How to Solve Amazon (AWS WAF) CAPTCHA and Challenge When Web Scraping
AWS WAF (a service from Amazon) provides two primary types of protection for web resources against unwanted automated actions:
- CAPTCHA – requires the user to solve tasks such as entering text in a specific field, moving a slider, selecting certain objects in an image, or dragging elements to a designated location. Additionally, audio CAPTCHAs may be offered, where the user must listen to and recognize words spoken against background noise and enter them in the appropriate field.
- Challenge – Here, the user does not need to solve anything to interact with the site – the check occurs in the background by analyzing session parameters and request behavior (such as request frequency, use of JavaScript, mouse behavior, and the presence or absence of cookies). If the check is successful, the user can continue using the site. If not, the request may be blocked, or a CAPTCHA may be displayed for additional verification. If the system detects signs of automation, it may increase the level of verification to ensure security and protect the site from unauthorized access.
Amazon's security system is carefully designed and provides a high level of security; it is constantly updated to make it more difficult for bots to access websites. However, for the purposes of website testing, safe parsing, and debugging, it can be solved using the cloud service CapMonster Cloud.
Finding CAPTCHA Data
To solve this type of CAPTCHA, you need to visit the target site with the CAPTCHA, open Developer Tools, and retrieve the necessary CAPTCHA data – such as websiteKey, context, iv, and challengeScript.
Here is a more detailed guide:
- Load the required page, open Developer Tools, navigate to the Network tab, and find the document line with a 405 response.
