If you have landed on this page, chances are you are already familiar with the concept of web scraping in Java and are looking to dive deeper into the details. Great, you’re on the right track! In this guide, we will explain the basics of web scraping in Java in a simple and accessible way, and we will also demonstrate how to extract data from a real website, including both static and dynamic elements. Everything you need for a quick and convenient start in gathering the information you need is right here. So, let’s get started!
Web scraping is like sending a digital assistant to gather information for you from websites. Imagine you’re browsing the internet, copying text, or collecting images – but instead of doing it manually, a program does it for you, much faster and more efficiently. With web scraping, you can extract useful data, such as prices, reviews, or contact details, and save it in a format that suits your needs, like a spreadsheet or database.
It’s a powerful tool used in areas like market research, competitive analysis, and data aggregation. Whether you’re a beginner or an experienced developer, web scraping can simplify the way you gather and organize information from the web.
Java is an excellent choice for web scraping, and here’s why:
Reliability and Performance: Java is known for its robust performance and ability to handle complex tasks. Whether you’re scraping small websites or large-scale applications, Java provides the stability needed for consistent results.
Comprehensive Libraries: with libraries like Jsoup for parsing HTML and Selenium for interacting with dynamic web pages, Java has all the tools you need for web scraping.
Cross-Platform Compatibility: write your code once and run it anywhere. Java’s platform independence means you can develop your scraping scripts on one operating system and deploy them on another with ease.
Threading and Scalability: Java’s multithreading capabilities make it possible to scrape multiple pages simultaneously, saving time and improving efficiency.
Community and Support: Java’s widespread use means a vast community of developers is available to provide support, share solutions, and offer advice.
By choosing Java, you’re opting for a language that is versatile, powerful, and well-supported – perfect for tackling web scraping projects of any scale!
For successful web scraping in Java, there are several powerful tools and libraries that can help you efficiently collect data from web pages. Let’s take a look at some popular options:
Jsoup
Jsoup is one of the most popular libraries for parsing HTML in Java. It provides a simple and intuitive API for extracting data from HTML documents. If you need to quickly retrieve information from a webpage and work with the DOM (Document Object Model), Jsoup is an ideal choice.
Advantages:
- Easy to use.
- Supports parsing HTML and working with CSS selectors.
- Allows cleaning HTML from junk and unnecessary tags.
- Simple API for getting elements and their attributes.
Apache HttpClient
Apache HttpClient is a library that helps you work with HTTP requests, offering features like handling cookies, headers, and authentication. If you simply need to send requests and retrieve data from a site (without handling JavaScript), this is a great option.
Advantages:
- Flexibility in configuring HTTP requests.
- Ability to work with various HTTP methods (GET, POST, PUT, etc.).
- Integrates well with other libraries for data processing.
HtmlUnit
HtmlUnit is a "headless" browser that allows interaction with web pages without needing to launch a real browser. It is ideal for testing and scraping sites where visual rendering is not required.
Advantages:
- Lightweight (no need for a graphical interface).
- Suitable for scraping dynamic pages (supports JavaScript).
- Fast performance.
Selenium WebDriver
Selenium is a popular tool for automating browsers. It is perfect for scraping dynamic pages where data is loaded using JavaScript. With Selenium, you can control a browser, simulate user actions (clicks, typing), and extract the needed information.
Advantages:
- Suitable for dynamic websites (where data is loaded through JavaScript).
- Supports multiple browsers (Chrome, Firefox, Safari, and others).
- Ability to simulate real user behavior.
These libraries and tools provide powerful functionality for working with web pages and collecting data. Depending on your tasks, you might choose one or more of them. For example, for simple HTML parsing, Jsoup is a great choice, while for dynamic pages, Selenium or HtmlUnit would be more suitable. Your choice depends on the complexity of your project and how data is loaded on the target websites.
Here’s an overview of the best editors and IDEs for web scraping in Java, along with the pros and cons of each:
- IntelliJ IDEA
IntelliJ IDEA is one of the most popular and powerful IDEs for Java development. It offers numerous features that can be useful for web scraping.
Pros:
- IntelliJ understands code context, providing accurate suggestions and fixes.
- Supports all popular build systems (Maven, Gradle) and frameworks.
- A powerful and user-friendly debugging tool.
- Offers plugins for working with databases, Docker, testing, and more.
- Easy-to-use and intuitive interface.
Cons:
- Can be demanding on system resources, especially on older or less powerful computers.
- While there is a free Community version, some features are only available in the paid Ultimate version.
Nuances:
Suitable for developers working on complex projects or in teams, as it provides powerful refactoring and collaboration tools.
- Eclipse
Eclipse is one of the oldest and most well-known IDEs for Java. It offers extensive features for Java development and other languages.
Pros:
- Eclipse is a free IDE with the ability to modify it.
- A vast number of plugins and extensions.
- Suitable for developing large applications.
Cons:
- Eclipse's interface is not as user-friendly compared to IntelliJ IDEA.
- Some operations may be slow, especially when using a lot of plugins or large projects.
Nuances:
Eclipse is more suited to experienced developers who need more customization and extensions. Newcomers may find the interface confusing.
- JDeveloper
JDeveloper is an IDE from Oracle, designed for Java EE (Enterprise Edition) development.
Pros:
- Fully integrated with Oracle products, making it an ideal choice for Java EE development.
- Includes tools for working with databases, web services, and many other technologies.
Cons:
- Compared to Eclipse or IntelliJ IDEA, JDeveloper has a smaller user community.
- It may not be as convenient for developers working outside of the Java EE ecosystem.
Nuances:
Best suited for large-scale Java EE projects, especially if you are working with Oracle products.
- Apache NetBeans
Apache NetBeans is an improved version of NetBeans, supported by the Apache Software Foundation.
Pros:
- Unlike the older version, this version is actively supported and developed.
- Completely free and open-source.
Cons:
- Not as popular as IntelliJ IDEA or Eclipse: It has fewer resources and documentation compared to other IDEs.
- May be slow: Can sometimes be slower than other tools.
Nuances:
A great choice for those looking for a free, open-source IDE for Java development, but who don’t need maximum performance or a large number of plugins.
- Visual Studio Code (VS Code)
VS Code is a lightweight editor with numerous plugins, making it suitable for a wide variety of programming languages, including Java.
Pros:
- Runs fast and doesn’t consume many resources.
- Java plugins are available for features like autocompletion, debugging, and more.
- User-friendly interface: very customizable and easy to use.
Cons:
- Not a full-fledged IDE: compared to IntelliJ IDEA or Eclipse, VS Code doesn’t offer all the features of an IDE, like powerful refactoring or large project management.
- May not have all the features needed for large-scale Java projects.
Nuances:
Perfect for smaller or medium-sized projects and quick prototyping. Great for developers who value simplicity and speed.
Now that we have familiarized ourselves with the main and most popular tools for web scraping in Java, let’s choose the one that best suits our needs and proceed with preparing for web scraping. For our example, we will choose IntelliJ IDEA and Jsoup.
