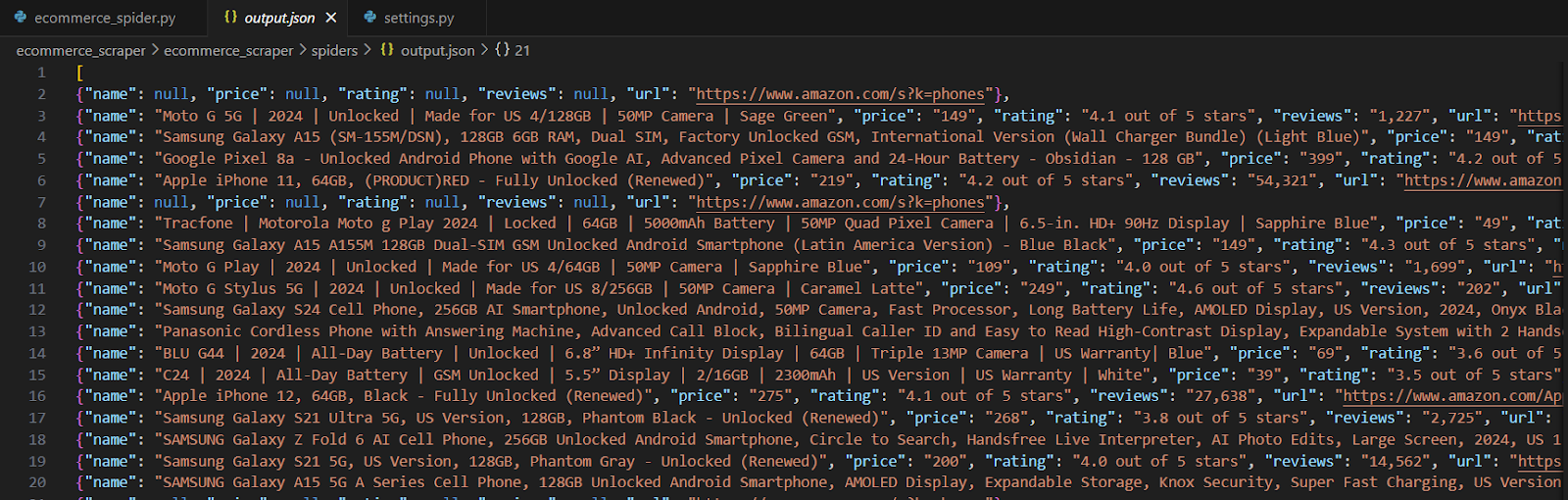
Important Notes:
The real e-commerce websites such as Amazon, eBay, and others have more advanced anti-scraping mechanisms, including CAPTCHAs, rate-limiting, and dynamic content. To scrape real-world sites, you need to account for these factors.
- Always check the robots.txt file of the website and make sure to comply with its scraping policies. Scraping should be done ethically by respecting the website's terms of service and not overloading their servers with excessive requests. Additionally, it's important to ensure that any data you scrape is used in compliance with privacy laws and regulations like GDPR.
- Real sites often use services like reCAPTCHA, DataDome, or Cloudflare to prevent automated scraping. In such cases, you can integrate tools like CapMonster Cloud to bypass CAPTCHA challenges automatically. CapMonster Cloud offers a simple API to solve various CAPTCHAs, including Google reCAPTCHA, Geetest, and others.
- Websites can track scraping activities by analyzing browser fingerprints, such as the User-Agent, Accept-Language, and other headers. To avoid detection, you should rotate these fingerprints (e.g., by using a service like BrowserStack or ProxyCrawl) or through custom headers and dynamic proxy usage.
- In addition, using IP rotation and proxy services (e.g., ScraperAPI or ProxyMesh) can help avoid being blocked for making too many requests from the same IP address.
Here’s an example of dynamic web crawling using Playwright. This script grabs the latest news from Hacker News (https://news.ycombinator.com/), a popular tech news site that loads content dynamically with JavaScript.
Why Use This?
This approach is perfect for websites that don’t show all their content immediately (they load it with JavaScript). Playwright helps you act like a real user, letting you wait for the content to load before grabbing the data. It’s a great tool for modern dynamic websites!
Install Playwright
If you haven’t already, run this in your terminal:
pip install playwright
playwright installTo download only Chromium:
pip install playwright
playwright install chromium- Example Code:
from playwright.sync_api import sync_playwright
def dynamic_crawler():
with sync_playwright() as p:
# Launch a browser
browser = p.chromium.launch(headless=True)
page = browser.new_page()
# Go to the website
url = "https://news.ycombinator.com/"
page.goto(url)
# Wait for the news items to load
page.wait_for_selector(".athing")
# Extract data
articles = []
for item in page.query_selector_all(".athing"):
title = item.query_selector(".titleline a").inner_text()
link = item.query_selector(".titleline a").get_attribute("href")
rank = item.query_selector(".rank").inner_text() if item.query_selector(".rank") else None
articles.append({"rank": rank, "title": title, "link": link})
browser.close()
# Print the results
for article in articles:
print(article)
# Run the crawler
dynamic_crawler()What the Code Does
- Start the Browser:
- chromium.launch() starts a lightweight browser in the background (headless=True means no window will pop up).
- Visit the Website:
- page.goto(url) navigates to Hacker News.
- Wait for the Content:
- page.wait_for_selector(".athing") waits for the news articles to load.
- Grab the Data:
- It looks for all news items using the CSS class .athing.
- For each item, it gets:
- The rank (e.g., "1.")
- The title of the news
- The link to the full article.
- Close the Browser:
- The browser is closed after collecting the data.
- Show the Results:
- It prints each article as a small dictionary with keys like rank, title, and link.
Example Output
After running the script, you’ll see something like this in your terminal:
{'rank': '1.', 'title': 'A great open-source project', 'link': 'https://example.com'}
{'rank': '2.', 'title': 'How to learn Python', 'link': 'https://news.ycombinator.com/item?id=123456'}
{'rank': '3.', 'title': 'Show HN: My new tool', 'link': 'https://example.com/tool'}
Web crawling with Python is an amazing way to gather data from the web and uncover valuable insights. By using tools like BeautifulSoup, Scrapy, and Playwright, you can handle everything from simple static sites to more complex dynamic ones. The examples we’ve covered show how you can extract data and deal with challenges like JavaScript content and website restrictions.
If you need to bypass blocks, techniques like rotating proxies or solving CAPTCHAs can help, but make sure to use them ethically.
With Python and the right tools, web crawling becomes an exciting and powerful skill. Whether you’re just starting or have some experience, you can achieve great results and make your projects shine. Good luck, and enjoy your crawling journey!