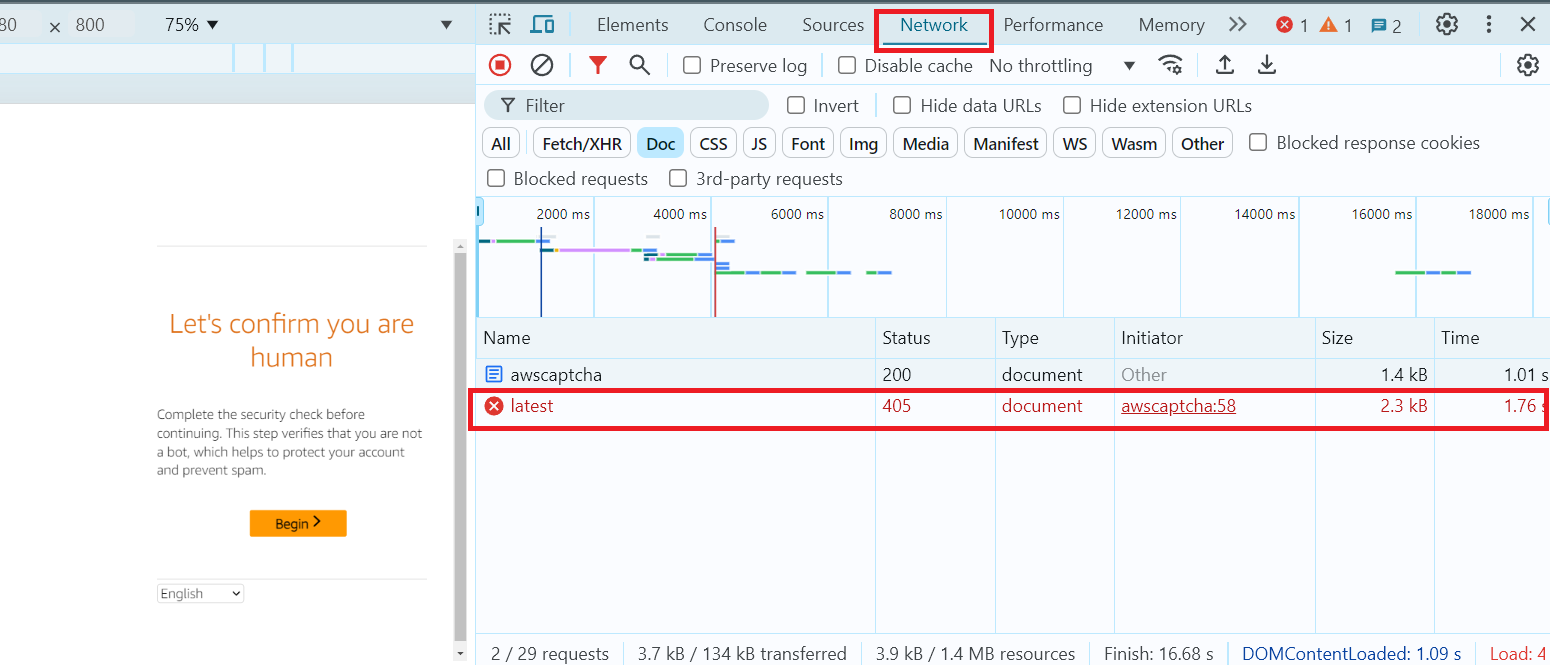
2. Select this document and go to the Response tab:
3. Find the window.gokuProps object, where you will find all the necessary parameters.
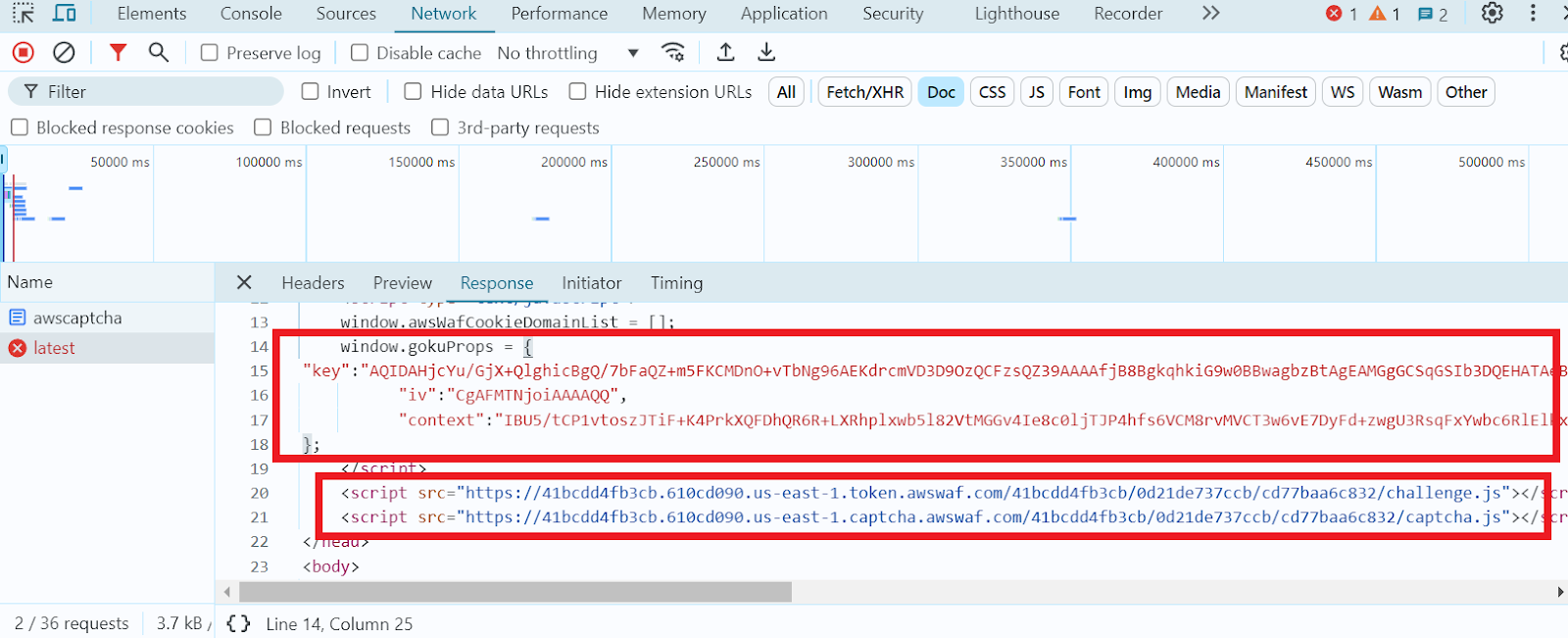
Table with Required Parameters and Their Values:
Task is performed using CapMonster Cloud proxy servers.