1. Install IntelliJ IDEA
- Visit the official IntelliJ IDEA website.
- Download and install the Community Edition (free) or the Ultimate Edition (paid).
2. Create a New Project
- Open IntelliJ IDEA and select New Project.
- Choose Java as the project type.
- Make sure Project SDK is set to an appropriate version of Java (Java 8 or higher).
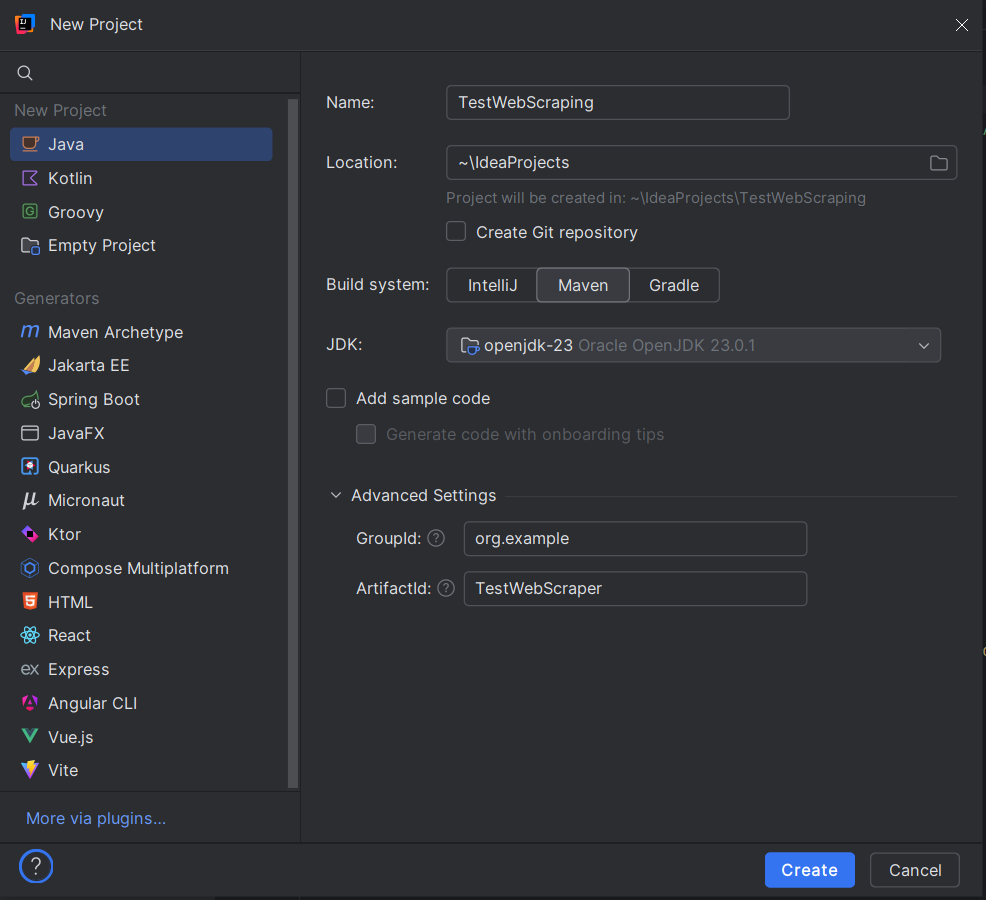
3. Configure Project Name and Location
- Enter a name for your project (e.g., TestWebScraping).
- Choose the location for your project files.
- When creating a project in IntelliJ IDEA, choose Maven. In the dialog that appears: GroupId: set a unique identifier for your project, such as org.example. ArtifactId: this is the name of your project, for example, TestWebScraper.
- Click Create
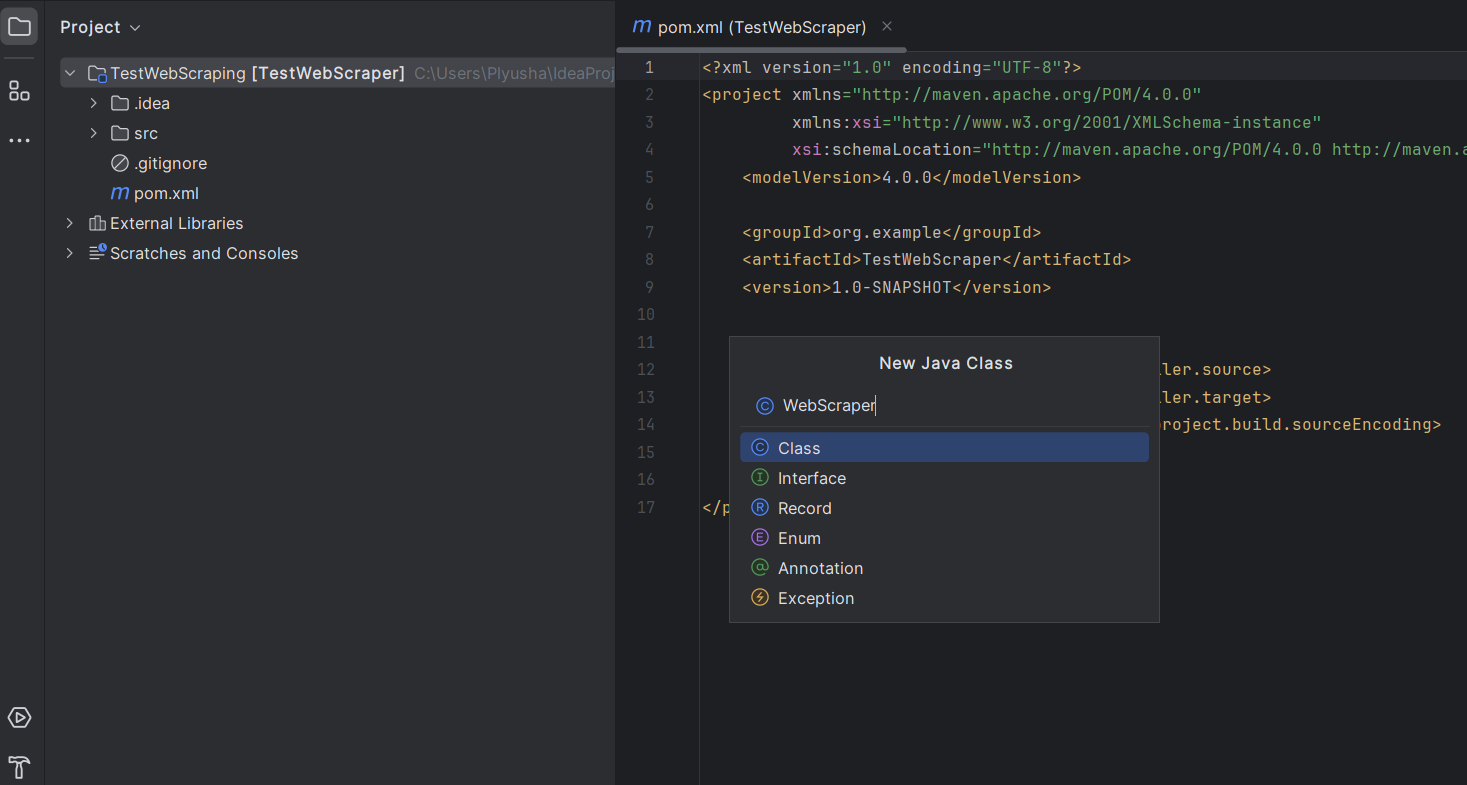
4. Set Up Project Structure
Once the project is created, IntelliJ IDEA will automatically open the project structure.