| Parameter | Type | Required | Value |
|---|---|---|---|
type | String | Yes | AmazonTaskProxyless |
websiteURL | String | Yes | The main page URL where the CAPTCHA is being solved. |
challengeScript | String | Yes | Link to challenge.js. |
captchaScript | String | Yes | Link to captcha.js. |
websiteKey | String | Yes | A string that can be obtained from the HTML page with the CAPTCHA or by executing window.gokuProps.key in JavaScript. |
context | String | Yes | A string that can be obtained from the HTML page with the CAPTCHA or by executing window.gokuProps.context in JavaScript. |
iv | String | Yes | A string that can be obtained from the HTML page with the CAPTCHA or by executing window.gokuProps.iv in JavaScript. |
cookieSolution | Boolean | No | Default is false. If you need the "aws-waf-token" cookies, set it to true. Otherwise, the response will contain "captcha_voucher" and "existing_token". |
You can also automatically obtain the parameters for an AWS WAF CAPTCHA by using the following JavaScript code:
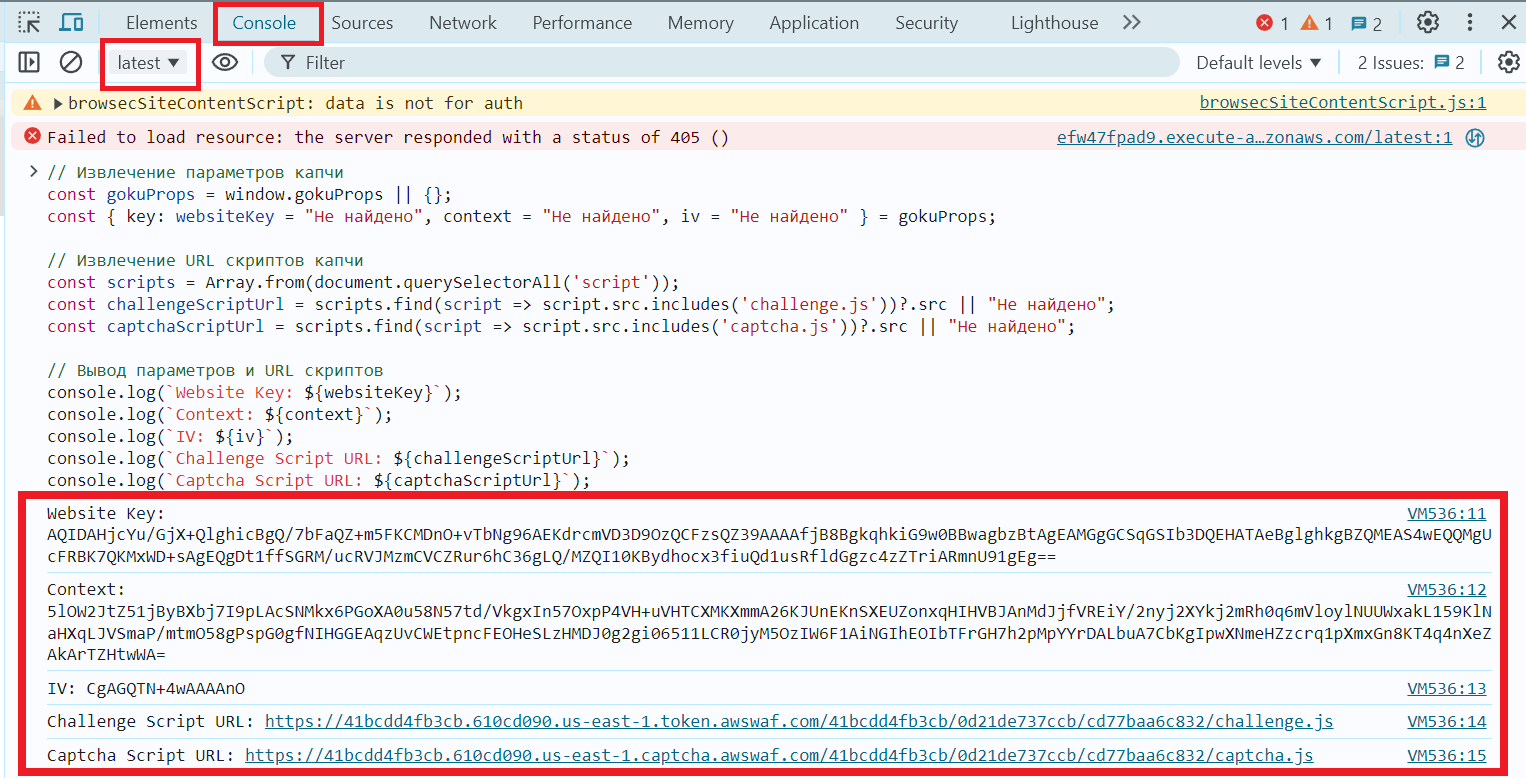
// Extract CAPTCHA parameters
var gokuProps = window.gokuProps;
var websiteKey = gokuProps ? gokuProps.key : "Not found";
var context = gokuProps ? gokuProps.context : "Not found";
var iv = gokuProps ? gokuProps.iv : "Not found";
// Extract CAPTCHA script URLs
var scripts = Array.from(document.querySelectorAll('script'));