- Create a Java class in this package: right-click on your new package and select New -> Java Class.
- Name it WebScraper or anything you prefer.
5. Add Dependencies
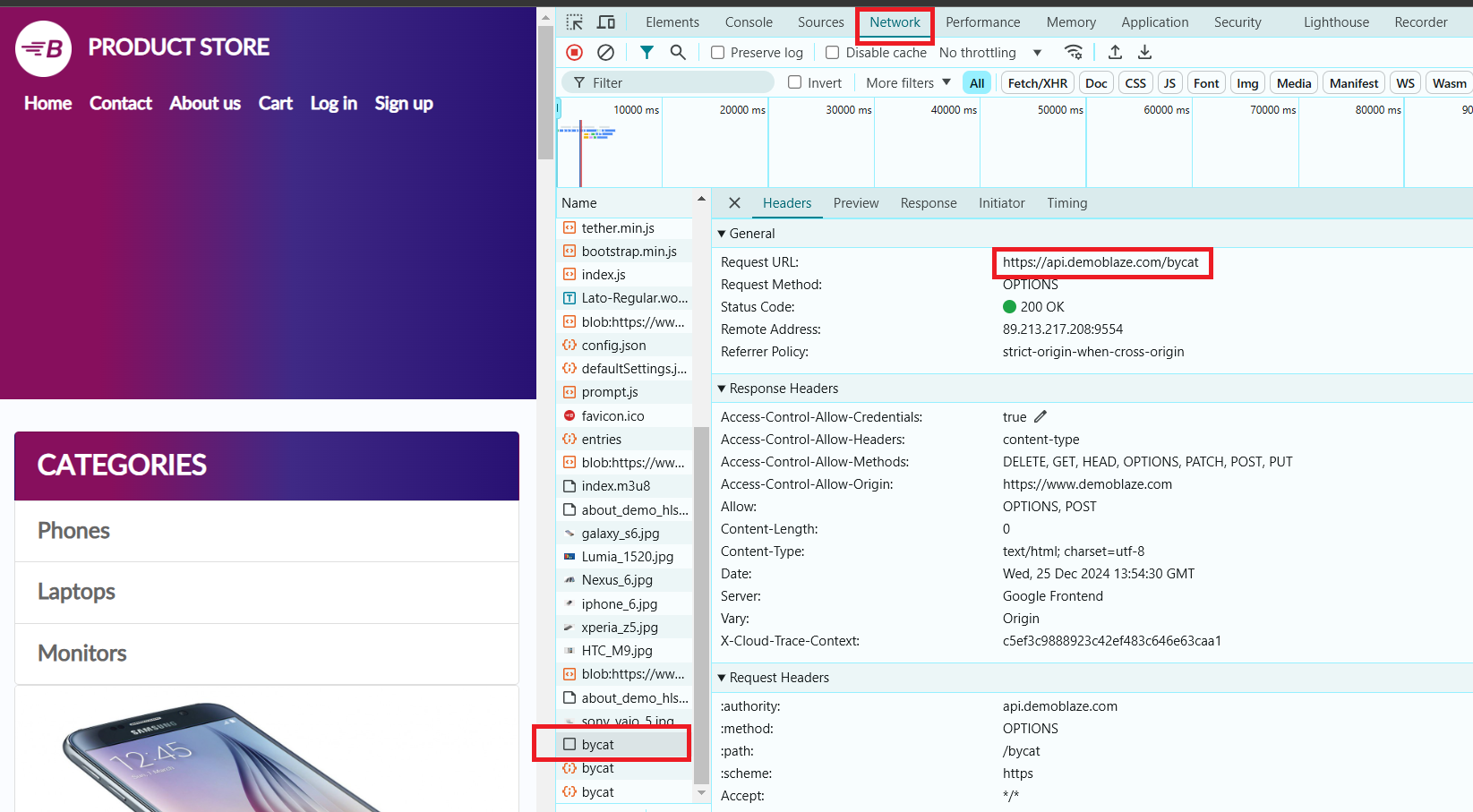
In our example, we will use the website https://www.demoblaze.com/#. Since the site renders content using JavaScript, Jsoup won't be able to directly retrieve the data. However, the site uses an API that can be called directly to obtain information about the products.
When analyzing the Demoblaze website, it was found that product data is loaded through dynamic requests, not in static HTML. The API https://api.demoblaze.com/bycat is an internal API used to retrieve product data on the site.
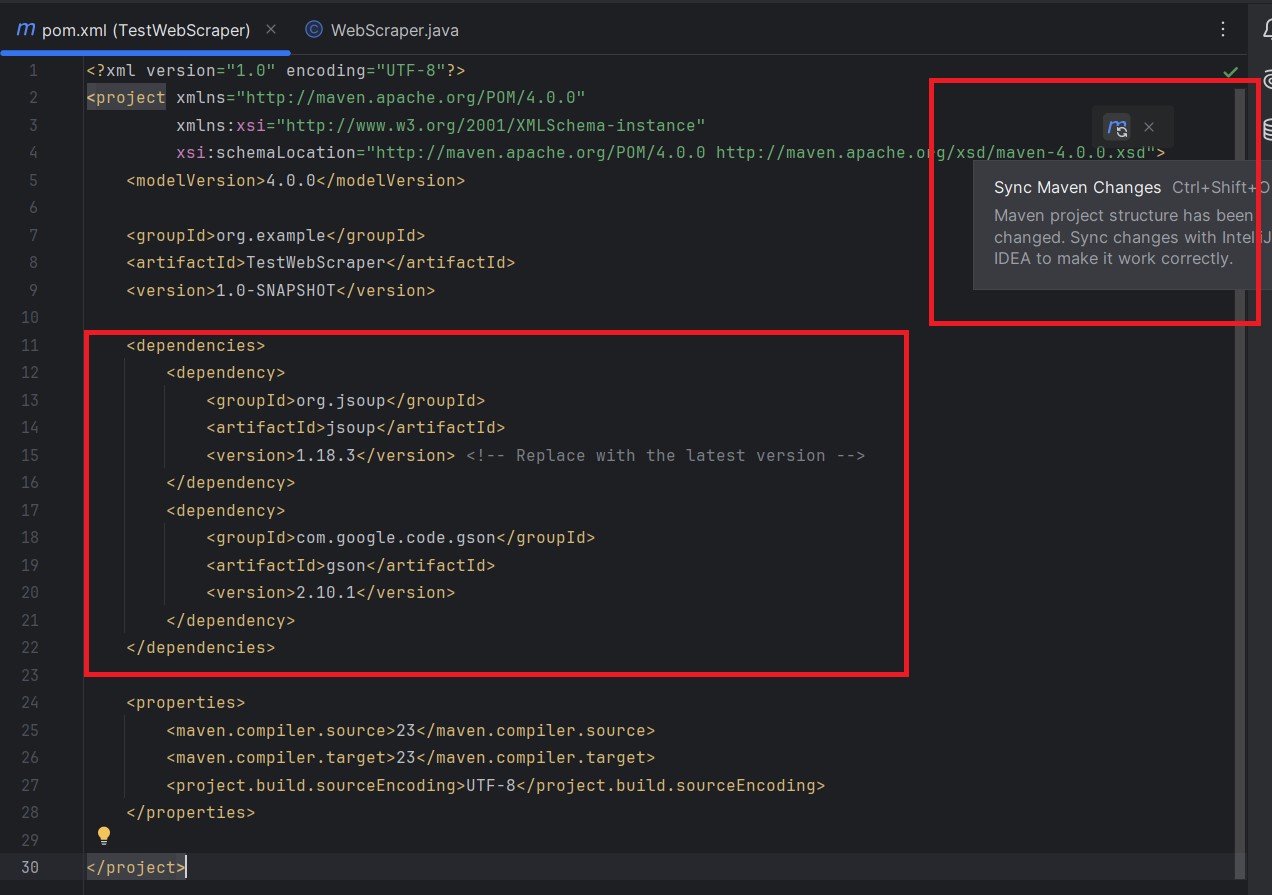
Then, you’ll need to add the Jsoup and Gson libraries to your project.
In the pom.xml file, add the following Jsoup and Gson dependencies inside the <dependencies> section:
<dependencies>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.18.3</version> <!-- Replace with the latest version -->
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.10.1</version>
</dependency>
</dependencies>
Don't forget to sync the Maven changes:
Let's try to extract the name and price of each product from the selected page. But first, let's inspect the elements on the page.
- Open DevTools (by pressing the F12 key in most browsers).
- Select the "Phones" category. In the "Network" tab, an API request will appear, and we will use it to extract the necessary data.
This API accepts a POST request with a JSON body specifying the product category, e.g., and responds with a JSON object containing an array of items in the "Items" key. Each item has properties like "title" and "price".
Now, let's dive into writing the code for our web scraper!
1. Before getting started, familiarize yourself with the documentation for Jsoup and Gson.
2. Open the previously created WebScraper.java class and import all the necessary dependencies:
import com.google.gson.Gson;
import com.google.gson.JsonArray;
import com.google.gson.JsonObject;
import java.io.OutputStream;
import java.net.HttpURLConnection;
import java.net.URI;
import java.net.URL;
import java.nio.charset.StandardCharsets;
import java.util.Scanner;3. Main Method:
public class WebScraper {
public static void main(String[] args) {
try {
// API URL
String apiUrl = "https://api.demoblaze.com/bycat";
// Request parameter for product category
String category = "phone"; // Can be changed to "laptop", "monitor", etc.
// Fetch response from API
String jsonResponse = fetchApiResponse(apiUrl, category);
// Parse the JSON response
Gson gson = new Gson();
JsonObject responseObject = gson.fromJson(jsonResponse, JsonObject.class);
JsonArray items = responseObject.getAsJsonArray("Items");
// Output product information
for (int i = 0; i < items.size(); i++) {
JsonObject item = items.get(i).getAsJsonObject();
String title = item.get("title").getAsString();
String price = item.get("price").getAsString();
System.out.println("Product: " + title);
System.out.println("Price: $" + price);
System.out.println("-----------------------");
}
} catch (Exception e) {
System.err.println("An error occurred: " + e.getMessage());
}
}
}
API URL: the variable apiUrl holds the endpoint for the API, which returns product details based on the specified category.
Category: the variable category is used to specify the product category to filter the API query (default is "phones", but it can be changed to "laptops", "monitors", etc.).
Fetch API Response: the method fetchApiResponse() is called to send a POST request to the API and retrieve the response as a JSON string.
Parse JSON Response:
- Gson is used to parse the JSON response into a JsonObject.
- The JSON response is expected to have an array of items under the "Items" key.
Loop Through Items: the for loop iterates over the JSON array of products (items), extracts the title and price of each item, and prints them to the console.
4. Method: fetchApiResponse
private static String fetchApiResponse(String apiUrl, String category) throws Exception {
URI uri = new URI(apiUrl);
URL url = uri.toURL();
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("POST");
connection.setRequestProperty("Content-Type", "application/json");
connection.setDoOutput(true);
// Request body
String jsonInputString = "{\"cat\":\"" + category + "\"}";
try (OutputStream os = connection.getOutputStream()) {
byte[] input = jsonInputString.getBytes(StandardCharsets.UTF_8);
os.write(input, 0, input.length);
}
// Read the response
StringBuilder response = new StringBuilder();
try (Scanner scanner = new Scanner(connection.getInputStream(), StandardCharsets.UTF_8)) {
while (scanner.hasNextLine()) {
response.append(scanner.nextLine());
}
}
return response.toString();
}Explanation of Each Part:
- URI and URL Creation:
The URI and URL objects are created from the provided API URL (apiUrl). This allows the program to establish a connection to the server.
- Opening HTTP Connection:
HttpURLConnection is used to open a connection to the API. The setRequestMethod("POST") method specifies that this is a POST request.
The setRequestProperty("Content-Type", "application/json") ensures the content type of the request is JSON.
setDoOutput(true) enables writing the request body (the JSON data).
- Request Body:
The request body is built as a JSON string: {"cat":"<category>"}, where <category> is the category of the product (e.g., "phone").
getOutputStream() is used to send the JSON string to the server.
- Reading the Response:
The response from the API is read from the connection's input stream using a Scanner.
The response is appended to a StringBuilder object, which is returned as a string.
Here’s the full code:
import com.google.gson.Gson;
import com.google.gson.JsonArray;
import com.google.gson.JsonObject;
import java.io.OutputStream;
import java.net.HttpURLConnection;
import java.net.URI;
import java.net.URL;
import java.nio.charset.StandardCharsets;
import java.util.Scanner;
public class WebScraper {
public static void main(String[] args) {
try {
// API URL
String apiUrl = "https://api.demoblaze.com/bycat";
// Request parameter for product category
String category = "phone"; // Can be changed to "laptop", "monitor", etc.