var challengeScriptUrl = scripts.find(script => script.src.includes('challenge.js'))?.src || "Not found";
var captchaScriptUrl = scripts.find(script => script.src.includes('captcha.js'))?.src || "Not found";
// Output parameters and script URLs
console.log("Website Key: " + websiteKey);
console.log("Context: " + context);
console.log("IV: " + iv);
console.log("Challenge Script URL: " + challengeScriptUrl);
console.log("Captcha Script URL: " + captchaScriptUrl);
Once you have all the CAPTCHA parameters, you can create a task to submit to the CapMonster Cloud server.
Example Request:
Use the method: https://api.capmonster.cloud/createTask
Request format: JSON POST
{
"clientKey": "API_KEY",
"task": {
"type": "AmazonTaskProxyless",
"websiteURL": "https://efw47fpad9.execute-api.us-east-1.amazonaws.com/latest",
"challengeScript": "https://41bcdd4fb3cb.610cd090.us-east-1.token.awswaf.com/41bcdd4fb3cb/0d21de737ccb/cd77baa6c832/challenge.js",
"captchaScript": "https://41bcdd4fb3cb.610cd090.us-east-1.captcha.awswaf.com/41bcdd4fb3cb/0d21de737ccb/cd77baa6c832/captcha.js",
"websiteKey": "AQIDA...wZwdADFLWk7XOA==",
"context": "qoJYgnKsc...aormh/dYYK+Y=",
"iv": "CgAAXFFFFSAAABVk",
"cookieSolution": true
}
}Example Response:
{
"errorId": 0,
"taskId": 407533072
}Retrieving the Result:
Use the getTaskResult method to get the solution to the AmazonTask.