// Fetch response from API
String jsonResponse = fetchApiResponse(apiUrl, category);
// Parse the JSON response
Gson gson = new Gson();
JsonObject responseObject = gson.fromJson(jsonResponse, JsonObject.class);
JsonArray items = responseObject.getAsJsonArray("Items");
// Output product information
for (int i = 0; i < items.size(); i++) {
JsonObject item = items.get(i).getAsJsonObject();
String title = item.get("title").getAsString();
String price = item.get("price").getAsString();
System.out.println("Product: " + title);
System.out.println("Price: $" + price);
System.out.println("-----------------------");
}
} catch (Exception e) {
System.err.println("An error occurred: " + e.getMessage());
}
}
}
private static String fetchApiResponse(String apiUrl, String category) throws Exception {
URI uri = new URI(apiUrl);
URL url = uri.toURL();
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("POST");
connection.setRequestProperty("Content-Type", "application/json");
connection.setDoOutput(true);
// Request body
String jsonInputString = "{\"cat\":\"" + category + "\"}";
try (OutputStream os = connection.getOutputStream()) {
byte[] input = jsonInputString.getBytes(StandardCharsets.UTF_8);
os.write(input, 0, input.length);
}
// Read the response
StringBuilder response = new StringBuilder();
try (Scanner scanner = new Scanner(connection.getInputStream(), StandardCharsets.UTF_8)) {
while (scanner.hasNextLine()) {
response.append(scanner.nextLine());
}
}
return response.toString();
}
}Output:
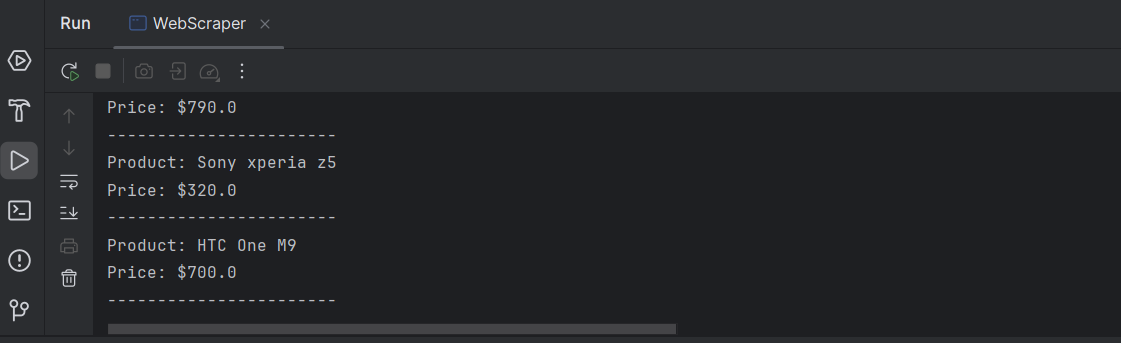
Congratulations! You've successfully extracted the necessary information for each product on the page.
Here's an example of how to scrape data from the website Books to Scrape using Java. We'll use HttpURLConnection to make requests and Jsoup to parse the HTML.
GET Request: The Jsoup.connect(url).get() method sends an HTTP GET request to the specified URL (https://books.toscrape.com/) and returns the page content as a Document.
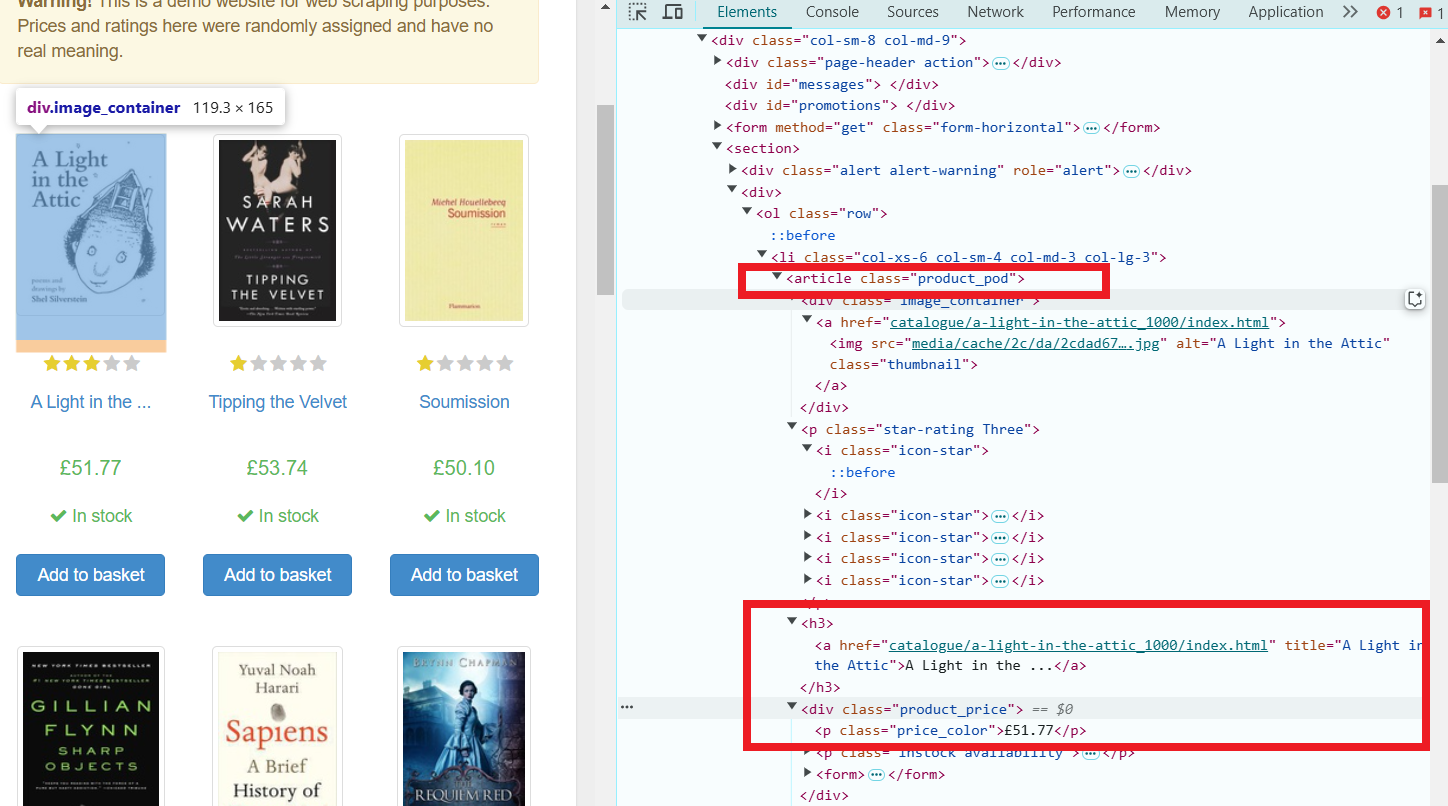
Selecting Elements:
The doc.select(".product_pod") selects all elements with the class product_pod, which are individual books.
book.select("h3 a").attr("title") extracts the title of each book, which is stored in the title attribute of the a tag inside the h3 element.
book.select(".price_color").text() gets the text content (price) from the element with the class price_color.
Displaying the Data: the program then loops through each book, extracting and printing its title and price.
Code Example:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
public class BookScraper {
public static void main(String[] args) {
try {
// URL of the website
String url = "https://books.toscrape.com/";
// Send a GET request to fetch the page
Document doc = Jsoup.connect(url).get();
// Select all book items on the page
Elements books = doc.select(".product_pod");
// Loop through each book element and extract title and price
for (Element book : books) {
String title = book.select("h3 a").attr("title");
String price = book.select(".price_color").text();
System.out.println("Title: " + title);
System.out.println("Price: " + price);
System.out.println("---------------------------");
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
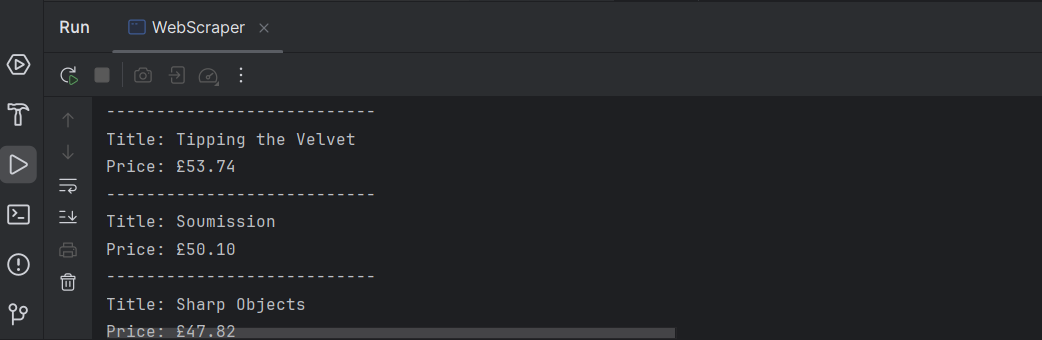
Done! We now have a list of titles and prices for all the books featured on the page.
Web scraping dynamic websites involves interacting with pages that load their content via JavaScript, often using AJAX (Asynchronous JavaScript and XML). Unlike static websites, which provide all their content in the HTML when the page is loaded, dynamic websites fetch and display content dynamically after the page has loaded, meaning you need to handle this extra layer of complexity when scraping. For dynamic web scraping in Java, libraries like Selenium or Playwright are often used, as they allow you to automate the browser and interact with JavaScript-driven pages.
To identify a dynamic website, you can use the DevTools in your browser, which allow you to inspect network requests and responses, see dynamic content loading in real time, and analyze how the data is fetched.
- Open DevTools:
Right-click anywhere on the page and select Inspect, or press Ctrl+Shift+I (Windows/Linux) or Cmd+Option+I (Mac).
- Go to the Network Tab:
Click on the Network tab in the Developer Tools window. This will show all network activity happening as the page loads and after it is loaded.
- Reload the Page:
Refresh the webpage. Observe the Network tab as the page reloads.
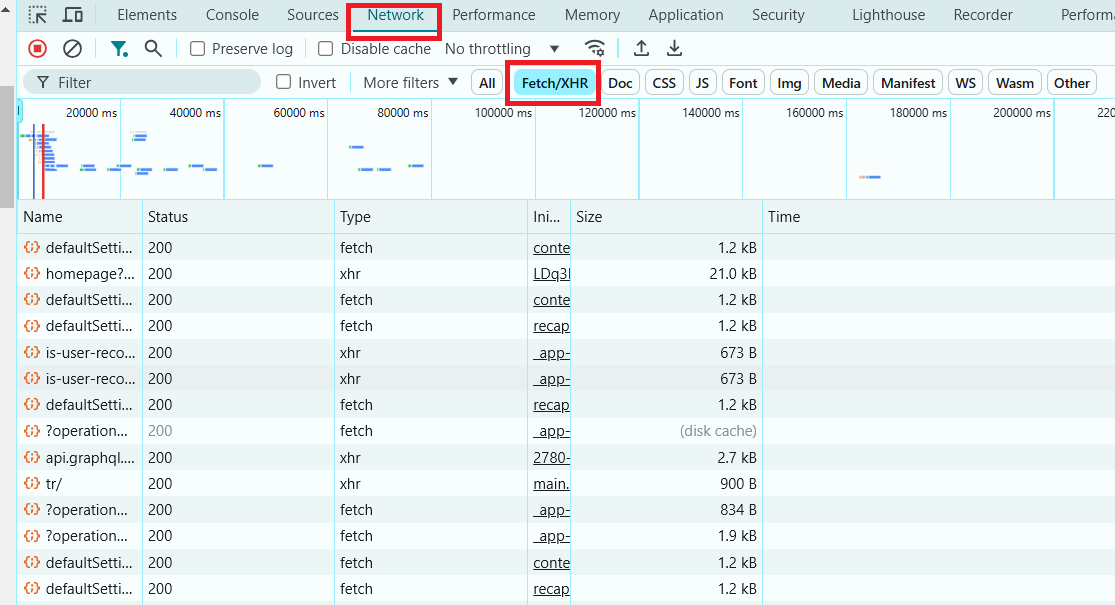
- Filter for XHR (AJAX) Requests:
Look for XHR or Fetch in the filters within the Network tab. These are the requests that fetch data dynamically. If you see these requests fetching JSON, HTML, or other data, it indicates the page is dynamic.
- Check for Content Loaded After Page Load:
Once the page is loaded, check if additional content appears or changes. If you see more content appearing after the initial load without a page refresh, the website is likely using AJAX.
Now that you know how to identify dynamic websites, let's look at how to scrape one.
Let’s walk through an example of how to scrape IMDb’s homepage using Selenium. IMDb is a great example of a dynamic site where the content is loaded asynchronously after the page loads.
To scrape data from a web page using Selenium (docs link), it's essential to correctly identify the elements from which you want to extract information. Let’s locate the necessary elements for data extraction, using the IMDb page:
- Open your browser and visit: https://www.imdb.com/?ref_=nv_home.
- Open DevTools: right-click anywhere on the page and click Inspect, or press Ctrl+Shift+I (Windows/Linux) or Cmd+Option+I (Mac) to open Developer Tools.
- Locate the "Featured Today" Section: right-click on a title or image in the "Featured Today" area and select Inspect. This will highlight the HTML code related to that section.