https://api.capmonster.cloud/getTaskResult
Example Response:
{
"errorId": 0,
"status": "ready",
"solution": {
"cookies": {
"aws-waf-token": "10115f5b-ebd8-45c7-851e-cfd4f6a82e3e:EAoAua1QezAhAAAA:dp7sp2rXIRcnJcmpWOC1vIu+yq/A3EbR6b6K7c67P49usNF1f1bt/Af5pNcZ7TKZlW+jIZ7QfNs8zjjqiu8C9XQq50Pmv2DxUlyFtfPZkGwk0d27Ocznk18/IOOa49Rydx+/XkGA7xoGLNaUelzNX34PlyXjoOtL0rzYBxMAQy0D1tn+Q5u97kJBjs5Mytqu9tXPIPCTSn4dfXv5llSkv9pxBEnnhwz6HEdmdJMdfur+YRW1MgCX7i3L2Y0/CNL8kd8CEhTMzwyoXekrzBM="
},
"userAgent": "userAgentPlaceholder"
}
}During web scraping, various obstacles may arise, such as script interruption due to an Amazon CAPTCHA appearing on the target site. To bypass this obstacle, you can add additional code to your scraper for automatic CAPTCHA solving. This code will wait for the CAPTCHA frame, extract all necessary parameters, and send the solution to the CapMonster Cloud server.
Here is how you can implement it: Let's assume there is a script for scraping a weather website using Selenium in Python:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import os
import requests
import time
# API_KEY for CapMonster Cloud
API_KEY = os.getenv('CAPMONSTER_API_KEY')
CREATE_TASK_URL = 'https://api.capmonster.cloud/createTask'
GET_TASK_RESULT_URL = 'https://api.capmonster.cloud/getTaskResult'
def create_task(website_key, context, iv, challenge_script_url, captcha_script_url):
print("Creating task...")
task_data = {
"clientKey": API_KEY,
"task": {
"type": "AmazonTaskProxyless",
"websiteURL": 'https://example.com', # Replace with the correct value
"challengeScript": challenge_script_url,
"captchaScript": captcha_script_url,
"websiteKey": website_key,
"context": context,
"iv": iv,
"cookieSolution": False # Set to True if "aws-waf-token" cookies are needed
}
}
response = requests.post(CREATE_TASK_URL, json=task_data)
response_json = response.json()
if response_json['errorId'] == 0:
print(f"Task successfully created. Task ID: {response_json['taskId']}")
return response_json['taskId']
else:
print(f"Error creating task: {response_json['errorCode']}")
return None
def get_task_result(task_id):
print("Getting task result...")
result_data = {"clientKey": API_KEY, "taskId": task_id}
while True:
response = requests.post(GET_TASK_RESULT_URL, json=result_data)
response_json = response.json()
if response_json['status'] == 'ready':
print(f"Task result ready: {response_json}")
return response_json
elif response_json['status'] == 'processing':
print("Task still processing...")
time.sleep(5)
else:
print(f"Error retrieving task result: {response_json['errorCode']}")
return response_json
# Launch the browser
driver = webdriver.Chrome()
try:
# Open the main page
print("Opening page...")
driver.get('https://example.com')
# Enter city for search
search_box = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "header-location-search"))
)
search_box.send_keys("Moscow") # Replace with the desired city
search_box.send_keys(Keys.RETURN)
# Wait for CAPTCHA iframe to appear
print("Waiting for iframe...")
iframe = WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CSS_SELECTOR, 'iframe[src*="execute-api"]'))
)
driver.switch_to.frame(iframe)
print("Waiting for CAPTCHA, extracting parameters...")
WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#captcha-container'))
)
goku_props = driver.execute_script("return window.gokuProps;")
website_key = goku_props["key"]
context = goku_props["context"]
iv = goku_props["iv"]
challenge_script_url, captcha_script_url = [
driver.execute_script(f"return document.querySelector('script[src*=\"{x}\"]').src;")
for x in ("challenge.js", "captcha.js")
]
# Create and solve CAPTCHA task
task_id = create_task(website_key, context, iv, challenge_script_url, captcha_script_url)
if task_id:
result = get_task_result(task_id)
# Use the result to submit the CAPTCHA solution on the page, if needed
# Continue processing search results after solving CAPTCHA
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, 'div.locations-list')) # Replace with the correct value
)
first_result = driver.find_element(By.CSS_SELECTOR, 'div.locations-list a') # Replace with the correct value
first_result.click()
# Additional actions...
finally:
print("Closing browser...")
driver.quit()- Additional Library Imports:
requests for sending HTTP requests to interact with the CapMonster Cloud API and time for pausing code execution. - API Key and URL Variables:
Variables are added to store the API key for authentication and the URLs for creating tasks and retrieving results from CapMonster Cloud. - Task Creation Function:
A function that takes several parameters necessary for creating a CAPTCHA-solving task. It sends a POST request to the CapMonster Cloud server with the task data. If the task is successfully created, the function returns the taskId. - Task Result Function:
A function that sends a POST request to check the task status. If the task status is 'ready,' the function returns the result; otherwise, it waits and checks the status again. - Browser Initialization and Target Page Opening:
Wait for the search field to appear, enter the city name, and wait for the CAPTCHA iframe to appear. - CAPTCHA Parameter Extraction:
The updated code extracts the website_key, context, and iv values from the iframe's scripts and uses them to create a task on the CapMonster Cloud server. - CAPTCHA Solving Workflow:
The code now includes the creation of a task and periodic checks to determine whether the CAPTCHA has been solved. After the CAPTCHA is solved, additional actions are performed.
The code provided above is an example demonstrating the general logic of performing actions. All actions and element names depend on the specific website and its structure. You will need to study the website's HTML code and familiarize yourself with the documentation of the tools you plan to use for web scraping. Every website is unique, and successful scraping may require adapting the code and approaches depending on the characteristics of the target resource. Additionally, working with Amazon CAPTCHA has its nuances that need to be considered.
Here are some general useful tips for successful web scraping and solving the Amazon CAPTCHA (AWS WAF):
- Asynchronous Programming: In our simple example of scraping and CAPTCHA solving, the asynchronous method is not used. However, if you are working with a large amount of data or websites with slow response times, it's better to use asynchronous programming for parallel task execution and speeding up the process.
- Headless Mode: Run the browser in headless mode to speed up the work and save resources. Without displaying the browser's graphical interface, the process can be more efficient.
- Graphical Browser: If the site requires complex interactions that are impossible in headless mode, use a graphical browser. This will help you handle interface elements, better test your code, and avoid some errors and blocks from websites that might restrict access upon detecting headless browsers.
- Changing IP Address and User-Agent: To avoid blocks and restrictions from the site, regularly change the IP address and User-Agent. Use quality proxy servers and change the User-Agent in requests so the site does not suspect automated behavior.
- Handling Dynamic CAPTCHA: Amazon uses CAPTCHAs that can change depending on time or activity and constantly updates its anti-bot protection methods. Ensure that your script adapts to these changes and handles them correctly. Keep up with updates and news from CAPTCHA solving services.
- Reducing Request Frequency: Avoid making requests too frequently to avoid drawing the attention of Amazon's anti-bot systems, or distribute them across different IP addresses.
Useful Links:
Solving Amazon CAPTCHA (AWS WAF) can pose significant challenges when collecting data. However, understanding the basic principles of how this system works and using the right tools can help effectively manage such tasks.
We have covered key points, including the description of this type of CAPTCHA and its solving using CapMonster Cloud. The most critical stages are accurately extracting necessary CAPTCHA parameters, creating and sending the task to the server, and obtaining and using the CAPTCHA solution. We also reviewed a Python code example that demonstrates how to integrate CAPTCHA-solving into the web scraping process. Success in this area depends not only on technical skills but also on the ability to quickly adapt to changes and innovations in anti-bot protection methods.
Note: We'd like to remind you that the product is used for automating testing on your own websites and on websites to which you have legal access.