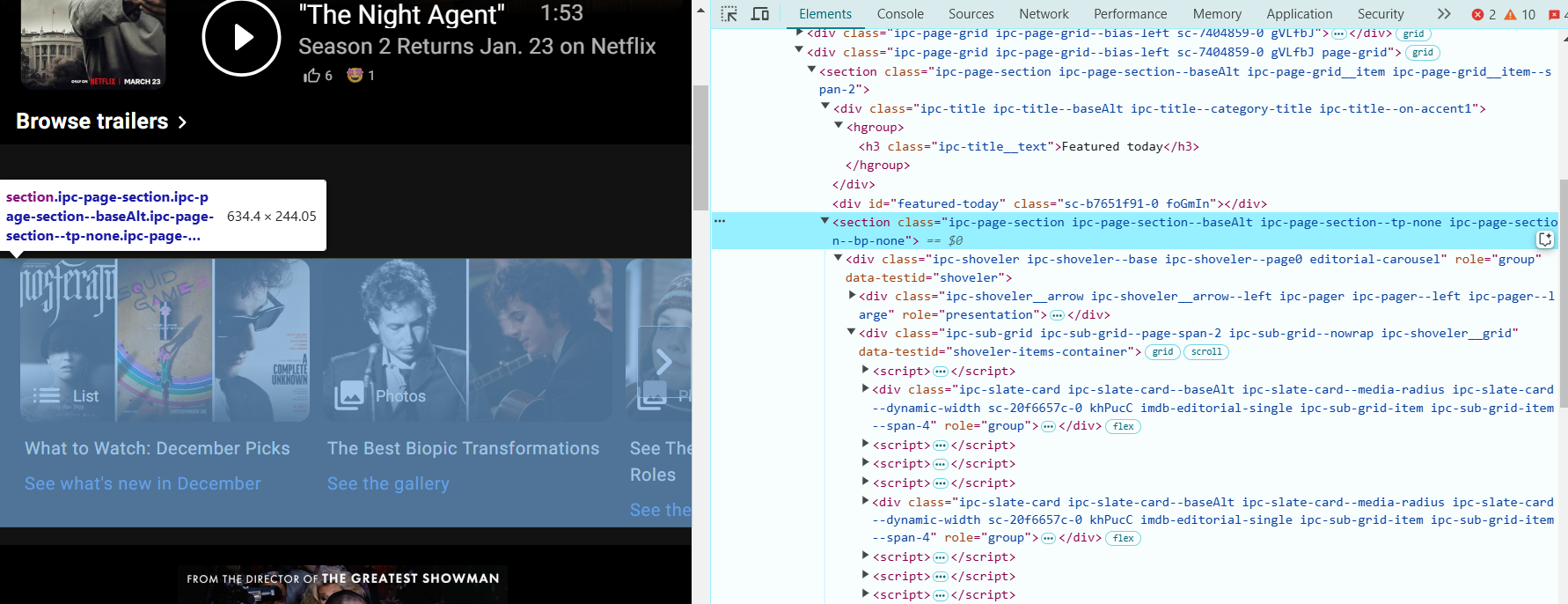
- In DevTools, look at the HTML structure of the page. The "Featured Today" section will have the following HTML:
<section class="ipc-page-section ipc-page-section--baseAlt ipc-page-section--tp-none ipc-page-section--bp-none">
This section contains the movie or show titles that we want to scrape.
- The movie or show titles are inside <div> elements with the class ipc-slate-card__title-text. Look for something like this:
<div class="ipc-slate-card__title-text">Movie Title</div>- Each title is a link wrapped in an <a> tag. The link will look something like this:
<a class="ipc-link" href="https://www.imdb.com/title/tt1234567/">Link</a>- Add the Dependencies to the <dependencies> Section. Copy the dependencies for Selenium Java and Selenium ChromeDriver into the <dependencies> section of your pom.xml file. Here's how it should look:
<dependencies>
<!-- Selenium WebDriver -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>4.27.0</version>
</dependency>
<!-- Selenium ChromeDriver -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-chrome-driver</artifactId>
<version>4.27.0</version>
</dependency>
</dependencies>- Now we can proceed with the code:
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.util.List;
public class WebScraper {
public static void main(String[] args) {
// Create an instance of the driver
WebDriver driver = new ChromeDriver();
try {
// Open the IMDb homepage
driver.get("https://www.imdb.com/?ref_=nv_home");
System.out.println("Featured Today on IMDb:");
// Extract the container of the "Featured Today" section by class
WebElement pageSectionContainer = driver.findElement(By.cssSelector("section.ipc-page-section.ipc-page-section--baseAlt.ipc-page-section--tp-none.ipc-page-section--bp-none"));
// Find the titles in the section
List<WebElement> titles = pageSectionContainer.findElements(By.cssSelector("div.ipc-slate-card__title-text"));
// Extract actions (e.g., links)
List<WebElement> actions = pageSectionContainer.findElements(By.cssSelector("a.ipc-link"));
// Iterate over and print the titles and actions
int count = 0;
for (int i = 0; i < titles.size() && count < 10; i++) {
String title = titles.get(i).getText();
String action = actions.get(i).getAttribute("href");
System.out.printf("%d. %s - Link: %s%n", ++count, title, action);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
driver.quit();
}
}
}
Explanation of the Scraper:
- We initialize the ChromeDriver and open the IMDb homepage.
- We use a CSS selector to find the "Featured Today" section. This is identified by a specific set of classes that are used on the page.
- Once the section is located, we find the individual movie titles and corresponding links using the appropriate CSS selectors (ipc-slate-card__title-text for titles and ipc-link for links).
- We loop through the list of titles and links and print the first 10 featured items.
There are several ways to save data from web scraping, including:
Text files (TXT) — for simple storage of data in plain text format.
CSV files — for storing data in a table format, easy to analyze and process in Excel or other analytics tools.
Databases — for more complex projects with large amounts of data (e.g., MySQL, SQLite).
JSON or XML — for structured data, ideal for exchanging data between applications.
In our example, text files or CSV would be the best options. This is because the data consists of simple text strings and links, which are easy to organize into a table for later analysis, especially when there is not much data. The CSV format is particularly useful for storing data in a table with multiple columns (e.g., title and link).
Saving to a Text File:
To save the data to a simple text file, you can use the FileWriter and BufferedWriter classes:
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
import java.util.List;
public class WebScraper {
public static void main(String[] args) {
// Create an instance of the driver
WebDriver driver = new ChromeDriver();
try {
// Open the IMDb homepage
driver.get("https://www.imdb.com/?ref_=nv_home");
System.out.println("Featured Today on IMDb:");
// Extract the container of the "Featured Today" section by class
WebElement pageSectionContainer = driver.findElement(By.cssSelector("section.ipc-page-section.ipc-page-section--baseAlt.ipc-page-section--tp-none.ipc-page-section--bp-none"));
// Find the titles in the section
List<WebElement> titles = pageSectionContainer.findElements(By.cssSelector("div.ipc-slate-card__title-text"));
// Extract actions (e.g., links)
List<WebElement> actions = pageSectionContainer.findElements(By.cssSelector("a.ipc-link"));
// Create a FileWriter to save data to a file
BufferedWriter writer = new BufferedWriter(new FileWriter("featured_today_imdb.txt"));
writer.write("Featured Today on IMDb:\n");
writer.write("--------------------------------\n");
// Iterate over and save the titles and actions to the text file
int count = 0;
for (int i = 0; i < titles.size() && count < 10; i++) {
String title = titles.get(i).getText();
String action = actions.get(i).getAttribute("href");
writer.write(String.format("%d. %s - Link: %s%n", ++count, title, action));
}
writer.close(); // Don't forget to close the writer!
} catch (Exception e) {
e.printStackTrace();
} finally {
driver.quit();
}
}
}Saving to a CSV File:
If you prefer saving the data in CSV format, you can use the following code, which writes the data as comma-separated values:
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.io.FileWriter;
import java.io.IOException;
import java.util.List;
public class WebScraper {
public static void main(String[] args) {
// Create an instance of the driver
WebDriver driver = new ChromeDriver();
try {
// Open the IMDb homepage
driver.get("https://www.imdb.com/?ref_=nv_home");
System.out.println("Featured Today on IMDb:");
// Extract the container of the "Featured Today" section by class
WebElement pageSectionContainer = driver.findElement(By.cssSelector("section.ipc-page-section.ipc-page-section--baseAlt.ipc-page-section--tp-none.ipc-page-section--bp-none"));
// Find the titles in the section
List<WebElement> titles = pageSectionContainer.findElements(By.cssSelector("div.ipc-slate-card__title-text"));
// Extract actions (e.g., links)
List<WebElement> actions = pageSectionContainer.findElements(By.cssSelector("a.ipc-link"));
// Create a FileWriter to save data to a CSV file
FileWriter writer = new FileWriter("featured_today_imdb.csv");
writer.append("Title, Link\n");
// Iterate over and save the titles and actions to the CSV file
int count = 0;
for (int i = 0; i < titles.size() && count < 10; i++) {
String title = titles.get(i).getText();
String action = actions.get(i).getAttribute("href");
writer.append(String.format("\"%s\", \"%s\"\n", title, action));
count++;
}
writer.flush(); // Ensure everything is written to the file
writer.close(); // Close the writer
} catch (Exception e) {
e.printStackTrace();
} finally {
driver.quit();
}
}
}
Now you can save the extracted data from IMDb in either a text file or CSV file, making it easier to analyze or share!
When engaging in web scraping, it's crucial to ensure that the process is secure for both the scraper and the target website. Here are some security best practices:
- Avoid overloading a website with requests from a single IP address. Use proxies to rotate IP addresses and distribute the load.
- Some websites have measures like CAPTCHA or other anti-scraping techniques. It's essential to handle these effectively, possibly with tools like CapMonster Cloud for CAPTCHA solving.
- To avoid being flagged as a bot, throttle your requests by adding delays between them. This mimics human browsing behavior and prevents overwhelming the server.
- Change the User-Agent string in your scraper to simulate different browsers. This helps prevent detection.
- Be careful not to store sensitive user data (such as passwords) from the scraping process. Follow data protection laws, like GDPR, when applicable.
- And finally, always check the website's Terms of Service (TOS) and ensure that scraping is allowed. Ignoring this could lead to legal consequences.
To speed up your web scraping process and make it more efficient, consider these tips:
- Use headless browsers like Chrome or Firefox in non-GUI mode to speed up scraping. This removes the overhead of rendering the user interface.
Example: use ChromeOptions in Selenium to run in headless mode
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless");
WebDriver driver = new ChromeDriver(options);
- Cache data wherever possible to avoid re-requesting the same information multiple times. If you're working with large datasets, storing the results in a local database can be more efficient.
- Use more efficient XPath and CSS selectors to minimize DOM traversal. Avoid overly generic selectors that may result in unnecessary checks. For example, instead of using findElement(By.xpath("//div[@class='example']/a"), use a more specific path if possible.
- If the page does not require JavaScript to render content, avoid using tools like Selenium and opt for faster libraries like Jsoup, which parse HTML directly.
- Parallel Processing. Use multiple threads or processes to scrape multiple pages simultaneously. This can drastically reduce the time taken to scrape a large number of pages.
Tools: consider using libraries like ExecutorService in Java for multi-threading.
Here's an example of parallelism in Java for web scraping using the java.util.concurrent library, which provides tools for multithreaded programming.
import java.io.IOException;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class ParallelWebScraping {
// Method to scrape the content of a page
public static String scrapePage(String url) throws IOException {
System.out.println("Scraping URL: " + url + " in thread: " + Thread.currentThread().getName());
Document doc = Jsoup.connect(url).get();
return doc.title(); // Returning the page title as an example
}
public static void main(String[] args) {
// List of URLs to scrape
List<String> urls = Arrays.asList(
"https://example.com",
"https://example.org",
"https://example.net"
);
// Create a fixed thread pool
ExecutorService executorService = Executors.newFixedThreadPool(3);
try {
// Create tasks for parallel execution
List<Callable<String>> tasks = urls.stream()
.map(url -> (Callable<String>) () -> scrapePage(url))
.toList();
// Execute tasks and collect results
List<Future<String>> results = executorService.invokeAll(tasks);
// Print the results
for (Future<String> result : results) {
System.out.println("Page title: " + result.get());
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// Shutdown the thread pool
executorService.shutdown();
}
}
}
- We define a list of URLs to scrape.
- A fixed thread pool is created to limit the number of threads running simultaneously.
- Each Callable represents a task that returns a result after execution (in this case, the page title).
- The invokeAll method executes all tasks in parallel and returns a list of Future objects that contain the results.
- The Jsoup library is used to fetch and parse web pages.
- Extract page titles (or other data) from the Future objects.
Java is an excellent choice for web scraping, offering powerful tools and libraries for data extraction. In this article, we discussed key approaches, including static and dynamic scraping, working with APIs, and shared useful tips for more efficient data retrieval.
With tools like CapMonster Cloud for bypassing CAPTCHAs, Java allows you to tackle even the most challenging tasks. Experiment, expand your skills, and explore new ways to automate. The world of data is waiting for you to uncover it!
1. What is web scraping and how does it work?
Web scraping is the process of automatically extracting data from web pages. It involves using software to retrieve the HTML code of a page, extract the required information, and then process or save it.
2. What are the best tools for web scraping in Java?
Popular tools for web scraping in Java include:
Jsoup — for parsing HTML.
Selenium — for browser automation, especially for dynamic websites.
HtmlUnit — a lightweight browser for automation.
3. How do I bypass scraping protection (like CAPTCHA)?
To bypass CAPTCHAs, you can use services like CapMonster Cloud, which automatically solve CAPTCHAs for your script, allowing you to continue scraping without delays.
4. Can I use web scraping on all websites?
Not all websites allow web scraping. Before starting, you should check the terms of service of the website to ensure that scraping is permitted. Many websites use protections like CAPTCHA or IP blocking to prevent scraping.
5. What types of data can I extract with web scraping?
You can extract various types of data, such as:
Text (e.g., headings, descriptions).
Product prices.
User data.
News content.
Structured data, such as tables and lists.
6. How do I handle dynamic content on websites?
For dynamic content that is loaded via JavaScript, you can use tools like Selenium, which simulate user actions in a browser and allow you to extract data from dynamically generated pages.
7. How can I speed up the scraping process?
- Use multithreading and parallel requests to speed up data collection.
- Limit the request frequency to avoid being blocked.
- Use proxy servers to distribute the load.
8. What should I do if the website blocks my requests?
If the website blocks your requests, you can:
- Use proxies to change your IP address.
- Add delays between requests.
- Change your user agent to mimic real browsers.
- Use fingerprints to emulate real browser sessions. Fingerprinting involves altering request headers and other session data (like cookies, referers, and accept-languages) to make your requests appear more like those from an actual user.
- Use CAPTCHA solving services.